Rename year directories to allow natural ordering
This commit is contained in:
@ -0,0 +1,38 @@
|
||||
- #[[CT2106 - Object-Oriented Programming]]
|
||||
- **Previous Topic:** [[Coding Up Inheritance]]
|
||||
- **Next Topic:** [[Interfaces]]
|
||||
- **Relevant Slides:**  
|
||||
-
|
||||
- Why use an abstract class?
|
||||
- You should use an abstract class in situations where you want to use inheritance but do not want another developer to create an object from the superclass.
|
||||
-
|
||||
- # Abstract Methods
|
||||
- Abstract classes can also have **abstract methods**.
|
||||
- Abstract methods are methods with no body.
|
||||
- ```java
|
||||
public abstract void sing();
|
||||
```
|
||||
- In other words, they do nothing.
|
||||
- Abstract methods provide the definition of a method that at least one of its subclasses must implement.
|
||||
-
|
||||
- # Concrete
|
||||
- The adjective **concrete** is often used in OOP to denote a class or method that is **not abstract**.
|
||||
- i.e., the class or method is fully implemented.
|
||||
-
|
||||
- # Reference Type
|
||||
- An abstract class is often used as the type of a reference variable.
|
||||
- ```java
|
||||
Animal animal = new Canary("bruh");
|
||||
```
|
||||
-
|
||||
- # Polymorphism
|
||||
- What is **polymorphism**? #card
|
||||
card-last-interval:: 3.45
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-18T06:09:31.768Z
|
||||
card-last-reviewed:: 2022-11-14T20:09:31.768Z
|
||||
card-last-score:: 5
|
||||
- **Polymorphism** refers to how an object can be treated as belonging to several types as long as those types are **higher** than the object's type in the class hierarchy.
|
||||
- In general, a variable of type $X$ can point to any object that has an "is-a" relationship to type $X$.
|
||||
- e.g., a variable of type `Animal` can point to a `Bird`, `Frog`, or `Fish` object.
|
||||
@ -0,0 +1,142 @@
|
||||
- #[[MA284 - Discrete Mathematics]]
|
||||
- **Previous Topic:** [[Stars & Bars]]
|
||||
- **Next Topic:** [[Introduction to Graph Theory]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Advanced Counting Using PIE
|
||||
collapsed:: true
|
||||
- The PIE works for larger number of sets than 2 and 3, although it gets a little messy to write down.
|
||||
- For 4 sets, we can think of it as:
|
||||
- $|A \cup B \cup C \cup D| =$ (the sum of the sizes of each single set) $-$ (the sum of the sizes of each **intersection** of 2 sets) $+$ (the sum of the sizes of each **intersection** of 3 sets) $-$ (the sum of the sizes of the **intersection** of all 4 sets).
|
||||
- ## Example
|
||||
- How many ways can we distribute 10 slices of pie to 4 kids that such that no kid gets more than 2 slices (and each slice is distributed)? [See [the textbook](https://discrete.openmathbooks.org/dmoi3/sec_advPIE.html) for a more detailed solution.]
|
||||
- The answer is obviously 0 - there will be 2 slices leftover after each kid gets the maximum of 2 slices.
|
||||
- Without the restriction that nobody gets more than 2 slices, there would be $\binom{13}{3} = 286$ ways of sharing distributing the slices ($10+4-1$ stars & $4-1$ bars).
|
||||
- Now, count the number of ways where a child gets more than 2 slices, i.e. some child gets $\geq 3$ slices.
|
||||
- $$\binom{4}{1} \binom{7+3}{3} = 4(120) = 480$$
|
||||
- (choose one of 4 kids)(number of ways of distributing).
|
||||
- Add back in the doubly counted ones, subtracted the triply counted,
|
||||
-
|
||||
- $$\binom{13}{3} - \binom{4}{1} \binom{10}{3} + \binom{4}{2} \binom{7}{3} - \binom{4}{3} \binom{4}{3} + \binom{4}{4} \binom{1}{3} \\ = 286 - 480 +210 -16 = 0$$
|
||||
- ## Example
|
||||
- Not all problems have such easy solutions.
|
||||
- How many non-negative integer solutions are there to $x_1 + x_2 + x_3 +x_4 +x_5 = 13$ if:
|
||||
- 1. There are no restrictions (other than $x_i$ being an **nni**).
|
||||
2. $0\leq x_i \leq 3$ for each $i$.
|
||||
- 1. $$\displaystyle \binom{13+4}{4} = \binom{17}{4}$$
|
||||
- 2. Idea: All possibilities $-$ "the wrong ones", i.e., count the possibilities where at least one of the $x_i \geq 4$.
|
||||
- $\binom{5}{1}$ ways pf choosing the $x_i$ and then number of solutions to $x_1+x_2+x_3+x_4+x_5 = 9$ is $\binom{9+4}{4} = \binom{13}{4}$, i.e. $\binom{5}{1} \binom{13}{4}$.
|
||||
- But we have double counted, so number of solutions with two $x_i \ geq 4$ is $\binom{5}{2}$ choices and $x_1+x_2+x_3+x_4+x_5 = 5$ has $\binom{5+4}{4} = \binom{9}{4}$ solutions.
|
||||
- Answer: $\displaystyle \binom{17}{4} - \binom{5}{1} \binom{13}{4} + \binom{5}{2}\binom{9}{4} - \binom{5}{3}\binom{5}{4} +0$.
|
||||
-
|
||||
- # Derangements
|
||||
- What is a **derangement**? #card
|
||||
card-last-interval:: 3.45
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-20T19:47:44.301Z
|
||||
card-last-reviewed:: 2022-11-17T09:47:44.301Z
|
||||
card-last-score:: 5
|
||||
- A **derangement** is a permutation where no element is left in its original place, everything is moved.
|
||||
- ## Example - Derangements of 4 Letters $\text{STARS}$.
|
||||
- Let $D_n$ be the number of *derangements* of $n$ objects.
|
||||
- First, we will work out the formulae for $D_1$, $D_2$, $D_3$, & $D_4$.
|
||||
- $$D_1 = 0,\ D_2 = 1,\ D_3 = 2,\ D_4 = 9$$
|
||||
- We derive a formula using PIE.
|
||||
- We know that there are $4!$ permutations. Which ones are **not** derangements?
|
||||
- Suppose that one item (at least) is left in place.
|
||||
- There are $$\displaystyle \binom{4}{1} \cdot 3!$$ such permutations.
|
||||
- (choose one item to not change from four)(number of ways of permutating the other items).
|
||||
- However, some of these will be counted twice.
|
||||
- So, by PIE, the answer is
|
||||
- $$D_4 = 4! - \binom{4}{1}3! + \binom{4}{2}2!-\binom{4}{3}1!+\binom{4}{4}0!$$
|
||||
- $$D_4 = 4! - \frac{4!3!}{1!3!} +\frac{4!2!}{2!2!}-\frac{4!1!}{3!1!} + \frac{4!0!}{4!0!}$$
|
||||
- $$D_4 = 4![1-\frac{1}{1!}+\frac{1}{2!}-\frac{1}{3!}+\frac{1}{4!}] = 9$$
|
||||
- In general, the formula for $D_n$, the number of derangements of $n$ objects is
|
||||
- $$D_n = n!(1-\frac{1}{1!}+\frac{1}{2!}-\frac{1}{3!}+ \dots + (-1)^n \frac{1}{n!})$$
|
||||
- Note that the series expansion for e^x is
|
||||
- $$e^x = 1 + \frac{x}{1!} +\frac{x^2}{2!}+\frac{x^3}{3!} + \dots$$
|
||||
- So $$\displaystyle e^{-1} = 1 - \frac{1}{1!} + \frac{1}{2!}-\frac{1}{3!}+ \dots$$
|
||||
- So $$\displaystyle \lim_{n \to \infty} \frac{D_n}{n!} = e^{-1} \approx 0.36787$$
|
||||
- # Counting with Repetitions
|
||||
- What is a **Multinomial Coefficient**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:07:58.830Z
|
||||
card-last-score:: 1
|
||||
- The number of different permutations of $n$ objects, where there are $n_1$ indistinguishable objects of Type 1, $n_2$ indistinguishable objects of Type 2, ..., and $n_k$ indistinguishable objects of Type $k$, is
|
||||
- $$\frac{n!}{(n_1!)(n_2!) \dots (n_k!)}$$
|
||||
- ## Example
|
||||
- How many "words" can we make from the letters in the set $\{R,O,S,C,O,M,M,O,N\}$.
|
||||
- If somehow the three $O$s were all distinguishable, and the two $M$s were distinguishable, the answer would be $9!$.
|
||||
- But, since we can't distinguish the identical letters,
|
||||
- Let's choose which of the 9 positions in which we place the three $O$s.
|
||||
- This can be done in $$\displaystyle \binom{9}{3}$$ ways.
|
||||
- Now, let's choose which of the remaining 6 positions in which we place the two $M$s.
|
||||
- This can be done in $$\displaystyle \binom{6}{2}$$ ways.
|
||||
- Finally, let's choose where to replace the remaining 4 letters.
|
||||
- This can be done in $$4!$$ ways.
|
||||
- By the Multiplicative Principle, the answer is
|
||||
- $$\binom{9}{3}\binom{6}{2}4! = \frac{9!}{3!6!} \frac{6!}{2!}{4!} 4! = \frac{9!}{3!2!}$$
|
||||
- # Example (MA284 Semester 1 Exam, 2014/2015)
|
||||
- **(i) Find the number of different arrangements of the letters in the place name `WOLLONGONG`.**
|
||||
- `OOOLLNNGGW`
|
||||
- $$\frac{10!}{3!2!2!2!1!} = 75600$$
|
||||
- **(ii) How many of these arrangements start with three `O`s?**
|
||||
- `OOO` (one way) and 7 others.
|
||||
- $$\frac{7!}{2!2!2!} = 630$$
|
||||
- **(ii) How many contain the two `G`s consecutively?**
|
||||
- Treat `GG` as a single letter and permute 9 letters.
|
||||
- $$\frac{9!}{3!2!2!1!} = 15120$$
|
||||
- **(iv) How many *do not* contain the two `G`s consecutively?**
|
||||
- Use **(i)** - **(iv)**.
|
||||
- $$75600 - 15120 = 60480$$
|
||||
- # Counting Functions
|
||||
- Recall that $f: A \rightarrow B$ is a **function** that maps every element of the set $A$ onto some element of set $B$.
|
||||
- We call $A$ the **domain** & $B$ the **codomain**.
|
||||
- Each element of $A$ gets mapped to exactly one element of $B$.
|
||||
- What does it mean if $a$ is the **image** of $b$? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-23T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-22T13:40:10.499Z
|
||||
card-last-score:: 1
|
||||
- If $f(a) = b$ where $a \in A$ and $b \in B$, we say that "the **image** of $a$ is $b$", or, equivalently, "$b$ is the **image** of $a$".
|
||||
- What is a **surjective** function (surjection)? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:13:44.812Z
|
||||
card-last-score:: 1
|
||||
- For some function $f: A \rightarrow B$, if every element of $B$ is the image of some element $A$, we say that the function is **surjective** (also called "**onto**").
|
||||
- What is an **injective** function (injection)? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:16:06.397Z
|
||||
card-last-score:: 1
|
||||
- For some function $f: A \rightarrow B$, if no two elements of $A$ have the same image in $B$, we say that the function is **injective** (also called "one-to-one").
|
||||
- What is a **bijective** function (bijection)? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-18T20:09:58.766Z
|
||||
card-last-reviewed:: 2022-11-14T20:09:58.766Z
|
||||
card-last-score:: 5
|
||||
- The function $f: A \rightarrow B$ is a **bijection** if it is both **surjective** & **injective**.
|
||||
- Then $f$ defines a **one-to-one correspondence** between $A$ & $B$
|
||||
- ## Examples
|
||||
- **Let** $A$ **&** $B$ **be finite sets. How many functions** $f: A \rightarrow B$ **are there?**
|
||||
- We can use ((6336be87-7dea-4ba3-b7d0-c77a73bae948)) to deduce that there are in total $|B|^{|A|}$ functions from $A$ to $B$.
|
||||
- **How many functions** $f: A\{1,2,3,4,5,6,7,8\} \rightarrow \{1,2,3,4,5,6,7,8\}$ **are bijective**?
|
||||
- Remember what it means for a function to be **bijective:** ^^each element in the codomain must be the image of **exactly one** element of the domain.^^
|
||||
- What we are really doing is just rearranging the elements of the codomain, so we are defining a **permutation** of 8 elements.
|
||||
- Therefore, the answer to our question is 8!.
|
||||
- More generally, there are $n!$ bijections of the set $\{1,2,\cdots, n\}$ onto itself.
|
||||
- [[2022年10月19日]]
|
||||
-
|
||||
@ -0,0 +1,55 @@
|
||||
- #[[CT230 - Database Systems I]]
|
||||
- **Previous Topic:** [[SQL SELECT: Working with Strings & Subqueries]]
|
||||
- **Next Topic:** [[Entity Relationship Models]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Aggregate Functions #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:29:15.913Z
|
||||
card-last-score:: 1
|
||||
- **Aggregate Functions** are only supported in `SELECT` clauses & `HAVING` clauses.
|
||||
- Keywords `SUM`, `AVG`, `MIN`, `MAX` work as expected and can only be applied to **numeric** data.
|
||||
- Keyword `COUNT` can be used to count the number of tuples / values / rows specified in a query.
|
||||
- We can also use mathematical operations as part of an aggregate function on **numeric** data, e.g., `+`, `-`, `*`, `/`.
|
||||
- # `GROUP BY` #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-11-27T12:18:53.349Z
|
||||
card-last-reviewed:: 2022-11-23T12:18:53.350Z
|
||||
card-last-score:: 3
|
||||
- `GROUP BY <group attributes>`
|
||||
- The `GROUP BY` clause allows the grouping of rows of a table together so that all occurrences within a specified group are collected together.
|
||||
- Aggregate clauses can then be applied to groups.
|
||||
- ## Using Aggregate Functions with `GROUP BY` #card
|
||||
card-last-interval:: 4.14
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-27T15:17:10.883Z
|
||||
card-last-reviewed:: 2022-11-23T12:17:10.883Z
|
||||
card-last-score:: 5
|
||||
- The `GROUP BY` clause specifies the group and the aggregate function is applied to the group.
|
||||
- `COUNT(*)` can be used to *count* the number of rows (tuples) in the specified groups.
|
||||
- `SUM`, `AVG`, `MIN`, `MAX` can be used to find the sum, average, min, & max of a *numerical value* in a specified group.
|
||||
- ^^**Important:** You must `GROUP BY` **all** attributes in the `SELECT` clause *unless* they are involved in an aggregation.^^
|
||||
- This **^^wouldn't work^^** as we do not `GROUP BY` all the attributes in the `SELECT` clause - `salary` remains ungrouped.
|
||||
- ```SQL
|
||||
SELECT dno, salary
|
||||
FROM employee
|
||||
GROUP BY dno -- THIS IS WRONG
|
||||
```
|
||||
-
|
||||
- # `HAVING` #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T20:18:23.927Z
|
||||
card-last-score:: 1
|
||||
- `HAVING <group condition>`
|
||||
- The `HAVING` clause is used in conjunction with `GROUP BY` and allows the specification of **conditions on groups**.
|
||||
- The column names in the `HAVING` clause must also appear in the `GROUP BY` list or be contained within an aggregate function, i.e., you cannot apply a `HAVING` condition to something that has not been calculated already.
|
||||
-
|
||||
@ -0,0 +1,43 @@
|
||||
- #[[CT216 - Software Engineering I]]
|
||||
- **Previous Topic:** [[Introduction to Agile Methods]]
|
||||
- **Next Topic:** [[Bootstrap CSS]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # XP
|
||||
- **eXtreme Programming (XP)** is one of the most popular agile software development methods.
|
||||
- Some characteristics of XP include:
|
||||
- Pair programming.
|
||||
- Refactoring.
|
||||
- Test-Driven Development (TDD).
|
||||
- Continuous Integration.
|
||||
- Metaphor.
|
||||
- Small releases.
|
||||
- Simple design.
|
||||
- Customer tests.
|
||||
- ## Principles of XP #card
|
||||
card-last-interval:: 21.53
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-12-08T21:47:52.136Z
|
||||
card-last-reviewed:: 2022-11-17T09:47:52.136Z
|
||||
card-last-score:: 5
|
||||
- Communication.
|
||||
- Simplicity.
|
||||
- Feedback.
|
||||
- Courage.
|
||||
- Respect.
|
||||
- All the contributors to an XP project (members of one team) sit together. This team must include a business representative (Product Owner) - the "Customer" - who provides the requirements, sets the priorities, and steers the project.
|
||||
- ## Planning
|
||||
- XP planning addresses two key questions in software development: predicting what will be accomplished by the due date, and determining what to do next.
|
||||
- **Release Planning** is a practice where the Customer presents the desired features to the programmers, and the programmers estimate their difficulty.
|
||||
- **Iteration Planning** is the practice whereby the team is given direction every few weeks (Sprints).
|
||||
- ## Customer Tests
|
||||
- As part of presenting each desired feature, the XP Customer defines one or more automated acceptance tests to show that the feature is working.
|
||||
- The team builds these tests and uses them to prove to themselves, and to the customer, that the feature is implemented correctly.
|
||||
- ## Small Releases
|
||||
- XP teams practice small releases in two important ways:
|
||||
- First, the team releases running, tested software, delivering business value chosen by the Customer, every iteration.
|
||||
- Second, XP teams release to their end users frequently as well.
|
||||
- ## Coding Standards
|
||||
- XP teams follow a common coding standard, so that all the code
|
||||
-
|
||||
154
year2/semester1/logseq-stuff/pages/Binomial Coefficients.md
Normal file
154
year2/semester1/logseq-stuff/pages/Binomial Coefficients.md
Normal file
@ -0,0 +1,154 @@
|
||||
- #[[MA284 - Discrete Mathematics]]
|
||||
- **Previous Topic:** [[Principle of Inclusion-Exclusion]]
|
||||
- **Next Topic:** [[Combinatorial Proofs]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Binary Strings & Lattice Paths
|
||||
- ## Binary Strings
|
||||
- A **bit** is a "binary digit", e.g., 1 or 0.
|
||||
- A **bit string** is a string (list) of bits, e.g., 1011010.
|
||||
- What is the **length** of a string? #card
|
||||
card-last-interval:: 31.36
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-12-16T04:06:32.399Z
|
||||
card-last-reviewed:: 2022-11-14T20:06:32.399Z
|
||||
card-last-score:: 5
|
||||
- The **length** of the string is the number of bits.
|
||||
- An $n$-bit string has length $n$.
|
||||
- The set of all $n$-bit strings (for given $n$) is denoted $B^n$.
|
||||
- What is the **weight** of a string? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-21T00:50:01.239Z
|
||||
card-last-reviewed:: 2022-11-17T09:50:01.240Z
|
||||
card-last-score:: 5
|
||||
- The **weight** of the string is the number of 1s.
|
||||
- The set of all $n$-bit strings of weight $k$ is denoted $B^n_k$.
|
||||
- ## Lattice Paths
|
||||
- What is a **lattice**? #card
|
||||
card-last-interval:: 19.01
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-03T20:05:46.936Z
|
||||
card-last-reviewed:: 2022-11-14T20:05:46.936Z
|
||||
card-last-score:: 3
|
||||
- The (integer) **lattice** is the set of all points in the Cartesian plane for which both the $x$ & $y$ coordinates are integers.
|
||||
- What is a **lattice path**? #card
|
||||
card-last-interval:: 31.36
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-12-16T04:11:02.220Z
|
||||
card-last-reviewed:: 2022-11-14T20:11:02.220Z
|
||||
card-last-score:: 5
|
||||
- A **lattice path** is the ^^shortest possible path^^ connecting two points on the lattice, moving only horizontally & vertically.
|
||||
- There can be multiple lattice paths, so long as they are of equally short length.
|
||||
- 
|
||||
- The number of lattice paths from $(0,0)$ to $(3,2)$ is the same as $|B_3^5|$.
|
||||
- The number of lattice paths from $(0,0)$ to $(3,2)$ is the same as the number from $(0,0)$ to $(2,2)$, plus the number from $(0,0)$ to $(3,1)$.
|
||||
-
|
||||
- # Binomial Coefficients
|
||||
- What is the coefficient of say, $x^3y^2$ in $(x+y)^5$?
|
||||
- $$(x+y)^0=1
|
||||
\newline
|
||||
(x+y)^1=x+y
|
||||
\newline
|
||||
(x+y)^2=x^2+2xy+y^2
|
||||
\newline
|
||||
(x+y)^3=x^3+3x^2y+3xy^2+y^3
|
||||
\newline
|
||||
(x+y)^4=x^4+4x^3y+6x^2y^2+4xy^3+y^4
|
||||
\newline
|
||||
(x+y)^5=x^5+5x^4y+10x^3y^2+10x^2y^3+5xy^4+y^5
|
||||
$$
|
||||
- So, by doing a lot of multiplication, we have worked out that the coefficient of $x^3y^2$ is $10$.
|
||||
- But, there is a more systematic way of answering this problem.
|
||||
-
|
||||
- $$(x+y)^5=(x+y)(x+y)(x+y)(x+y)(x+y)$$
|
||||
- We can work out the coefficient of $x^3y^2$ in the expansion of $(x+y)^5$ by counting the number of ways we can **choose** $3$ $x$s & $2$ $y$s in
|
||||
- $$(x+y)(x+y)(x+y)(x+y)(x+y)$$
|
||||
-
|
||||
- The numbers that occurred in all of our examples are called **binomial coefficients**, and are denoted
|
||||
- $$\binom{n}{k}$$
|
||||
- What are **Binomial Coefficients**? #card
|
||||
card-last-interval:: 9.88
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-11-24T13:42:42.079Z
|
||||
card-last-reviewed:: 2022-11-14T16:42:42.079Z
|
||||
card-last-score:: 3
|
||||
- For each integer $n \geq 0$, and integer $k$ such that $0 \leq k \leq n$, there is a number $\binom{n}{k}$, read as "$n$ *choose* $k$".
|
||||
- $\binom{n}{k} = |B^n_k|$, the number of $n$-bit strings of weight $k$.
|
||||
- $\binom{n}{k}$ is the number of subsets of a set of size $n$, each with cardinality $k$.
|
||||
- $\binom{n}{k}$ is the number of lattice paths of length $n$ containing $k$ steps to the right.
|
||||
- $\binom{n}{k}$ is the coefficient of $x^k y^{n-k}$ in the expansion of $(x+y)^n$.
|
||||
- $\binom{n}{k}$ is the number of ways to select $k$ objects from a total of $n$ objects.
|
||||
- If we were to skip ahead, we would learn that there is a formula for $\binom{n}{k}$ (that is, "$n$ choose $k$") that is expressed in terms of **factorials**.
|
||||
- Recall that the **factorial** of a natural number $n$ is:
|
||||
- $$n! = n \times (n-1) \times (n-2) \times (n-4) \times ... \times 2 \times 1$$
|
||||
- We will eventually learn that
|
||||
- $$\binom{n}{k} = \frac{n!}{k!(n-k)!}$$
|
||||
- However, the formula $\displaystyle \binom{n}{k} = \frac{n!}{k!(n-k)!}$ is not very useful in practice.
|
||||
-
|
||||
-
|
||||
- # Pascal's Triangle
|
||||
- 
|
||||
- Earlier, we learned that if the set of all $n$-bit strings with weight $k$ is written $B^n_k$, then
|
||||
- $$|b^n_k| = |B^{n-1}_{k-1}| + |B^{n-1}_k$$
|
||||
- Similarly, we find that:
|
||||
- #### Pascal's Identity: A recurrence relation for $\binom{n}{k}$ #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T09:47:25.425Z
|
||||
card-last-score:: 1
|
||||
- $$\binom{n}{k} = \binom{n-1}{k-1} + \binom{n-1}{k}$$
|
||||
- This is often presented as **Pascal's Triangle**
|
||||
- 
|
||||
-
|
||||
-
|
||||
- # Permutations
|
||||
- What is a **permutation**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-21T00:50:12.451Z
|
||||
card-last-reviewed:: 2022-11-17T09:50:12.452Z
|
||||
card-last-score:: 5
|
||||
- A **permutation** is an arrangement of objects. Changing the order of the objects gives a different permutation.
|
||||
- A permutation of a set must have the same cardinality as that set.
|
||||
- Important: order matters!
|
||||
- ### Number of Permutations
|
||||
- How many **permutations** are there of $n$ objects? #card
|
||||
card-last-interval:: 31.36
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-12-16T04:21:54.886Z
|
||||
card-last-reviewed:: 2022-11-14T20:21:54.886Z
|
||||
card-last-score:: 5
|
||||
- There are $n!$ (i.e., $n$ *factorial*) permutations of $n$ (distinct) objects.
|
||||
- How many permutations are there of $k$ objects from $n$? #card
|
||||
card-last-interval:: 31.36
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-12-16T04:10:57.897Z
|
||||
card-last-reviewed:: 2022-11-14T20:10:57.897Z
|
||||
card-last-score:: 5
|
||||
- The number of permutations of $k$ objects out of $n$, $P(n,k)$ is
|
||||
- $$P(n,k) = \binom{n}{k} = n \times (n-1) \times ... \times (n - k + 1) = \frac{n!}{(n-k)!}$$
|
||||
- ## The Binomial Coefficient Formula
|
||||
- (1) We know that there are $P(n,k)$ permutations of $k$ objects out of $n$.
|
||||
- (2) We know that
|
||||
- $$P(n,k) = \frac{n!}{(n-k)!}$$
|
||||
- (3) Another way of making a permutation of $k$ objects out of $n$ is to
|
||||
- (a) Choose $k$ from $n$ without order. There $\binom{n}{k}$ ways of doing this.
|
||||
- (b) Then count all the ways of ordering these $k$ objects. There are $k!$ ways of doing this.
|
||||
- (c) By the Multiplicative Principle,
|
||||
- $$P(n,k) = \binom{n}{k}k!$$
|
||||
- (4) So now we know that
|
||||
- $$\frac{n!}{(n-k)!} = \binom{n}{k}k!$$
|
||||
- (5) This gives the formula
|
||||
- $$\binom{n}{k} = \frac{n!}{(n-k)!k!}$$
|
||||
-
|
||||
@ -0,0 +1,93 @@
|
||||
- #[[CT255 - Next Generation Technologies II]]
|
||||
- **Previous Topic:** [[DIffie-Hellman Key Exchange]]
|
||||
- **Next Topic:** [[Message Authentication]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Block Ciphers
|
||||
- ## Encryption Algorithms Based on Block Ciphers
|
||||
collapsed:: true
|
||||
- In a **block cipher**, the message is broken into blocks $M1$, $M2$, etc., of $K$ bits length, each of which is then encrypted.
|
||||
- 
|
||||
- Most ciphers that we saw before process blocks of just one character.
|
||||
- Claude Shannon suggested to use the two primitive cryptographic operations as building blocks for such ciphers:
|
||||
- **Substitution**.
|
||||
- **Permutation**.
|
||||
- ### The Permutation Operation
|
||||
- A binary word (i.e., block) has its bits re-ordered (permuted).
|
||||
- The re-ordering forms the key.
|
||||
- The Operation is represented by a **P-box**.
|
||||
- 
|
||||
- The example allows for 15! combinations.
|
||||
- The key describes the combinations used.
|
||||
- ### The Substitution Operation
|
||||
- A binary word is replaced by another binary word.
|
||||
- The whole substitution function forms the key.
|
||||
- The operation is represented by an **S-box**.
|
||||
- The box below allows for 8! combinations.
|
||||
- 
|
||||
- The key describes the combination used.
|
||||
- ### Substitution-Permutation Network
|
||||
- The key describes the internal wiring of all S-boxes & P-boxes.
|
||||
- The same key can be used for encoding & decoding, hence it is a **private key encryption algorithm**.
|
||||
- The direction of the process determines encoding / decoding.
|
||||
- 
|
||||
-
|
||||
- ## Confusion & Diffusion
|
||||
- A cipher needs to completely obscure the statistical properties of the original message.
|
||||
- Shannon introduced two terms to describe this:
|
||||
- **Diffusion** seeks to make the statistical relationship between the plaintext & ciphertext as complex as possible.
|
||||
- **Confusion** seeks to make the relationship between the statistics of the ciphertext and the value of the encryption key as complex as possible.
|
||||
- Both thwart attempts to deduce the key used via a cryptanalysis.
|
||||
- ## Reversible Transformation
|
||||
- An important block cipher principle is **Reversible Transformation** - transformations must be reversible or non-singular.
|
||||
- There must be a 1:1 association between an $n$-bit plaintext and an $n$-bit ciphertext, otherwise mapping is irreversible.
|
||||
- ## Features of Private-Key Cryptography
|
||||
- Traditional private/secret/single key cryptography uses one key, shared by only the sender and the receiver.
|
||||
- The algorithm/cipher itself is public, i.e., not a secret.
|
||||
- If the key is disclosed, communications are compromised.
|
||||
- The key is also **symettric**, parties are equal.
|
||||
- Hence, methods doe do not protect the sender from receiver forging .
|
||||
- Examples include DES and AES.
|
||||
- ## AES
|
||||
- The **Advanced Encryption Standard (AES)** is the successor of DES.
|
||||
- It is a modern block cipher with 128 bits block length.
|
||||
- Uses 128, 192, or 256 bit long keys.
|
||||
- The de-facto standard for secure encryption.
|
||||
- Widely used for file/data encryption, and secure network communication.
|
||||
- ## Why does Block & Key length matter?
|
||||
- Cryptographic algorithms with short block length can be tackled easily.
|
||||
- Large keys & long blocks prevent brute force attacks
|
||||
- The DES cipher used 56-bit keys - The generally accepted minimum key length today is 128-bit.
|
||||
- ### Brute Force Attacks
|
||||
- Always possible to simply try every key.
|
||||
- Most basic attack, effort proportional to key size.
|
||||
- Assume that you either know or recognise plaintext.
|
||||
- ## The Feistel Cipher
|
||||
- In practice, we need to be able to decrypt messages as well as encrypt them. Hence we either need to define inverses for each of the S & P-boxes (but this doubles the code / hardware needed) or define a structure that is easy to reverse, so you can use basically the same code or hardware for both encryption & decryption.
|
||||
- A **Feistel Cipher** is such a structure that is easy to reverse.
|
||||
- It is based on the concept of the **invertible product cipher**.
|
||||
- Most symmetric block ciphers are based on a Feistel Cipher structure.
|
||||
- Feistel invented a suitable structure which adapted Shannon's S-P network into an easily invertible structure.
|
||||
- Essentially, the same hardware or software is used for both encryption & decryption, with just a slight change in how the keys are used.
|
||||
- ### A Single Round
|
||||
collapsed:: true
|
||||
- The idea is to partition the input block into two halves, $L(i-1)$ & $R(i-1)$, and use only $R(i-1)$ in the $i^{\text{th}}$ round (part) of the cipher.
|
||||
- The function $g$ incorporates one stage of the S-P network, controlled by part of the key $K(i)$ known as the $i^{\text{th}}$ subkey.
|
||||
- 
|
||||
- A round of a Feistel Cipher can be described functionally as:
|
||||
- $$L(i) = R(i-1)$$
|
||||
- $$R(i) = L(i-1) \text{ EXOR } g(K(i), R(i-1))$$
|
||||
- 
|
||||
-
|
||||
- ### A Feistel Network
|
||||
- Perform multiple transformation (single rounds) sequentially, whereby the output of the $i$^{th} round becomes the input of the $(i+1)$^{th} round.
|
||||
- Every round gets its own subkey, which is derived from the master key.
|
||||
- The decryption process goes from bottom to top.
|
||||
- ### Feistel Cipher Design Elements
|
||||
- Block size.
|
||||
- Key size.
|
||||
- Number of rounds.
|
||||
- Subkey generation algorithm.
|
||||
- Round function.
|
||||
- Fast software encryption / decryption.
|
||||
-
|
||||
37
year2/semester1/logseq-stuff/pages/Bootstrap CSS.md
Normal file
37
year2/semester1/logseq-stuff/pages/Bootstrap CSS.md
Normal file
@ -0,0 +1,37 @@
|
||||
- #[[CT216 - Software Engineering I]]
|
||||
- **Previous Topic:** [[Agile Methods - Extreme Programming]]
|
||||
- **Next Topic:** [[JavaScript Functions & Events]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Bootstrap
|
||||
- What is **Bootstrap**? #card
|
||||
card-last-interval:: 3.32
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-18T03:14:11.275Z
|
||||
card-last-reviewed:: 2022-11-14T20:14:11.275Z
|
||||
card-last-score:: 5
|
||||
- **Bootstrap** is a CSS framework.
|
||||
- It consists of CSS classes for structure, layout, components (buttons, navbar, modal, etc.), forms, written by other developers.
|
||||
- This enforces a uniform layout, look, & feel on the web application.
|
||||
- Bootstrap is freely available to develop websites & web applications.
|
||||
- JavaScript is also used in conjunction with the CSS classes, for things like animations, transitions, popups, etc.
|
||||
- The CSS within Bootstrap is quite detailed, there are lots of classes with varying levels of hierearchy.
|
||||
- It's fully customisable & the web is full of themes & templates for apps built using it.
|
||||
- ## Adding Bootstrap to our Web Apps
|
||||
- Two options:
|
||||
- 1. Download the files, i.e., CSS, JS, and place them in the app folders.
|
||||
2. Use a Content Delivery Network URL.
|
||||
- What is a **CDN**? #card
|
||||
card-last-interval:: 3.45
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-18T06:18:01.678Z
|
||||
card-last-reviewed:: 2022-11-14T20:18:01.679Z
|
||||
card-last-score:: 5
|
||||
- A **Content Delivery Network (CDN)** is a popular way to include frontend libraries & technologies.
|
||||
- Instead of having a single server, CDNs involve using a collection of servers to serve content.
|
||||
- These servers are usually placed geographically close to the user base to ensure that maximum performance is achieved.
|
||||
- CDNs are largely designed for delivering static content, images, videos, & web content such as text, graphics, & scripts.
|
||||
-
|
||||
-
|
||||
@ -0,0 +1,203 @@
|
||||
- #[[CT213 - Computer Systems & Organisation]]
|
||||
- **Previous Topic:** [[Process Management]]
|
||||
- **Next Topic:** [[Process Synchronisation]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Scheduling
|
||||
- What is **scheduling**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T09:47:50.266Z
|
||||
card-last-score:: 1
|
||||
- **Scheduling** allows one process to use the CPU while the execution of another process is on hold (i.e., in the waiting state) due to unavailability of any resource like I/O etc.
|
||||
- It aims to make the system efficient, fast, & fair.
|
||||
- It is part of the **process manager**.
|
||||
- Scheduling is the mechanism that handles the ^^**removal** of the running processes from the CPU and the **selection** of another process.^^
|
||||
- It is responsible for **multiplexing** processes in the CPU.
|
||||
- When it is time for the **running** process to be removed from the CPU (into a *ready* or *suspended* state), a different process is selected from the set of processes in the ready state.
|
||||
- The selection of another process is based on a particular strategy - the **scheduling algorithm** will determine the order in which the OS will execute the processes.
|
||||
-
|
||||
- ## Scheduler Organisation #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:26:05.897Z
|
||||
card-last-score:: 1
|
||||
- When a process is changed to the *ready* state. the **enqueuer** places a pointer to the process descriptor into a **ready list**.
|
||||
- Whenever the scheduler switches the CPU from executing one process to another, the **context switcher** saves the contents of all the processor registers of the process being removed into the **process' descriptor**.
|
||||
- There are two types of context switch: **Voluntary** & **Involuntary**.
|
||||
- The **dispatcher** is invoked after the current process has been from the CPU.
|
||||
- The dispatcher chooses one of the processes enqueued in the ready list and then allocates CPU to that process by performing another context switch from *itself* to the selected process.
|
||||
- 
|
||||
- ## Scheduler Types
|
||||
collapsed:: true
|
||||
- What are the two main types of scheduler? #card
|
||||
card-last-interval:: 13.48
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-28T03:39:05.248Z
|
||||
card-last-reviewed:: 2022-11-14T16:39:05.248Z
|
||||
card-last-score:: 5
|
||||
- **Cooperative** Scheduler (Voluntary CPU Sharing).
|
||||
- **Preemptive** Scheduler (Involuntary CPU Sharing).
|
||||
- ### Cooperative Scheduler (Voluntary CPU Sharing) #card
|
||||
card-last-interval:: 9.28
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-11-24T02:11:30.468Z
|
||||
card-last-reviewed:: 2022-11-14T20:11:30.468Z
|
||||
card-last-score:: 3
|
||||
- Each process will **periodically invoke** the process scheduler, voluntarily sharing the CPU.
|
||||
- Each process should call a function that will implement the process scheduling.
|
||||
- $\text{yield}(P_{current}, P_{next})$ (sometimes implemented as instruction in hardware), where $P_{current}$ is an identifier of the current process and $P_{next}$ is an identifier of the next process.
|
||||
- Cooperative multitasking allows much simpler implementation of applications, because their ^^execution is never unexpectedly interrupted by the process scheduler.^^
|
||||
- Possible problem: If the process does not voluntarily cooperate with the others, one process could keep the CPU forever.
|
||||
- ### Preemptive Scheduler (Involuntary CPU Sharing) #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-22T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-21T13:11:05.756Z
|
||||
card-last-score:: 1
|
||||
- The interrupt system **enforces periodic involuntary interruption** of any process's execution; it can force a process to involuntarily execute a yield type function (or instruction).
|
||||
- This is done by incorporating an **interval timer** device that produces an interrupt whenever the time expires.
|
||||
- The programmable interval timer will cause an **interrupt** to run every $K$ clock ticks of a time interval, thus causing the hardware to execute the logical equivalent of a yield instruction to invoke the **interruption handler**.
|
||||
- The **interrupt handler** for the timer interrupt will call the scheduler to reschedule the processor **without** any action on the part of the running process.
|
||||
- The scheduler decides which process is run next.
|
||||
- The scheduler is guaranteed to be invoked once every $K$ clock ticks.
|
||||
- Even if a certain process executes in an infinite loop, it will **not** block the execution of the other processes.
|
||||
-
|
||||
- ## Performance Elements
|
||||
- Having a set of processes $P = \{p_i, 0 \leq i \leq n\}$.
|
||||
- **Service Time -** $\tau(p_i)$: The amount of time that a process needs to spend in the active/running state before it completes.
|
||||
- **Wait Time -** $W(p_i)$: The time that the process spends waiting in the ready state before its first transition to the active state.
|
||||
- **Turn-around Time -** $T_{TRnd}(p_i)$: The amount of time between the moment that a process enters the ready state and the moment that the process exits the running state for the last time.
|
||||
- These elements are used to measure the performance of each scheduling algorithm.
|
||||
-
|
||||
- ## Selection Strategies #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:13:18.970Z
|
||||
card-last-score:: 1
|
||||
- ### Non-Preemptive Strategies #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:49:49.983Z
|
||||
card-last-score:: 1
|
||||
- ==Allow any process to run to completion once it has been allocated control of the CPU.==
|
||||
- A process that gets the control of the CPU releases the CPU whenever it ends or when it voluntarily gives up control of the CPU.
|
||||
- ### Preemptive Strategies #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-25T13:08:54.894Z
|
||||
card-last-reviewed:: 2022-11-21T13:08:54.895Z
|
||||
card-last-score:: 3
|
||||
- ==The process with the highest priority among all the *ready* process is allocated the CPU.==
|
||||
- ==All lower priority processes are made to yield to the highest priority process whenever it requests the CPU.==
|
||||
- The **scheduler** is called every time a process enters the *ready* queue as well as when an interval timer expires.
|
||||
- Preemptive strategies allow for equitable resource sharing among processes, at the expense of overloading the system.
|
||||
-
|
||||
- ## Scheduling Algorithms
|
||||
- ### First Come, First Served (FCFS) #card
|
||||
card-last-interval:: 8.32
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.08
|
||||
card-next-schedule:: 2022-11-23T03:12:10.431Z
|
||||
card-last-reviewed:: 2022-11-14T20:12:10.431Z
|
||||
card-last-score:: 3
|
||||
- **Non-preemptive** algorithm.
|
||||
- This scheduling strategy assigns priority to processes by the order in which they request the processor.
|
||||
- The priority of a process is computed by the enqueuer by **time stamping** all incoming processes and then having the dispatcher select the process that has the ^^oidest time stamp.^^
|
||||
- Possible implementation: Using a FIFO data structure (where each entry points to a process descriptor). The enqueuer adds processes to the tail of the queue and the dispatcher removes processes from the head of the queue.
|
||||
- Easy to implement.
|
||||
- Not widely used because of ^^unpredictable **turn-around time** & **waiting time**.^^
|
||||
- ### Shortest Job First (SJF) #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:19:28.311Z
|
||||
card-last-score:: 1
|
||||
- **Non-preemptive** algorithm.
|
||||
- SJF is an optimal algorithm from the perspective of **average turn-around time** - it minimises the average turn-around time.
|
||||
- Preferential service of small jobs.
|
||||
- Requires the ^^knowledge of the **service time**^^ for each process.
|
||||
- In extreme cases where the system has little idle time, processes with large service time will never be served.
|
||||
- In the case where it is not possible to know the service time for each process, the service time is estimated using predictors.
|
||||
- ### Shortest Remaining Time Next (SRTN) #card
|
||||
card-last-interval:: 9.28
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-11-24T02:11:11.684Z
|
||||
card-last-reviewed:: 2022-11-14T20:11:11.685Z
|
||||
card-last-score:: 3
|
||||
- Similar to SJF, but **preemptive**.
|
||||
- If a long job is mostly complete, it might have a very short time remaining, and therefore would be prioritised.
|
||||
- ### Time Slice (Round Robin) #card
|
||||
card-last-interval:: 8.32
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.08
|
||||
card-next-schedule:: 2022-11-23T03:11:54.075Z
|
||||
card-last-reviewed:: 2022-11-14T20:11:54.076Z
|
||||
card-last-score:: 3
|
||||
- **Preemptive** algorithm.
|
||||
- Each process gets a time slice of CPU time, distributing the processing time equitably among all processes that are requesting the processor.
|
||||
- Whenever the time slice expires, control of the CPU is given to the next process in the ready list, and the process being switched from is placed back into the ready process list.
|
||||
- Time Slice implies the existence of a **specialised timer** that measures the processor time for each process.
|
||||
- Every time a process becomes active, the timer is intitialised.
|
||||
- Not very well suited for long jobs, as the scheduler will be called multiple times until the job is done.
|
||||
- Very sensitive to the size of the time slice.
|
||||
- Too big -> large delays in the response time for interactive processes.
|
||||
- Too small -> too much time spent running the scheduler.
|
||||
- Very big -> turns into FCFS.
|
||||
- The time slice is determined by analysing the number of instructions that the processor can execute in a given time slice.
|
||||
-
|
||||
- ### Priority-Based Preemptive Scheduling (Event Driven) #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:28:05.394Z
|
||||
card-last-score:: 1
|
||||
- Both **preemptive** & **non-preemptive** variants exist.
|
||||
- Each process has an ^^externally assigned priority.^^
|
||||
- Every time an event occurs that generates a process switch, the ^^process with the highest priority^^ is chosen from the ready process list.
|
||||
- There is a possibility that processes with low priority will never gain CPU time.
|
||||
- There are variants with **static** & **dynamic** priorities.
|
||||
- The **dynamic priority** computation solves the problem that some processes may never gain CPU time - the longer a process waits, the higher its priority becomes.
|
||||
- Used for real-time systems.
|
||||
- ### Multiple Level Queue Scheduling #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-22T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-21T13:11:11.306Z
|
||||
card-last-score:: 1
|
||||
- Complex systems have requirements for real-time, interactive users and batch jobs - Therefore, a **combined scheduling mechanism** should be used.
|
||||
- The processes are divided into **classes**.
|
||||
- Each class has a process queue, and has been assigned a specific scheduling algorithm.
|
||||
- Each process queue is treated according to its queue scheduling algorithm.
|
||||
- Each queue is assigned a priority.
|
||||
- As long as there are processes in a higher priority queue, those will be serviced.
|
||||
- #### Multiple Level Queue (with Feedback) #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:27:34.399Z
|
||||
card-last-score:: 1
|
||||
- Same as MLQ, but the ^^processes can migrate from class to class^^ in a dynamic fashion.
|
||||
- Different strategies exist to modify the priority of a process.
|
||||
- Increase the priority for a given process. (E.g., the user needs a larger share of the CPU to sustain acceptable service).
|
||||
- Decrease the priority for a given process. (E.g., the user process is trying to get more CPU share, which may impact on the other users).
|
||||
- If a process is giving up the CPU before its time slice expires, then the process is assigned to a higher priority queue.
|
||||
- During the evolution to completion, a process may go through a number of different classes.
|
||||
- Any of the previous algorithms covered may be used for treating a specific process class.
|
||||
@ -0,0 +1,3 @@
|
||||
- 
|
||||
- ## Lab Information
|
||||
- Labs will run from **Week 03** (Week starting 2022-09-19)
|
||||
@ -0,0 +1,3 @@
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
-
|
||||
@ -0,0 +1,3 @@
|
||||
- #[[Second Year University]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
@ -0,0 +1,3 @@
|
||||
- # Semester 1 - Cybersecurity
|
||||
-
|
||||
-
|
||||
80
year2/semester1/logseq-stuff/pages/Cloud Computing.md
Normal file
80
year2/semester1/logseq-stuff/pages/Cloud Computing.md
Normal file
@ -0,0 +1,80 @@
|
||||
- #[[CT216 - Software Engineering I]]
|
||||
- No previous topic
|
||||
- **Next Topic:** [[Software Processes]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- What is **Cloud Computing**? #card
|
||||
card-last-interval:: 64.01
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.52
|
||||
card-next-schedule:: 2023-01-24T13:10:05.691Z
|
||||
card-last-reviewed:: 2022-11-21T13:10:05.691Z
|
||||
card-last-score:: 5
|
||||
- **Cloud Computing** is a model for enabling convenient, on-demand network access to a ^^shared pool of configurable computing resources^^ (e.g., networks, servers, storage, applications, & services) that can be rapidly provisioned and released with minimal management effort or service provider interaction.
|
||||
- What is a **Public Cloud**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:38:52.044Z
|
||||
card-last-reviewed:: 2022-11-14T16:38:52.044Z
|
||||
card-last-score:: 5
|
||||
- Amazon, MS Azure, & Google Cloud are examples of **public clouds**.
|
||||
- Any member of the public can sign up and start provisioning computing resources within minutes.
|
||||
- They are **highly scalable** and allow an organisation to grow its infrastructure rapidly.
|
||||
- What is a **Private Cloud**? #card
|
||||
card-last-interval:: 29.26
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T22:39:16.682Z
|
||||
card-last-reviewed:: 2022-11-14T16:39:16.682Z
|
||||
card-last-score:: 5
|
||||
- Computing resources are dedicated to a single customer and not shared with other customers.
|
||||
- Considered to be more **secure**.
|
||||
- What is a **Hybrid Cloud**? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-12T23:38:48.180Z
|
||||
card-last-reviewed:: 2022-11-14T16:38:48.180Z
|
||||
card-last-score:: 3
|
||||
- A **hybrid cloud** is simply a mix of public & private cloud resources.
|
||||
- An organisation may choose this option if there is a mixture in the criticality of their data or computational requirements.
|
||||
- Data that doesn't require heightened security can be pushed onto the **public cloud**, while data which does can be hosted on the **private cloud**.
|
||||
- ## Cloud Services
|
||||
- What is **SaaS**? #card
|
||||
card-last-interval:: 15.05
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 1.94
|
||||
card-next-schedule:: 2022-11-29T17:40:43.905Z
|
||||
card-last-reviewed:: 2022-11-14T16:40:43.906Z
|
||||
card-last-score:: 3
|
||||
- **Software as a Service (SaaS)** provides users with (essentially) ^^a **cloud application**, the platform on which it runs, & the platform's underlying infrastructure.^^
|
||||
- What is **PaaS**? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T03:02:49.119Z
|
||||
card-last-reviewed:: 2022-11-14T20:02:49.119Z
|
||||
card-last-score:: 3
|
||||
- **Platform as a Service (PaaS)** provides users with ^^compute, networking, & storage resources.^^
|
||||
-
|
||||
- What are the advantages of cloud computing? #card
|
||||
card-last-interval:: 29.26
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T22:48:16.198Z
|
||||
card-last-reviewed:: 2022-11-14T16:48:16.199Z
|
||||
card-last-score:: 5
|
||||
- **Elasticity** - if your application becomes very popular, you can procure new resources within minutes.
|
||||
- Reduced capital expenditure.
|
||||
- Economies of scale.
|
||||
- What are the disadvantages of cloud computing? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:52:05.308Z
|
||||
card-last-reviewed:: 2022-11-14T16:52:05.309Z
|
||||
card-last-score:: 5
|
||||
- Security / privacy
|
||||
- Cost
|
||||
- Migration issues
|
||||
90
year2/semester1/logseq-stuff/pages/Coding Up Inheritance.md
Normal file
90
year2/semester1/logseq-stuff/pages/Coding Up Inheritance.md
Normal file
@ -0,0 +1,90 @@
|
||||
- #[[CT2106 - Object-Oriented Programming]]
|
||||
- **Previous Topic:** [[Introduction to Inheritance]]
|
||||
- **Next Topic:** [[Abstraction & Polymorphism]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Key Ideas in a Class Hierarchy
|
||||
- The top of the hierarchy represents the most generic attributes & behaviours.
|
||||
- The bottom (the leaves) represent the most specific attributes & behaviours.
|
||||
- Each level inherits & customises the attributes & behaviours from the level above it.
|
||||
- What is **OOP Inheritance**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-22T18:35:20.846Z
|
||||
card-last-reviewed:: 2022-11-18T18:35:20.847Z
|
||||
card-last-score:: 5
|
||||
- **OOP Inheritance** is the means by which objects automatically receive features (fields) & behaviours (methods) from their super classes.
|
||||
- # Java Class Hierarchy
|
||||
- At the top of the Java Class Hierarchy is a class called `java.lang.Object`.
|
||||
- All classes inherit *implicitly* from `java.lang.Object`.
|
||||
- This means that a class doesn't have to specify explicitly that `java.lang.Object` is its superclass.
|
||||
- ## Rules of Class Hierarchy
|
||||
- In Java, the variable type can be the superclass of the object.
|
||||
- The variable type can be **any superclass** of the object, not just `java.lang.Object`.
|
||||
-
|
||||
- # Explicit Inheritance
|
||||
- All classes inherit methods *implicitly* from `java.lang.Object`.
|
||||
- Two common methods that are inherited from `java.lang.Object`:
|
||||
- `equals()`
|
||||
- `toString()`
|
||||
- In every other case, you have to tell Java which classes are in a superclass relationship.
|
||||
- ## Steps
|
||||
- 1. Create the classes
|
||||
2. Inert the inheritance relationships.
|
||||
3. Insert the fields.
|
||||
4. Insert the methods.
|
||||
5. Override the necessary fields.
|
||||
6. Override necessary methods.
|
||||
7. Test by putting objects in an array & calling their behaviours.
|
||||
- ## Defining Inheritance #card
|
||||
card-last-interval:: 3.45
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-18T06:10:29.757Z
|
||||
card-last-reviewed:: 2022-11-14T20:10:29.758Z
|
||||
card-last-score:: 3
|
||||
- The keyword `extends` indicates the subclass to be extended (inherited from).
|
||||
- You must call the constructor of the superclass using the method call `super()`.
|
||||
- If the superclass constructor takes a parameter, then the call to `super()` must include a value of the parameter.
|
||||
- For example:
|
||||
- ```java
|
||||
public class Bird extends Animal
|
||||
{
|
||||
boolean hasFeathers; // these fields aren't private.
|
||||
boolean hasWings; // we want these fields to be inherited
|
||||
boolean flies; // so we don't make the private.
|
||||
|
||||
public Bird()
|
||||
{
|
||||
super(); // calls the constructor of its superclass - Animal
|
||||
colour = "black";
|
||||
hsaFeathers = true;
|
||||
hasWings = true;
|
||||
flies = true;
|
||||
}
|
||||
}
|
||||
```
|
||||
- # `abstract` #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-18T20:09:22.323Z
|
||||
card-last-reviewed:: 2022-11-14T20:09:22.324Z
|
||||
card-last-score:: 5
|
||||
- It may not make sense to have an object of a superclass type.
|
||||
- For example, there is no object that is just an `Animal` or `Bird` and no more than that - all Animals are a specific subclass of `Animal`.
|
||||
- ^^The Java keyword `abstract` allows you to specify which classes can be made into objects and which are used for inheritance purposes.^^
|
||||
- Adding the keyword `abstract` to the class definition tells Java that it can't make objects from this class.
|
||||
- However, an abstract class can still be used as a type of reference variable.
|
||||
- ```java
|
||||
Bird bird = new Canary("John");
|
||||
Animal animal = new Canary("Mary");
|
||||
```
|
||||
- For example:
|
||||
- ```java
|
||||
public abstract class Animal // doesn't allow objects of just type Animal
|
||||
```
|
||||
- ```java
|
||||
public abstract class Bird extends Animal
|
||||
```
|
||||
@ -0,0 +1,156 @@
|
||||
- #[[MA284 - Discrete Mathematics]]
|
||||
- **Previous Topic:** [[Convex Polyhedra]]
|
||||
- **Next Topic:** [[Trees]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Vertex Colouring
|
||||
- There are maps that can be coloured with a single colour, two colours, three colours, or four colours.
|
||||
- For all maps, no matter how complicated, at most four colours is sufficient.
|
||||
- # Colouring Graphs
|
||||
- If we think of a map as a way of showing which regions share borders, then we can represent it as a **graph**, where:
|
||||
- A vertex in the graph corresponds to a region in the map.
|
||||
- There is an edge between two vertices in the graph if the corresponding regions share a border.
|
||||
- Colouring regions of a map corresponds to colouring vertices of the graph. Since neighbouring regions in the map must have different colours, so too must adjacent vertices.
|
||||
- More precisely:
|
||||
- **Vertex Colouring:** An assignment of colours to the vertices of a graph.
|
||||
- **Proper Colouring:** If the vertex colouring has the property that adjacent vertices are coloured differently, then the colouring is called **proper**.
|
||||
- **Minimal Colouring:** A proper colouring that is done with the fewest possible number of colours.
|
||||
- Lots of different proper colourings are possible. If the graph has $v$ vertices, then clearly at most $v$ colours are needed. However, usually, we need far fewer.
|
||||
- ## Chromatic Numbers
|
||||
- What is the **chromatic number** of a graph? #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T10:50:36.778Z
|
||||
card-last-reviewed:: 2022-11-14T15:50:36.779Z
|
||||
card-last-score:: 5
|
||||
- The **chromatic number** of the graph, written $\chi(G)$ is the smallest number of colours needed to get a proper vertex colouring of a graph $G$.
|
||||
- ### Example
|
||||
- Determine the **chromatic number** of the graphs $C_2$, $C_3$, $C_4$, & $C_5$.
|
||||
background-color:: green
|
||||
- $$\chi(C_2) = 2$$
|
||||
- $$\chi(C_3) = 3$$
|
||||
- $$\chi(C_4) = 2$$
|
||||
- $$\chi(C_3) = 5$$
|
||||
- Determine the **chromatic number** of the $K_n$ & $K_{p,q}$ for any $n$, $p$, $q$.
|
||||
background-color:: green
|
||||
- $$\chi(K_4) = 4$$
|
||||
- $$\chi(K_n) = n$$
|
||||
- $$\chi(K_{3,3}) = 2$$
|
||||
- $$\chi(K_{p,q}) = 2$$
|
||||
- In general, calculating $\chi(G)$ is not easy, but there are some ideas that can help. For example, it is clearly true that if a graph has $v$ vertices, then
|
||||
- $$1 \leq \chi(G) \leq v$$
|
||||
- ### Cliques
|
||||
- If the graph happens to be **complete**, then $\chi(G) = v$. If it is **not** complete, then we can look at ***cliques*** in the graph.
|
||||
- What is a **clique** of a graph? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:14:53.505Z
|
||||
card-last-score:: 1
|
||||
- A **clique** is a subgraph of a graph, all of whose vertices are connected to each other.
|
||||
- (Clique numbers will not be on the exam).
|
||||
- What is the **clique number** of a graph? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-23T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-22T13:37:29.890Z
|
||||
card-last-score:: 1
|
||||
- The **clique number** of a graph, $G$, is the number of vertices in the largest clique in $G$.
|
||||
- **Lower Bound:** The chromatic number of a graph is *at least* its clique number.
|
||||
- **Upper Bound:** $\chi(G) \leq \Delta(G) + 1$, where $\Delta(G)$ denotes the largest degree of any vertex in the graph $G$.
|
||||
- # Algorithms for $\chi(G)$
|
||||
- In general, finding a proper colouring for a graph is hard. There are some algorithms that are efficient, but not optimal. We'll look at two:
|
||||
- The **Greedy Algorithm**.
|
||||
- The **Welsh-Powell Algorithm**.
|
||||
- The **Greedy Algorithm** is simple & efficient, but the result can depend on the ordering of the vertices.
|
||||
- The **Welsh-Powell Algorithm** is slightly more complicated, but can give better colourings.
|
||||
- ## Greedy Algorithm #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:22:55.701Z
|
||||
card-last-score:: 1
|
||||
- 1. Number all the vertices. Number your colours.
|
||||
2. Give a colour to vertex 1.
|
||||
3. Take the remaining vertices in order. Assign each one the lowest numbered colours that is different from the colours of its neighbours.
|
||||
- ## Welsh-Powell Algorithm #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:51:29.529Z
|
||||
card-last-score:: 1
|
||||
- 1. List all vertices in decreasing order of their degree (i.e., largest degree first). If two or more share the same degree, list them in any way you want.
|
||||
2. Colour the first listed vertex (with the first unused colour).
|
||||
3. Work down the list, giving that colour to all vertices **not** conencted to one previously coloured.
|
||||
4. Cross (verb.) coloured vertices of the list, and return to the start of the list.
|
||||
- # Eulerian Paths & Circuits
|
||||
- Recall that a **path** is a sequence of adjacent vertices in a graph.
|
||||
- What is a **Eulerian Path**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:18:26.028Z
|
||||
card-last-score:: 1
|
||||
- A **Eulerian Path** (also called an *Euler Path* and an *Eulerian trail*) in a graph is path which uses every edge exactly once.
|
||||
- 
|
||||
- Recall that a **circuit** is a path that begins & ends at that same vertex, and no edge is repeated.
|
||||
- What is an **Eulerian Circuit**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:21:29.522Z
|
||||
card-last-score:: 1
|
||||
- An **Eulerian Circuit** (also called an *Eulerian Cycle*) is an *Eulerian path* that that starts & finishes on at the same vertex.
|
||||
- If a graph has such a circuit, we say that it is *Eulerian*.
|
||||
- It is possible to come up with a condition that guarantees that a graph has an Eulerian Path, and, additionally, one that ensures that ensures that it has an Eulerian Circuit.
|
||||
- To begin with, we'll reason that the following graph could *not* have an Eulerian circuit, although it *does* have an Eulerian path.
|
||||
- 
|
||||
- Suppose, first, that we have a graph that ==**does** have an Eulerian circuit.== Then, for every edge in the circuit that "exits" a vertex, there is another that "enters" that vertex. So, every vertex must have even degree.
|
||||
- A graph has an **Eulerian Circuit** if and only if every vertex has even degree.
|
||||
- Next, suppose that a graph==does **not** have an Eulerian circuit==, but does have an **Eulerian path**. Then, the degree at the "start" & "end" verticwes must be odd, and every other vertex has even degree.
|
||||
- A graph has an **Eulerian Path** if and only if it has either **zero** or **two** vertices with odd degree.
|
||||
- # Hamiltonian Paths & Cycles
|
||||
- What is a **Hamiltonian Path**? #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-24T08:06:13.770Z
|
||||
card-last-reviewed:: 2022-11-21T13:06:13.770Z
|
||||
card-last-score:: 5
|
||||
- A **Hamiltonian Path** is a graph that visits every vertex exactly once.
|
||||
- What is a **Hamiltonian Cycle**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:23:21.600Z
|
||||
card-last-score:: 1
|
||||
- A **Hamiltonian Cycle** is a cycle which visits the start / end vertex twice, and every other vertex exactly once.
|
||||
- A graph that has a Hamiltonian Cycle is called a **Hamiltonian Graph**.
|
||||
- Important examples of Hamiltonian Graphs include cycle graphs, complete graphs, & graphs of the platonic solids.
|
||||
- In general, the problem of finding a Hamiltonian path or cycle in a large graph is hard - it is known to be NP-complete. However, there are two relatively simple *sufficient conditions* to testing if a graph is Hamiltonian:
|
||||
- ## Ore's Theorem #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:50:30.834Z
|
||||
card-last-score:: 1
|
||||
- A graph with $v$ vertices, where $v \geq 3$, is **Hamiltonian** if, for every pair of non-adjacent vertices, the sum of their degrees is $\geq v$.
|
||||
- ## Dirac's Theorem #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:15:37.739Z
|
||||
card-last-score:: 1
|
||||
- A simple graph with $v$ vertices, where $v \geq 3$, is **Hamiltonian** if every vertex has degree $\geq v / 2$.
|
||||
-
|
||||
-
|
||||
87
year2/semester1/logseq-stuff/pages/Combinatorial Proofs.md
Normal file
87
year2/semester1/logseq-stuff/pages/Combinatorial Proofs.md
Normal file
@ -0,0 +1,87 @@
|
||||
- #[[MA284 - Discrete Mathematics]]
|
||||
- **Previous Topic:** [[Binomial Coefficients]]
|
||||
- **Next Topic:** [[Stars & Bars]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Pascal's Triangle
|
||||
- **Pascal's Identity:** A recurrence relation for $\binom{n}{k}$:
|
||||
- $$\binom{n}{k} = \binom{n-1}{k-1} + \binom{n-1}{k}$$
|
||||
- In the previous topic, we "proved" that $\binom{n}{k} = \frac{n!}{(n-k)!k!}$ by counting $P(n,k)$ in two different ways.
|
||||
- This is a classic example of a **Combinatorial Proof**, where we establish a formula by counting something in 2 different ways.
|
||||
- 
|
||||
- Binomial coefficients have many important properties. Looking at their arrangement in Pascal's Triangle, we can spot some:
|
||||
- (i) For all $n$, $\binom{n}{0} = \binom{n}{n} = 1$.
|
||||
- (ii) $\displaystyle\sum^{n}_{i=0} \binom{n}{i}= 2^n$
|
||||
- (iii) $\binom{n}{k} = \binom{n-1}{k-1} + \binom{n-1}{k}$ (Pascal's Identity).
|
||||
- (iv) $\binom{n}{k} = \binom{n}{n-k}$
|
||||
-
|
||||
- # Algebraic & Combinatorial Proofs
|
||||
- Proofs of identities involving **Binomial Coefficients** can be classified as:
|
||||
- **Algebraic:** If they rely mainly on the formula for binomial coefficients.
|
||||
- $$
|
||||
\binom{n}{k} = \frac{n!}{k!(n-k)!}
|
||||
\newline
|
||||
\therefore \binom{n}{k} = \frac{n!}{(n-k)!(n-(n-k))!} = \frac{n!}{(n-k)!k!} = \binom{n}{k}
|
||||
$$
|
||||
- **Combinatorial:** If they involve counting a set in two different ways.
|
||||
- Let $A$ be a set of size $n$.
|
||||
- $\binom{n}{k} =$ number of subsets of $A$ of cardinality $k$, but for each such subset there is a one-to-one correspondence with a subset of size $n-k$.
|
||||
- i.e., $\binom{n}{n-k} = \binom{n}{k}$,
|
||||
- ## Algebraic Proof of Pascal's Triangle Recurrence Relation
|
||||
- $$\binom{n}{k} = \frac{n!}{k!(n-k)!} \newline \newline$$
|
||||
- $$\binom{n-1}{k-1} + \binom{n-1}{k} = \frac{(n-1)!}{(k-1)!(n-k)!} + \frac{(n-1)!}{k!(n-k-1)!}$$
|
||||
- $$ = \frac{k(n-1)!}{k(k-1)!(n-k)!} + \frac{(n-1)!(n-k)}{k!(n-k-1)!(n-k)} $$
|
||||
- $$= \frac{k(n-1)!+(n-k)(n-1)!}{k!(n-k)!}$$
|
||||
- $$= \frac{(n-1)!(k+n-k)}{k!(n-k)!} = \frac{n!}{k!(n-k)!} = \binom{n}{k}$$
|
||||
-
|
||||
-
|
||||
- ## Example:
|
||||
- Let $A$ be a set with $n$ elements.
|
||||
- Then, the total number of subsets of $A$ can be counted as follows:
|
||||
- Generic subset: An element is either in it or not
|
||||
- For each of $n$ elements, there are 2 choices: in or not in.
|
||||
- By Multiplicative principle, 2 \times 2 \times ... \times 2 such subsets [2^n = |P(n)|].
|
||||
- Number of subsets with:
|
||||
- 0
|
||||
-
|
||||
-
|
||||
-
|
||||
- # How Combinatorial Proofs Work
|
||||
- ## Which are better: Algebraic or Combinatorial proofs?
|
||||
- When we first study discrete mathematics, **algebraic** proofs may seem to be the easiest: they rely only using some standard formulae, and don't require any deeper insight. They are also more "familiar".
|
||||
- However:
|
||||
- Often, algebraic proofs are quite tricky.
|
||||
- Usually, algebraic proofs give no insight as to why a fact is true.
|
||||
- ## Example
|
||||
- We wish to show that:
|
||||
- $${\binom{n}{0}}^2 + {\binom{n}{1}}^2 + {\binom{n}{2}}^2 + ... + {\binom{n}{n}}^2 = \binom{2n}{n}$$
|
||||
- We note that $\binom{2n}{n}$ is the total number of subsets of size $n$ in a set with $2n$ elements.
|
||||
- Let $A$ be a set with $2n$ elements, and label them $A = \{a_1, a_2, ..., a_n, a_{n+1}, ..., a_{2n}\}$.
|
||||
- Any subset of $A$ with $n$ elements has $k$ elements from $\{a_1 a_2, ..., a_n\}$ and $n-k$ elements from t $\{a_{n+1}, ..., a_{2n}\}$ where $k$ ranges from $0$ to $n$.
|
||||
- There are $\displaystyle \binom{n}{k} \cdot \binom{n}{n-k}$ ways of choosing these $n$ elements by the Multiplicative Principle.
|
||||
- So the total number of subsets with $n$ elements is $\displaystyle\sum^n_{k=0} \binom{n}{k} \binom{n}{n-k}$ and noting that $\displaystyle \binom{n}{n-k} = \binom{n}{k}$ and the results follows.
|
||||
- ## Example
|
||||
- Using a combinatorial argument, or otherwise, prove that
|
||||
- $$k\binom{n}{k} = n\binom{n-1}{k-1}$$
|
||||
- **Combinatorial Proof**:
|
||||
- Suppose we have a panel of $n$ players and we need to choose a team of $k$ player with a distinguished player (e.g., the goalkeeper).
|
||||
- We count how many ways we can do this.
|
||||
- [A] Pick the team, then pick the goalie.
|
||||
- By the Multiplicative Principle, we can pick a team of $k$ from $n$ in $\binom{n}{k}$ ways and have $k$ ways then of choosing a keeper from this.
|
||||
- $$= k\binom{n}{k}$$
|
||||
- [B] Pick the goalie, then pick the remainder of the team.
|
||||
- We have $n$ choices for the goalie. then choose $k-1$ from the $n-1$ remaining players.
|
||||
- By the Multiplicative Principle we have $\displaystyle n\binom{n-1}{k-1}$ ways.
|
||||
- Result follows.
|
||||
- ## What is a "Combinatorial Proof" really? #card
|
||||
card-last-interval:: 9.28
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-11-23T22:36:16.354Z
|
||||
card-last-reviewed:: 2022-11-14T16:36:16.354Z
|
||||
card-last-score:: 5
|
||||
- [1] These proofs involve finding two different ways to answer the same counting question.
|
||||
- [2] Then, we explain why the answer to the problem posed one way is $A$.
|
||||
- [3] Next, we explain why the answer to the problem posed the other way is $B$.
|
||||
- [4] Since $A$ and $B$ are answers to the same question, we have shown that it must be that $A = B$.
|
||||
-
|
||||
155
year2/semester1/logseq-stuff/pages/Convex Polyhedra.md
Normal file
155
year2/semester1/logseq-stuff/pages/Convex Polyhedra.md
Normal file
@ -0,0 +1,155 @@
|
||||
- #[[MA284 - Discrete Mathematics]]
|
||||
- **Previous Topic:** [[Definitions & Planar Graphs]]
|
||||
- **Next Topic:** [[Colouring Graphs; Eulerian & Hamiltonian Graphs]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Non-Planar Graphs
|
||||
- Most graphs do not have a planar representation, however, it takes some work to *prove* that a graph is non-planar.
|
||||
- To do this, we can use **Euler's formula for planar graphs** to *prove* that they are not planar.
|
||||
- ## Theorem: $K_{5}$ is not planar (Theorem 4.3.1 in Textbook)
|
||||
- The proof is by **contradiction**.
|
||||
- So assume that $K_5$ is **planar**. Then, the graph must satisfy Euler's formula for planar graphs.
|
||||
- $K_5$ has 5 vertices & 10 edges, so we get $5-10 + f =2$, which says that if the graph is drawn without any edges crossing, there would be $f = 7$ faces.
|
||||
- Now consider how many edges surround each face. Each face must be surrounded by *at least* 3 edges.
|
||||
- Let $B$ be the total number of *boundaries* around all the faces in the graph.
|
||||
- Thus, we have that $3f \leq B$, but also $B = 2e$, as each edge is used as a boundary exactly twice.
|
||||
- Putting this together, we get $3f \leq B$, but this is impossible, since we have already determined that $f = 7$ and $e = 10$, and $21 \nleq 20$.
|
||||
- This is a contradiction, so $K_5$ is **not planar**.
|
||||
- Q.E.D.
|
||||
- ## Theorem: $K_{3,3}$ is not planar (Theorem 4.2.2 in Textbook)
|
||||
- Please read the proof in the textbook (or edit this later).
|
||||
- The proof for $K_{3,3}$ is somewhat similar to $K_5$, but it also uses the fact that a bipartite graph has no 3-edge cycles.
|
||||
- To understand the importance of $K_5$ & $K_{3,3}$, we first need that the concept of **homeomorphic** graphs.
|
||||
- Recall that a graph $G_1$ is a **subgraph** of $G$ if it can be obtained by deleting some vertices and / or edges of $G$.
|
||||
- ## Homeomorphic Graphs
|
||||
- What is a **subdivision** of an **edge**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:15:33.031Z
|
||||
card-last-score:: 1
|
||||
- A **subdivision** of an **edge** is obtained by "adding" a new vertex of degree 2 to the middle of the edge.
|
||||
- What is a **subdivision** of a **graph**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:52:43.154Z
|
||||
card-last-score:: 1
|
||||
- A **subdivision** of a **graph** is obtained by subdividing one or more of its edges.
|
||||
- What is the **smoothing** of a pair of edges? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:52:16.893Z
|
||||
card-last-score:: 1
|
||||
- The **smoothing** of the pair of edges $\{a,b\}$ & $\{b,c\}$, where $b$ is a vertex of degree 2, means to remove these two edges, and add $\{a,c\}$.
|
||||
- What does it mean if two graphs are **homeomorphic**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:25:55.182Z
|
||||
card-last-score:: 1
|
||||
- Two graphs $G_1$, $G_2$ are **homeomorphic** if there is some subdivision of $G_1$ that is isomorphic to some subdivision of $G_2$.
|
||||
- ### Kuratowski's Theorem #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:26:18.688Z
|
||||
card-last-score:: 1
|
||||
- What is **Kuratowski's Theorem**? #card
|
||||
card-last-interval:: 3.69
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-22T10:36:43.656Z
|
||||
card-last-reviewed:: 2022-11-18T18:36:43.657Z
|
||||
card-last-score:: 5
|
||||
- A graph is planar if and only if it does not contain a subgraph that is **homeomorphic** to $K_5$ or $K_{3,3}$.
|
||||
- What this really means is that **every** non-planar graph has some smoothing that contains a copy of $K_5$ or $K_{3,3}$ somewhere inside it.
|
||||
-
|
||||
- # Polyhedra
|
||||
- What is a **polyhedron**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:25:09.000Z
|
||||
card-last-score:: 1
|
||||
- A **polyhedron** is a geometric solid made up of flat polygonal faces joined at edges & vertices.
|
||||
- What is a **convex polyhedron**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:22:24.900Z
|
||||
card-last-score:: 1
|
||||
- A **convex polyhedron** is one where any line segment connecting two points on the interior of the polyhedron must be entirely contained inside the polyhedron.
|
||||
- A remarkable, and important fact, is that *every* convex polyhedron can be porjected onto the plane without edges crossing.
|
||||
- 
|
||||
- 
|
||||
- Now that we know that every convex polyhedron can be represented as a planar graph, we can apply Euler's formula.
|
||||
- ## Euler's Formula for Polyhedra #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:17:27.666Z
|
||||
card-last-score:: 1
|
||||
- If a convex polyhedron has $v$ vertices, $e$ edges, & $f$ faces, then
|
||||
- $$v - e+ f =2$$
|
||||
- 
|
||||
- ## The Handshaking Lemma #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:22:43.283Z
|
||||
card-last-score:: 1
|
||||
- The sum of the vertex degrees is $2|E|$:
|
||||
- Let $G = (V,E)$ be a graph, with vertices $V = v_1, v_2, \cdots, v_n$.
|
||||
- Let $\text{deg}(v_i)$ be the "degree of $v+i$". Then
|
||||
- $$\text{deg}(v_1) + \text{deg}(v_2) + \cdots + \text{deg}(v_n) = 2|E|$$
|
||||
-
|
||||
- ## Example
|
||||
- Show that there is no convex polyhedron with 11 vertices, all of degree 3.
|
||||
background-color:: green
|
||||
- If such a convex polyhedron existed, we could draw its graph.
|
||||
- Each vertex has degree 3, so
|
||||
- $$2|E| = \sum d(v_i) = 3 \times 11$$
|
||||
- $$\therefore |E| = \frac{33}{2} \text{, which is impossible}$$
|
||||
- # The Platonic Solids
|
||||
- What is a **Regular Polyhedron**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:25:24.689Z
|
||||
card-last-score:: 1
|
||||
- A polyhedron is called **regular** if:
|
||||
- All its faces are identical, regular polygons.
|
||||
- All its vertices have the same degree.
|
||||
- What are the **Platonic Solids**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:16:02.569Z
|
||||
card-last-score:: 1
|
||||
- The convex regular polyhedra are also called the **Platonic Solids**.
|
||||
- There are exactly 5 regular polyhedra. This fact can be proven using Euler's formula.
|
||||
- For full details, see the proof in the textbook.
|
||||
- Here is the basic idea:
|
||||
- Consider a regular polyhedron with $f$ **triangular** faces.
|
||||
- So $2e - 3f$.
|
||||
- Suppose that every vertex has degree $k$.
|
||||
- So $2e - vk$. Also, $v - e +f =2$. So
|
||||
- $$e = \frac{3f}{2}, v = \frac{3f}{k}, \Rightarrow \frac{3f}{k} - \frac{3f}{2} + f =2$$
|
||||
- and thus
|
||||
- $$f = \frac{4k}{6-k}$$
|
||||
- $f$ is defined for any $k < 6$, but undefined for $k = 6$ , and if $k > 6$ then $f < 0$ - no solutions.
|
||||
-
|
||||
-
|
||||
@ -0,0 +1,99 @@
|
||||
- #[[ST2001 - Statistics in Data Science I]]
|
||||
- **Previous Topic:** [[Hypothesis Testing]]
|
||||
- **Next Topic:** No next topic.
|
||||
- **Relevant Slides:** _1668682885675_0.pdf)
|
||||
-
|
||||
- # Modelling Relationships
|
||||
- In may applications, we want to know if there is a **relationship** between variables.
|
||||
- What is **Regression**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T19:35:13.517Z
|
||||
card-last-score:: 1
|
||||
- **Regression** is a set of statistical methods for estimating the relationship between a **response variable** & **one or more explanatory variables**.
|
||||
- Regression may have the aim of **explanation** (describing & quantifying relationships between variables) or **prediction** (how well can we predict a response variable from explanatory variables).
|
||||
- # Correlation Coefficients
|
||||
- What is the **Sample Correlation Coefficient**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T19:35:19.270Z
|
||||
card-last-score:: 1
|
||||
- The **Sample Correlation Coefficient** $r$ gives a numerical measurement of the strength of the linear relationship between the explanatory & response variables.
|
||||
- $$r = \frac{\sum (x_i = \bar x)(y_i - \bar y)}{\sqrt{\sum (x_i - \bar x)^2 \sum (y_i - \bar y)^2}}$$
|
||||
- **Note:** $\rho$ is the **population** correlation coefficient, while $r$ is the **sample** correlation coefficient.
|
||||
- $\rho = +1$ means a **perfect, linear direct** relationship between $X$ & $Y$.
|
||||
- $\rho = 0$ means **no linear** relationship between $X$ & $Y$.
|
||||
- $\rho = -1$ means a **perfect, inverse linear relationship** between $X$ & $Y$.
|
||||
- 
|
||||
- {:height 305, :width 645}
|
||||
- {:height 524, :width 645}
|
||||
- Correlation treats $x$ & $y$ symmetrically - the correlation of $x$ with $y$ is the same as the correlation of $y$ with $x$.
|
||||
- Correlation has no units.
|
||||
- Correlation is not affected by changes in the centre or scale of either variable.
|
||||
- The correlation coefficient only measures linear association.
|
||||
- The correlation coefficient can be misleading when outliers are present.
|
||||
- ## Correlation $\neq$ Causation
|
||||
- Correlation does not imply causation.
|
||||
- Scatterplots & correlation coefficients **never** prove causation.
|
||||
- A hidden variable that stands behind a relationship & determines it by simultaneously affecting the other two variables is called a **lurking** or **confounding** variable.
|
||||
- Don't say "correlation" when you mean "association".
|
||||
- More often than not, people say "correlation" when they mean "association".
|
||||
- The word "correlation" should be reserved for measuring the strength & direction of the linear relationships between two quantitative variables.
|
||||
- ## Summary
|
||||
- Scatterplots are useful graphical tools for asserting *direction*, *form*, *strength*, & *unusual features* between two variables.
|
||||
- Although not every relationship is linear, when the scatterplot is straight enough, the *correlation coefficient* is a useful numerical summary.
|
||||
- The sign of the correlation tells us the direction of the association.
|
||||
- The magnitude of the correlation tells us the *strength* of a linear association.
|
||||
- Correlation has no units, so shifting or scaling the data, standardising, or swapping the variables has no effect on the numerical value.
|
||||
- # Simple Linear Regression
|
||||
- What is **Simple Linear Regression**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T19:34:38.355Z
|
||||
card-last-score:: 1
|
||||
- **Simple Linear Regression** is the name given to the statistical technique that is used to model the dependency of a response variable on a **single** explanatory variable.
|
||||
- The word "simple" refers to the fact that a single explanatory variable is available.
|
||||
- Simple Linear Regression is appropriate if the **average** value of the response variable is a **linear** function of the explanatory, i..e, the underlying dependency of the response on the explanatory appears linear.
|
||||
- ## Strategy
|
||||
- 1. Propose a model
|
||||
2. Check the assumptions.
|
||||
3. Make some predictions.
|
||||
- The predicted value is often referred to as $\hat y$.
|
||||
- 4. Assess how useful it is.
|
||||
5. Improve it.
|
||||
- ## Interpreting the Slope & Intercept #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T19:34:57.106Z
|
||||
card-last-score:: 1
|
||||
- $b_1$ is the **slope**, which tells us how rapidly $\hat y$ changes with respect to $x$.
|
||||
- e.g., what is the change in the mean current per unit increase in wind speed.
|
||||
- $b_0$ is the **y-intercept**, which tells us where the line intercepts the $y$-axis when $x$ is 0.
|
||||
- e.g., what is the mean current when the wind speed is 0.
|
||||
- ### The Residual Standard Deviation ($s_e$) #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T19:35:04.870Z
|
||||
card-last-score:: 1
|
||||
- The standard deviation of the residuals $s_e$ (also known as the residual standard error) measures how much the points spread around the regression line.
|
||||
- You can interpret $s_e$ in the context of the data set -it is the typical error in the predictions made by the regression line.
|
||||
- The **line of best fit** is the line for which the sum of the squared **residuals** is the *smallest*, the **least squares** line.
|
||||
- Some residuals are positive, others are negative, and on average, they cancel each other out.
|
||||
- You can't assess how well the line fits by adding up all the residuals.
|
||||
- ()
|
||||
- ## Simple Linear Regression Model
|
||||
- $$Y_i = \beta_0 + \beta_1 x_i + \epsilon_i \text{ for } i =1, \cdots, n \text{ assuming } \epsilon_i \sim N(0, \sigma_e)$$
|
||||
- ### Features of this Model
|
||||
- $\beta_o£ (intercept) and $\beta_1$ (slope) are the population parameters of the model & must be estimated from the data as $b_0$ (**sample intercept**) and $b_1$ (**sample slope**).
|
||||
-
|
||||
-
|
||||
49
year2/semester1/logseq-stuff/pages/Counting.md
Normal file
49
year2/semester1/logseq-stuff/pages/Counting.md
Normal file
@ -0,0 +1,49 @@
|
||||
- #[[MA284 - Discrete Mathematics]]
|
||||
- No previous topic
|
||||
- **Next topic:** [[Principle of Inclusion-Exclusion]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- What is **Combinatorics**? #card
|
||||
card-last-interval:: 97.56
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2023-02-20T09:22:03.466Z
|
||||
card-last-reviewed:: 2022-11-14T20:22:03.466Z
|
||||
card-last-score:: 5
|
||||
- **Combinatorics** is the mathematics of *counting*.
|
||||
-
|
||||
- ## The Additive & Multiplicative Principles
|
||||
- ### The Additive Principle
|
||||
- What is the **Additive Principle**? #card
|
||||
card-last-interval:: 75.28
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2023-01-29T02:20:51.719Z
|
||||
card-last-reviewed:: 2022-11-14T20:20:51.720Z
|
||||
card-last-score:: 5
|
||||
- If an event $A$ can occur $m$ ways, and event $B$ can occur $n$ (disjoint) ways, then event "$A$ **or** $B$" can occur $m + n$ ways.
|
||||
- ### The Multiplicative Principle
|
||||
id:: 6336be87-7dea-4ba3-b7d0-c77a73bae948
|
||||
- What is the **Multiplicative Principle**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:42:09.219Z
|
||||
card-last-score:: 1
|
||||
id:: 6336be87-053a-4ea8-b9cd-9e16b2e801de
|
||||
- If event $A$ can occur $m$ ways, and each possibility allows for event $B$ to occur in $n$ (disjoint) ways, then the event "$A$ **and** $B$" can occur in $m \times n$ ways.
|
||||
id:: 6336be87-2faa-457f-b34f-e11f741673c7
|
||||
-
|
||||
- ## Counting with Sets
|
||||
- What is a **set**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T11:06:53.689Z
|
||||
card-last-reviewed:: 2022-11-14T20:06:53.690Z
|
||||
card-last-score:: 5
|
||||
- A **set** is a collection of things.
|
||||
- The items in a set are called *elements*.
|
||||
- A set is **unordered** and does not contain duplicates. i.e.:
|
||||
- $$\{a,b,c\} = \{b,a,c\} = \{a,a, c,b,b,b\}$$
|
||||
@ -0,0 +1,67 @@
|
||||
- #[[CT255 - Next Generation Technologies II]]
|
||||
- **Previous Topic:** [[Social Engineering]]
|
||||
- **Next Topic:** [[Block Ciphers & Stream Ciphers]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Groups, Rings, & Fields
|
||||
- In mathematics,
|
||||
- a **group** is a set equipped with a binary operation that is associative, has an identity element, and is such that every element has an inverse, e.g., $(\mathbb{Z}, +)$.
|
||||
- a **ring** is a set equipped with two binary operations satisfying properties analogous to those of addition & multiplication of integers, e.g. $(\mathbb{Z}, +, *)$.
|
||||
- a **field** is a set on which addition, subtraction, multiplication, & division are defined and behave as the corresponding operations on rational & real numbers do.
|
||||
-
|
||||
- # Diffie-Hellman Key Exchange
|
||||
- What is the **Diffie-Hellman Key Exchange**? #card
|
||||
card-last-interval:: 3.69
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-22T10:36:42.441Z
|
||||
card-last-reviewed:: 2022-11-18T18:36:42.441Z
|
||||
card-last-score:: 5
|
||||
- **Diffie-Hellman** provides **secure key exchange** between two partners.
|
||||
- The negotiated key is subsequently used for private key encryption / authentication.
|
||||
- It uses the multiplicative group of integers modulo $n$ $(\mathbb{Z} / n \mathbb{Z})^x$.
|
||||
- It is based on the difficulty of computing discrete logarithms over such groups, e.g.:
|
||||
- $$6^3 \text{ mod } 17 = 216 \text{ mod } 17 =12 \text{ (easy) }$$
|
||||
- $$12 = 6 ^y \text{ mod } 17 ? \text{ hard }$$
|
||||
- The core equation for the key exchange is
|
||||
- $$K = (A)^B \text{ mod } q$$
|
||||
- ## Diffie-Hellman: Global Public Elements
|
||||
- Select a prime number $q$ and positive and a positive integer $a$, where $a < q$ and $a$ is a **primitive root** of $q$.
|
||||
- What is a **primitive root**? #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-24T08:08:29.696Z
|
||||
card-last-reviewed:: 2022-11-21T13:08:29.697Z
|
||||
card-last-score:: 5
|
||||
- $a$ is a **primitive root** of $q$, if numbers $a \text{ mod } q, a^2 \text{ mod } q, \cdots , a^{q-1} \text{ mod } q$ are distinct integer values between $1$ and $(q-1)$ in some permutation, i.e., elements of $(\mathbb{Z} / q \mathbb{Z})^x$.
|
||||
- **Example:** $a = 3$ is a primitive root of $(\mathbb{Z} / 5\mathbb{Z})^x$, $a=4$ is not:
|
||||
background-color:: green
|
||||
- ## Generation of Secret-Key
|
||||
- Both users share a public prime number $q$ and primitive root $a$.
|
||||
- User A:
|
||||
- 1. Select secret number $XA$ with $XA < q$.
|
||||
2. Calculate public value $YA = a^{XA} \text{ mod } q$ (difficult to reverse).
|
||||
3. $YA$ is sent to User B.
|
||||
- User B:
|
||||
- 1. Select secret number $XB$ with $XB < q$.
|
||||
2. Calculate public value $YB = a^{XB} \text{ mod } q$ (difficult to reverse).
|
||||
3. $YB$ is sent to User A.
|
||||
- User A:
|
||||
- User A owns $XA$ and receives $YB$.
|
||||
- Generate secret key: $K = (YB)^{XA} \text{ mod } q$.
|
||||
- User B:
|
||||
- User B owns $XB$ and receives $YA$.
|
||||
- Generate secret key: $K = (YA)^{XB} \text{ mod } q$.
|
||||
- Both keys are identical.
|
||||
- ## Diffie-Hellman in Practice
|
||||
- The algorithm is used in tandem with a variety of secure network protocols.
|
||||
- Provision of secure end-to-end connection.
|
||||
- No endpoint authentication - you can't validate who you are talking to.
|
||||
- Modulus $p$ typically has a minimum length of 1024 bits.
|
||||
- ## DH & Man-in-the-Middle (MitM) Attacks
|
||||
- 
|
||||
- Mallory is a MitM attacker and performs message interception & message fabrication.
|
||||
- Mallory establishes two individual (secure) connections with Alice & Bob.
|
||||
- Neither Alice nor Bob are aware of Mallory's existence (as there is no authentication).
|
||||
-
|
||||
@ -0,0 +1,108 @@
|
||||
- #[[CT230 - Database Systems I]]
|
||||
- No previous topic
|
||||
- **Next Topic:** [[The Relational Model]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- What is a **database**? #card
|
||||
card-last-interval:: 64.01
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.52
|
||||
card-next-schedule:: 2023-01-24T13:09:54.692Z
|
||||
card-last-reviewed:: 2022-11-21T13:09:54.692Z
|
||||
card-last-score:: 5
|
||||
- A **database** is ^^a collection of related data.^^
|
||||
-
|
||||
- What is the **Database Approach**? #card
|
||||
card-last-interval:: 7.76
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 1.94
|
||||
card-next-schedule:: 2022-11-22T10:36:04.634Z
|
||||
card-last-reviewed:: 2022-11-14T16:36:04.634Z
|
||||
card-last-score:: 3
|
||||
- A **single repository** of data (which may be distributed) is maintained that is **defined once** and then accessed by various users via a **DBMS**.
|
||||
- ## Database Management Systems
|
||||
- What is a **DBMS**? #card
|
||||
card-last-interval:: 19.01
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-03T16:40:07.862Z
|
||||
card-last-reviewed:: 2022-11-14T16:40:07.862Z
|
||||
card-last-score:: 5
|
||||
- The **DataBase Management System (DBMS)** is a collection of programs that facilitates the process of ^^defining, constructing, & manipulating^^ databases for various applications.
|
||||
- ### DBMS Capabilities #card
|
||||
card-last-interval:: 19.01
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-03T16:44:40.304Z
|
||||
card-last-reviewed:: 2022-11-14T16:44:40.304Z
|
||||
card-last-score:: 3
|
||||
- 1. **Define** database (DDL)
|
||||
2. **Manipulate** database (SQL)
|
||||
3. **Control** redundancy
|
||||
4. **Restrict** unauthorised access
|
||||
5. **Enforce** integrity constraints
|
||||
6. Provide multiple user interfaces / **views**
|
||||
7. Provide **concurrent access**
|
||||
8. Provide mechanism for **recovery**
|
||||
9. Provide **back-up**
|
||||
10. Allows representation of complex relationships between data (For efficiency & optimisation reasons)
|
||||
-
|
||||
- ### Disadvantages of DBMS approach #card
|
||||
card-last-interval:: 23.43
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-12-08T02:39:24.701Z
|
||||
card-last-reviewed:: 2022-11-14T16:39:24.701Z
|
||||
card-last-score:: 3
|
||||
- Strict schema & multiple tables / relations
|
||||
- Complexity
|
||||
- Size
|
||||
- Cost of DBMS
|
||||
- Additional hardware costs
|
||||
- Cost of conversion
|
||||
- Performance
|
||||
- Higher impact of failure
|
||||
- ### DBMS Users #card
|
||||
card-last-interval:: 7.76
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 1.94
|
||||
card-next-schedule:: 2022-11-22T10:36:32.717Z
|
||||
card-last-reviewed:: 2022-11-14T16:36:32.718Z
|
||||
card-last-score:: 3
|
||||
- **Administrators (DBA)** - accounts, passwords, privileges. Requiring constant vigilance
|
||||
- **System Analysts** - "What's required to solve a problem? What does the business need?"
|
||||
- **Designers** - ER diagrams, mapping ER diagrams to tables
|
||||
- **Application Programmers** - creating tables, adding data, creating queries
|
||||
- **End users**
|
||||
-
|
||||
- What is **Database Abstraction**? #card
|
||||
card-last-interval:: 33.96
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.04
|
||||
card-next-schedule:: 2022-12-18T19:23:19.167Z
|
||||
card-last-reviewed:: 2022-11-14T20:23:19.167Z
|
||||
card-last-score:: 3
|
||||
- **Database Abstraction** refers to the hiding of the details of data storage that are not needed by most database users.
|
||||
- The aim is to separate user's views of the database from the way that it is "physically" represented.
|
||||
- 3 ways in which data can be described:
|
||||
- **External:** user's view
|
||||
- **Conceptual:** logical structure as seen by DBA
|
||||
- **Internal:** DBMS and OS view of data
|
||||
- What is the database **schema**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.52
|
||||
card-next-schedule:: 2022-11-18T20:24:46.045Z
|
||||
card-last-reviewed:: 2022-11-14T20:24:46.046Z
|
||||
card-last-score:: 5
|
||||
- The database **schema** is the ^^logical structure of the database.^^
|
||||
- What is the database **instance**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T11:00:02.004Z
|
||||
card-last-reviewed:: 2022-11-14T20:00:02.004Z
|
||||
card-last-score:: 5
|
||||
- The database **instance** is ^^the actual content of the database at some point in time.^^
|
||||
-
|
||||
-
|
||||
@ -0,0 +1,200 @@
|
||||
- #[[MA284 - Discrete Mathematics]]
|
||||
- **Previous Topic:** [[Introduction to Graph Theory]]
|
||||
- **Next Topic:** [[Convex Polyhedra]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Definitions
|
||||
- What is a **walk**? #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-26T07:16:18.888Z
|
||||
card-last-reviewed:: 2022-11-23T12:16:18.890Z
|
||||
card-last-score:: 5
|
||||
- A **walk** is a sequence of vertices such that consecutive vertices are adjacent.
|
||||
- What is a **trail**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:14:59.935Z
|
||||
card-last-score:: 1
|
||||
- A **trail** is a walk in which no edge is repeated.
|
||||
- What is a **path**? #card
|
||||
card-last-interval:: 0.9
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T17:22:40.523Z
|
||||
card-last-reviewed:: 2022-11-14T20:22:40.524Z
|
||||
card-last-score:: 3
|
||||
- A **path** is a trail in which no vertex is repeated, except possibly the first & last.
|
||||
- The path on $n$ vertices is denoted $P_n$.
|
||||
- ## Example
|
||||
- <img src="https://mermaid.ink/img/ICBmbG93Y2hhcnQgTFIKQigoQikpIC0tLSBBKChBKSkKQiAtLS0gQygoQykpCkMgLS0tIEUoKEUpKQpFIC0tLSBEKChEKSkKQiAtLS0gRSAtLS0gQQoK" />
|
||||
{{renderer :mermaid_uiukfrr}}
|
||||
- ```mermaid
|
||||
flowchart LR
|
||||
B((B)) --- A((A))
|
||||
B --- C((C))
|
||||
C --- E((E))
|
||||
E --- D((D))
|
||||
B --- E --- A
|
||||
|
||||
```
|
||||
- $(a,b,c,e,d)$ is a **walk**.
|
||||
- So too is $(a,b,e,a,b,c)$ (not a trail or a path).
|
||||
-
|
||||
- What is the **length** of a path? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:22:48.413Z
|
||||
card-last-score:: 1
|
||||
- The **length** of a path is the number of edges in the sequence.
|
||||
- ## Cycles & Circuits
|
||||
- What is a **cycle**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:50:16.908Z
|
||||
card-last-score:: 1
|
||||
- A **cycle** is a path that begins & ends at the same vertex, but no other vertex is repeated.
|
||||
- A cycle on $n$ vertices is denoted $C_n$.
|
||||
- What is a **circuit**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-22T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-21T13:05:28.290Z
|
||||
card-last-score:: 1
|
||||
- A **circuit** is a path that begins & ends at the same vertex, and no edge is repeated.
|
||||
- What does it mean if a graph is **connected**? #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T11:16:09.571Z
|
||||
card-last-reviewed:: 2022-11-14T16:16:09.572Z
|
||||
card-last-score:: 5
|
||||
- A graph is **connected** if there is a path between every pair of vertices.
|
||||
- What is the **degree** of a vertex? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-25T13:10:12.122Z
|
||||
card-last-reviewed:: 2022-11-21T13:10:12.123Z
|
||||
card-last-score:: 5
|
||||
- The **degree** of a vertex is the number of edges emanating from it.
|
||||
- If $v$ is a vertex, we denote its degree as $d(v)$.
|
||||
- ## Handshaking Lemma
|
||||
- If we know the degree of every vertex in the graph, then we know the number of edges. This is the **Handshaking Lemma**.
|
||||
- What is the **Handshaking Lemma**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:54:11.744Z
|
||||
card-last-score:: 1
|
||||
- In any graph, the sum of the degrees of vertices in the graph, is always twice the number of edges.
|
||||
- $$\sum_{v \in V} d(v) = 2|E|$$
|
||||
- # Types of Graphs
|
||||
- What is a **Complete** Graph? #card
|
||||
card-last-interval:: 0.9
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T17:23:00.989Z
|
||||
card-last-reviewed:: 2022-11-14T20:23:00.990Z
|
||||
card-last-score:: 3
|
||||
- A graph is **complete** if every pair of vertices is adjacent.
|
||||
- This family of graphs is very important.
|
||||
- Complete graphs are denoted $K_n$ - the complete graph on $n$ vertices.
|
||||
- What is a **Bipartite Graph**? #card
|
||||
card-last-interval:: 8.35
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-29T21:09:36.899Z
|
||||
card-last-reviewed:: 2022-11-21T13:09:36.899Z
|
||||
card-last-score:: 5
|
||||
- A graph is **bipartite** if it is possible to partition the vertex set, $V$, into two disjoint sets, $V_1$ & $V_2$, such that there are no edges between any two vertices in the same set.
|
||||
- What is a **Complete Bipartite** graph? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:51:45.394Z
|
||||
card-last-score:: 1
|
||||
- If a bipartite graph is such that *every* vertex in $V_1$ is connected to *every* vertex in $V_2$ (and vice versa), the graph is a **complete bipartite graph**.
|
||||
- If $|V_1| = m$ and $|V_2| = n$, we denote it $K_{m,n}$.
|
||||
- What is a **subgraph**? #card
|
||||
card-last-interval:: 3.05
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T21:23:07.436Z
|
||||
card-last-reviewed:: 2022-11-14T20:23:07.436Z
|
||||
card-last-score:: 5
|
||||
- We say that $G_1 = (V_1, E_1)$ is a **subgraph** of $G_2 = (V_2, E_2)$ provided $V_1 \subset V_2$ and $E_1 \subset E_2$.
|
||||
- What is an **induced subgraph**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-23T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-22T13:38:04.242Z
|
||||
card-last-score:: 1
|
||||
- We say that $G_1(V_1, E_1)$ is an **induced subgraph** of $G_2 = (V_2, E_2)$ provided that $V_1 \subset V_2$ and $E_2$ contains **all** edges of $E_1$ which join edges in $V_1$.
|
||||
-
|
||||
- # Planar Graphs
|
||||
- What is a **planar graph**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:19:45.615Z
|
||||
card-last-score:: 1
|
||||
- If you can sketch a graph such that none of its edges cross, it is a **planar graph**.
|
||||
- What is a **face**? #card
|
||||
card-last-interval:: 0.98
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T15:22:52.013Z
|
||||
card-last-reviewed:: 2022-11-14T16:22:52.013Z
|
||||
card-last-score:: 3
|
||||
- When a planar graph is drawn without edges crossing, the edges & vertices of the graph divide the plane into regions called **faces**.
|
||||
- The number of faces does not change no matter how you draw the graph, as long as no edges cross.
|
||||
-
|
||||
- ## Example
|
||||
- The graph $K_{2,3}$ is **planar**.
|
||||
background-color:: red
|
||||
- 
|
||||
- [[draws/2022-10-28-11-04-05.excalidraw]]
|
||||
- The planar representation $K_{2,3}$ has **3 faces** (the "outside" region counts as a face).
|
||||
- Give a planar representation of $K_4$, and count how many faces it has.
|
||||
background-color:: red
|
||||
- [[draws/2022-10-28-11-22-12.excalidraw]]
|
||||
- Why "face"?
|
||||
background-color:: red
|
||||
- [[draws/2022-10-28-11-25-20.excalidraw]]
|
||||
- # Euler's Formula for Planar Graphs #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:18:07.821Z
|
||||
card-last-score:: 1
|
||||
- For any ^^(connected) planar graph^^ with $v$ vertices, $e$ edges, and $f$ faces, we have:
|
||||
- $$v - e + f = 2$$
|
||||
- ## Outline of Proof
|
||||
- Start with $P_2$.
|
||||
- Here, $v=2$, $e = 1$, $f=1$. So $v-e+f=2$.
|
||||
- Any other graph can be made by adding vertices & edges (or just edges) to $P_2$.
|
||||
- Suppose $v-e+f=2$ for a graph.
|
||||
- If we add a new edge *with* a new vertex, then no new face is created, so $v-e+f$ does not change.
|
||||
- If we add a new edge *without* a new vertex, then $f$ will increase by 1, so again, $v-e+f$ does not change.
|
||||
- ## Example
|
||||
- Is it possible for a connected planar graph to have 5 vertices, 7 edges, and 3 faces? Explain.
|
||||
background-color:: red
|
||||
- No. Euler's formula tells us that $v-e+f=2$.
|
||||
- Here, $v=5$, $e=7$, $f=3$, so $v-e+f=1$.
|
||||
- Any such graph is **not planar**.
|
||||
-
|
||||
-
|
||||
24
year2/semester1/logseq-stuff/pages/Describing Data in R.md
Normal file
24
year2/semester1/logseq-stuff/pages/Describing Data in R.md
Normal file
@ -0,0 +1,24 @@
|
||||
- #[[ST2001 Labs]]
|
||||
- **Previous Topic:** [[Using R as a Calculator]]
|
||||
- **Next Topic:** null
|
||||
-
|
||||
- Most of our computation in R will be using data in table form, with rows & columns, which are often stored as a `data.frame` object.
|
||||
- The rows usually represent different *observations*, (e.g., humans, cars, etc.) and the columns represent different *variables* (features of the observation), (e.g., height, weight, etc.).
|
||||
-
|
||||
- What does `glimpse()` do? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-22T18:34:17.944Z
|
||||
card-last-reviewed:: 2022-11-18T18:34:17.945Z
|
||||
card-last-score:: 5
|
||||
- The `glimpse()` function gives us an overview of the dataset on each experimental unit.
|
||||
- What does `dim()` do? #card
|
||||
card-last-interval:: 29.99
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-12-14T19:04:53.617Z
|
||||
card-last-reviewed:: 2022-11-14T20:04:53.617Z
|
||||
card-last-score:: 5
|
||||
- The `dim()` function returns the number of rows & columns in a dataframe.
|
||||
-
|
||||
170
year2/semester1/logseq-stuff/pages/Device Management.md
Normal file
170
year2/semester1/logseq-stuff/pages/Device Management.md
Normal file
@ -0,0 +1,170 @@
|
||||
- #[[CT213 - Computer Systems & Organisation]]
|
||||
- **Previous Topic:** [[Memory Management]]
|
||||
- **Next Topic:**
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Device Management
|
||||
- What is **Device Management**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:17:50.052Z
|
||||
card-last-score:: 1
|
||||
- **Device Management** is the process of managing the implementation, operation, & maintenance of physical and/or virtual devices.
|
||||
- It is a broad term that includes various administrative tools & processes for the maintenance & upkeep of a computing, network, mobile, and/or virtual device.
|
||||
- The status of any computing device (internal or external) may be either **free** or **busy**.
|
||||
- If a device requested by a process is free at a specific instant of time, the operating system allocates it to the process.
|
||||
- How does the Operating System manage devices? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-24T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-23T12:20:20.630Z
|
||||
card-last-score:: 1
|
||||
- The OS manages devices with the help of:
|
||||
- **Device Controllers:** Hardware components that contain some buffer registers to store the data temporarily.
|
||||
- **Device Drivers:** Software programs that are used by an operating system to control the functioning of various devices in a uniform manner.
|
||||
- The device controller used in a device management operation includes three different registers: **command**, **status**, & **data**.
|
||||
- The other major responsibility of the device management function is to implement **Application Programming Interfaces (APIs)**.
|
||||
- Each device controller is specific to a particular device.
|
||||
- The device driver implementation will be device specific.
|
||||
- Why?
|
||||
- To provide correct commands to the controller.
|
||||
- To interpret the Controller Status Register (CSR) correctly.
|
||||
- To transfer data to and from device controller data registers as required for correct device operation.
|
||||
- # Device Communication Approaches
|
||||
- A computer must have a way of detecting the arrival of **any type of input**.
|
||||
- There are various ways to enable I/O devices to communicate with the processor: #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:18:19.796Z
|
||||
card-last-score:: 1
|
||||
- ## Polling #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:18:45.126Z
|
||||
card-last-score:: 1
|
||||
- ### Implementation
|
||||
- **Periodically checking status** of the device to see if it is time for the next I/O operation.
|
||||
- The I/O device simply puts the information in a Status register, and the processor must come & get the information.
|
||||
- ### Efficiency
|
||||
- It's the simplest way for an I/O device to communicate with the processor.
|
||||
- Most of the time, devices will not require attention and when one does, it will have to wait until it is next interrogated by the polling program.
|
||||
- Much of the processor's time is wasted on unnecessary polls.
|
||||
- ## Interrupts #card
|
||||
card-last-interval:: 0.98
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T15:20:44.422Z
|
||||
card-last-reviewed:: 2022-11-14T16:20:44.423Z
|
||||
card-last-score:: 3
|
||||
- ### Implementation
|
||||
- A device controller puts out an **interrupt signal** when it needs the CPU's attention.
|
||||
- When the CPU receives an interrupt, it **saves its current state** and invokes the appropriate interrupt handler using the interrupt vector (addresses of OS routines to handle various events).
|
||||
- When the interrupting device has been dealt with, the CPU continues with its original task, as if it had never been interrupted.
|
||||
- ### Efficiency
|
||||
- Interrupts allow the processor to deal with events that can happen at any time.
|
||||
- Interrupts remove the need for the CPU to constantly check the Controller Status Register.
|
||||
- ## Direct I/O #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-24T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-23T12:20:09.419Z
|
||||
card-last-score:: 1
|
||||
- ### Implementation
|
||||
- Uses software which explicitly transfers data to/from the **controller's data registers**.
|
||||
- Separate I/O & memory address spaces.
|
||||
- The control indicates whether address information is for memory or I/O.
|
||||
- 
|
||||
- ### Efficiency
|
||||
- Reduced CPU utilisation (no caches or buffers).
|
||||
- ## Memory Mapped I/O
|
||||
- ### Implementation
|
||||
- Direct connection between I/O device and certain main memory locations so that I/O device can **transfer blocks of data** to/from the memory without going through the CPU.
|
||||
- OS allocates buffer in memory to the I/O device to send data to the CPU.
|
||||
- I/O device operates **asynchronously** with CPU.
|
||||
- Interrupts CPU when finished.
|
||||
- ### Efficiency
|
||||
- Memory mapped I/O is ideal for most high-speed I/O devices like disks, communcation interfaces, etc.
|
||||
-
|
||||
- # Buffering
|
||||
- ## Design Objectives
|
||||
- ### Efficiency
|
||||
- Most I/O devices are extremely slow compared to the processor and main memory.
|
||||
- Buffering is one way to deal with this issue.
|
||||
- ### Generality
|
||||
- It is desirable to handle all devices in a uniform & consistent manner.
|
||||
- in the way user processes see the devices.
|
||||
- In the way the OS manages the I/O devices & operations.
|
||||
- What is **Buffering**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:15:10.546Z
|
||||
card-last-score:: 1
|
||||
- **Buffering** is the technique by which the device manager can keep slower I/O devices busy during times when a process is not requiring I/O operations.
|
||||
- What is **Input Buffering**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:16:35.294Z
|
||||
card-last-score:: 1
|
||||
- **Input Buffering** involves having the input device read information into the primary memory before the process requests it.
|
||||
- What is **Output Buffering**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:18:11.922Z
|
||||
card-last-score:: 1
|
||||
- **Output Buffering** involves saving information in memory and then writing it to the device while the process continues execution.
|
||||
- ## Hardware Level Buffering #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:19:51.036Z
|
||||
card-last-score:: 1
|
||||
- Consider a simple character device controller that reads a single byte from a router for each input operation.
|
||||
- ### Normal Operation
|
||||
- 1. Read occurs.
|
||||
2. The driver passes a read command to the controller.
|
||||
3. The controller instructs the device to put the next character into one-byte data controller's register.
|
||||
4. The process calling for the byte **waits** operation to complete, and then retrieves the character from the data register.
|
||||
- {:height 257, :width 174}
|
||||
- ### Buffered Operation
|
||||
- The next character to be read by the process has already been placed into the data register, even though the next process has not yet been called for the read operation.
|
||||
- Adding a hardware buffer to the controller **decreases** the amount of time the process has to wait.
|
||||
- ### Driver-Level Buffering #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:51:53.356Z
|
||||
card-last-score:: 1
|
||||
- This is generally called **double buffering**.
|
||||
- One buffer is for the driver to store the data while waiting for the higher layers to read it.
|
||||
- The other buffer is to store data from the lower-level modules.
|
||||
- {:height 371, :width 217}
|
||||
- ### Using Multiple Buffers #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-24T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-23T12:16:44.978Z
|
||||
card-last-score:: 1
|
||||
- The number of buffers is extended from 2 to $n$.
|
||||
- The data producer writes into the buffer $i$ while the data consumer is reading from the buffer $j$.
|
||||
- In this configuration:
|
||||
- If $i<j$: buffers $[j+1, n-1]$ & $[0, i-1]$ are full.
|
||||
- If $j<i$: buffers $[j_1, i-1]$ are full.
|
||||
- This is known as **circular buffering**.
|
||||
- 
|
||||
@ -0,0 +1,198 @@
|
||||
- #[[ST2001 - Statistics in Data Science I]]
|
||||
- **Previous Topic:** [[Random Variables]]
|
||||
- **Next Topic:** [[The Normal Distribution]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- Often, the observations generated by different statistical experiments have the same type of behaviour.
|
||||
- In general, only a handful of important probability distributions are needed to describe many of the discrete random variables encountered in practice.
|
||||
-
|
||||
- # Bernoulli Trials
|
||||
collapsed:: true
|
||||
- What is a **Bernoulli Trial**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:08:48.931Z
|
||||
card-last-score:: 1
|
||||
- A **Bernoulli Trial** is a random experiment with just two outcomes - success / failure.
|
||||
- For a single trial, random variable:
|
||||
- $$X = \begin{cases}1, & \text{success,} \\0, & \text{failure.}\end{cases}$$
|
||||
- $P(X = 1) = p$ and $P(X=0) = 1 -p$, where $p$ is the success probability, or more compactly:
|
||||
- $$P(X = x) = p^x{(1-p)^{1-x}} \ \ \ \ \ x = 0,1$$
|
||||
- What is the **expected value** of a Bernoulli Trial? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:20:53.147Z
|
||||
card-last-score:: 1
|
||||
- $$E[X] = (0)(1-p)+(1)p = p$$
|
||||
- What is the **variance** of a Bernoulli Trial? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:24:49.061Z
|
||||
card-last-score:: 1
|
||||
- $$Var(X) = p(1-p)$$
|
||||
- ## Bernoulli Trial Assumptions #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:24:43.818Z
|
||||
card-last-score:: 1
|
||||
- The outcomes of the trials are mutually **independent**.
|
||||
- The probability of success $p$ is **constant** over trials.
|
||||
- Note that these assumptions may not always be appropriate assumptions.
|
||||
- ## Example: Camera Flash Tests
|
||||
id:: 6368f276-bc7e-4d91-b7fb-c5b34c4c6feb
|
||||
- The time to recharge the flash is tested in three mobile phone cameras. The probability that a camera passes the test is 0.8, and the cameras perform independently.
|
||||
background-color:: green
|
||||
- The random variable $X$ denotes the number of cameras that pass the test. The last column of the tables shows the values of $X$ assigned to each outcome of the experiment.
|
||||
background-color:: green
|
||||
- What is the probability that the first & second cameras pass the test, and the third one fails?
|
||||
background-color:: green
|
||||
- 
|
||||
- Each camera test can be treated as a **Bernoulli Trial**.
|
||||
- $$P(PPF) = (0.8)(0.8)(0.2) = 0.128$$
|
||||
- What is the probability that two cameras pass the test in three trials?
|
||||
background-color:: green
|
||||
- How many ways can this event happen?
|
||||
- $$\binom{n}{r} = \frac{n!}{r!(n-r)!} = \frac{3!}{2!(3-2)!} = 3$$
|
||||
- What is the probability of this event?
|
||||
- 0.128 for each of the three ways.
|
||||
- Probability = $3(0.128) = 0.383$.
|
||||
- This is an example of the **Binomial Distribution**.
|
||||
-
|
||||
- # The Binomial Distribution
|
||||
- What is a **binomial random variable**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:25:45.051Z
|
||||
card-last-score:: 1
|
||||
- A random experiment consists of $n$ Bernoulli trials such that:
|
||||
- 1. The trials are independent.
|
||||
2. Each trial results in only two possible outcomes, labelled as "success" & "failure".
|
||||
3. The probability of a success in each trial, denotes as $p$, remains constant.
|
||||
- The random variable $X$ that equals the number of trials that result in a success has a **binomial random variable** with parameters $0 < p < 1$ and $n = 1, 2, \cdots$.
|
||||
- The **probability mass function** of $X$ is
|
||||
- $$f(x) = \binom{n}{x}p^x (1-p)^{n-x} \ \ \ \ \ x = 0,1,\cdots, n$$
|
||||
- ## Example: Camera Flash Tests
|
||||
- See ((6368f276-bc7e-4d91-b7fb-c5b34c4c6feb)) for whole question.
|
||||
background-color:: green
|
||||
- Calculate the probability of 2 passes in 3 tests.
|
||||
background-color:: green
|
||||
- We are given that $n = 3$ and $p = 0.8$.
|
||||
- Use the Binomial Distribution formula where $X$ is the number of passes:
|
||||
- $$P(X = 2) = \binom{3}{2}(0.8)^2(0.2)^1 = 3(0.128) = 0.384$$
|
||||
- ## Example: Organic Pollution
|
||||
id:: 6368f570-83e7-4642-a881-7ccd40bb0399
|
||||
- Each sample of water has a 10% chance of containing a particular organic pollutant. Assume that the sample are independent with regard to the presence of the pollutant.
|
||||
background-color:: green
|
||||
- Find the probability that, in the next 18 samples, exactly 2 contain the pollutant.
|
||||
background-color:: green
|
||||
- Let $X$ denote the number of samples that contain the pollutant in the next 18 samples analysed. Then $X$ is a binomial random variable with $p = 0.1$ and $n = 18$.
|
||||
- $$P(X = 2) = \binom{18}{2}(0.1)^2(0.9)^{18-2} = 153(0.1)^2(0.9)^16 = 0.2835$$
|
||||
- Determine the probability that $3 \leq X < 7$.
|
||||
background-color:: green
|
||||
- $$X = 3,4,5,6$$
|
||||
- $$P(3 \leq X < 7) = P(X=3) + P(X=4) + P(X=5) + P(X=6)$$
|
||||
- $$ \text{or}$$
|
||||
- $$P(3 \leq X < 7) = \sum^6_{x=3} \binom{18}{x}(0.1)^x(0.9)^{18-x}$$
|
||||
- $$ = 0.168 + 0.070 + 0.022 + 0.005 = 0.265$$
|
||||
- ## Binomial Distributions in R
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:21:52.419Z
|
||||
card-last-score:: 1
|
||||
- `dbinom(x, size, prob)`, where `x` is the number of events required, `size` is the total number of trials, & `prob` is the probability of the event occurring.
|
||||
- ### Example: Organic Pollution
|
||||
- In ((6368f570-83e7-4642-a881-7ccd40bb0399)), `x=2`, `size=18`, & `p=0.10`.
|
||||
background-color:: green
|
||||
- ```R
|
||||
dbinom(x=2, size=18, prob=0.1)
|
||||
[1] 0.2835121
|
||||
```
|
||||
- ## Binomial Mean & Variance #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-22T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-21T13:08:26.634Z
|
||||
card-last-score:: 1
|
||||
- If $X$ is a **binomial random variable** with parameters $p$ & $n$:
|
||||
- The **mean** & **variance** of the binomial distribution $b(x; n,p)$ are
|
||||
- $$\mu = np \text{ and } \sigma^2 = npq \text{, where } q = 1-p$$
|
||||
- ## Chebyshev's Inequality
|
||||
- What is **Chebyshev's Inequality**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:23:31.513Z
|
||||
card-last-score:: 1
|
||||
- **Chebyshev's Inequality** provides an estimate as to where a certain percentage of observations will lie relative to the mean once the **standard deviation** is known.
|
||||
- For example, at least 75% of values will lie within two standard deviations of the mean.
|
||||
-
|
||||
- # Poisson Distribution
|
||||
- What are **Poisson Experiments**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-22T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-21T13:05:40.034Z
|
||||
card-last-score:: 1
|
||||
- Experiments yielding numerical values of a random variable $X$, the number of outcomes occurring during a given time interval or in a specified region, are called **Poisson Experiments**.
|
||||
- The given time interval may be of any length, such as a minute, a day, a week, a month, or even a year.
|
||||
- A Poisson Experiment is derived from the **Poisson Process** and possesses the following properties:
|
||||
- The number of outcomes occurring one time interval or specified region of space is **independent** of the number that occur in any other disjoint time interval or region. In this sense, we say that the Poisson Process "has no memory".
|
||||
- The probability that a single outcome will occur during a very short time interval or in a small region is **proportional** to the **length** of the time interval or the size of the region, and does not depend on the number of outcomes occurring outside this time interval or region.
|
||||
- The probability that more than one outcome will occur in such a short time interval or fall in such a small region is **negligible**.
|
||||
- What is the **Poisson Distribution**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-22T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-21T13:06:55.129Z
|
||||
card-last-score:: 1
|
||||
- The random variable $X$ that equals the number of events in a Poisson Process is a **Poisson Random Variable** with parameter $\lambda > 0$, and the probability density function is
|
||||
- $$f(x) = \frac{e^{-\lambda}\lambda^x}{x!} \text{ for } x = 0,1,2,3,\cdots$$
|
||||
- ## Mean & Variance of Poisson Distribution
|
||||
- If $\lambda$ is the average number of successes occurring in a given time interval or region in the Poisson Distribution, then the **mean** & the **variance** of the Poisson distribution are both equal to $\lambda$.
|
||||
- Mean = $\lambda$, variance = $\lambda$.
|
||||
- A one parameter distribution.
|
||||
- ## Poisson Density Functions for Different Means
|
||||
- 
|
||||
- If the variance is much greater than the mean, then the Poisson Distribution would not be a good model for the distribution of the random variable.
|
||||
- ## Poisson Example: Calculations for Wire Flaws
|
||||
- Suppose that the number of flaws on a thin copper wire follows a Poisson Distribution with a mean of 2.3 flaws per millimetre.
|
||||
background-color:: green
|
||||
- Find the probability of exactly 2 flaws in 1mm of wire.
|
||||
background-color:: green
|
||||
- $$P(X = 2) = \frac{e^{-2.3}2.3{2}}{2!} = 0.265$$
|
||||
- ## Poisson Example: Car Park
|
||||
- A car park has 3 entrances, $A$, $B$, & $C$. The number of cars per hour entering through each of these is Poisson-distributed with mean $\lambda_A = 1.5$, $\lambda_B = 1.0$, and $\lambda_C = 2.5$. Arrivals at each entrance are **independent**.
|
||||
background-color:: green
|
||||
- $T$ is the total number of cars entering in an hour.
|
||||
- $$T \sim \text{ Poisson}(\lambda_A + \lambda_B + \lambda_C) \equiv \text{Poisson}(1.5 + 1.0 + 2.5) \equiv \text{Poisson}(5)$$
|
||||
- $$P(T = 4) = \frac{e^{-5} 5^4}{4!} = 0.1755$$
|
||||
- ## Sum of Independent Poisson Random Variables #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:54:18.796Z
|
||||
card-last-score:: 1
|
||||
- If $X_1, X_2, \cdots, X_n$ are independently Poisson distributed with parameters $\lambda_1, \lambda_2, \cdots, \lambda_n$ then
|
||||
- $$T = X_1 + X_2 + \cdots + X_n \text{ is Poisson}(\lambda_1 + \lambda_2 + \cdots + \lambda_n)$$
|
||||
- and
|
||||
- $$E[T] = \lambda_1 + \lambda_2 + \cdots + \lambda_n$$
|
||||
- and
|
||||
- $$\text{Var}(T) = \lambda_1 + \lambda_2 + \cdots + \lambda_n$$
|
||||
-
|
||||
340
year2/semester1/logseq-stuff/pages/Entity Relationship Models.md
Normal file
340
year2/semester1/logseq-stuff/pages/Entity Relationship Models.md
Normal file
@ -0,0 +1,340 @@
|
||||
- #[[CT230 - Database Systems I]]
|
||||
- **Previous Topic:** [[Aggregate Clauses, Group By, & Having Clauses]]
|
||||
- **Next Topic:** [[Joins & Union Queries]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- What are **Data Models**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-19T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-18T18:34:07.942Z
|
||||
card-last-score:: 1
|
||||
- **Data models** are concepts to describe the structure of a database.
|
||||
- They comprise:
|
||||
- High level or logical models;
|
||||
- Representational / Implementational data models;
|
||||
- Physical data models.
|
||||
- Data models allow for database abstraction.
|
||||
- What are **ER Models**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-19T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-18T18:34:30.174Z
|
||||
card-last-score:: 1
|
||||
- **Entity Relationship Models** are a top-down approach to database design that provide a way to *model the data* that will be stored in a system. The models are then used to *create tables* in the relational model.
|
||||
- ER Models are used to identify:
|
||||
- [1] The important data to be stored in a database called **entities**.
|
||||
- [2] The **relationships** between the entities.
|
||||
- [3] The **attributes** of entities.
|
||||
- [4] The **constraints** of relationships & entities.
|
||||
-
|
||||
- # ER Model Notation
|
||||
- A number of different notations can be used to represent the same model.
|
||||
- Chen Notation.
|
||||
- IE Crow's Foot Notation.
|
||||
- UML.
|
||||
- Integrated Definition 1. Extended (IDEF1X).
|
||||
-
|
||||
- The original (Chen) notation uses diamonds, rectangles, and elipses.
|
||||
- This is easier to hand-draw, so it is useful in an exam situation.
|
||||
- It is less implementation-oriented than other notations.
|
||||
-
|
||||
- # Some Definitions
|
||||
collapsed:: true
|
||||
- ## Entities
|
||||
collapsed:: true
|
||||
- What is an **entity type**? #card
|
||||
card-last-interval:: 3.05
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T21:24:38.127Z
|
||||
card-last-reviewed:: 2022-11-14T20:24:38.127Z
|
||||
card-last-score:: 5
|
||||
- An **entity type** is a collection of *entity instances* that share common properties or charcteristics.
|
||||
- It is a group of objects, with the same properties, which are identified as having an independent existence.
|
||||
- 
|
||||
- What is an **entity instance**? #card
|
||||
card-last-interval:: 11.34
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-26T00:47:05.851Z
|
||||
card-last-reviewed:: 2022-11-14T16:47:05.851Z
|
||||
card-last-score:: 5
|
||||
- An **entity instance** or **entity occurrence** is a single, uniquely identifiable occurrence of an entity type (e.g., row in a table).
|
||||
- 
|
||||
- ## Relationships
|
||||
- What is a **relationship type**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:30:24.202Z
|
||||
card-last-score:: 1
|
||||
collapsed:: true
|
||||
- A **relationship type** is a set of meaningful relationships among entity types.
|
||||
- **Chen's Notation:** A diamond shape is used to name the relationship. 1 and M/N are used for the "1" and "many" sides respectively.
|
||||
- **Crow's Foot Notation:** The titular "crow's foot" is used as the representation of "many", and one line is used for the representation of "1".
|
||||
- 
|
||||
- **Example:** employee "works for" department. department "has" employee.
|
||||
- 
|
||||
- What is a **relationship instance**? #card
|
||||
collapsed:: true
|
||||
card-last-interval:: 29.04
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-12-10T11:35:42.874Z
|
||||
card-last-reviewed:: 2022-11-11T11:35:42.874Z
|
||||
card-last-score:: 3
|
||||
- A **relationship instance** or **relationship occurrence** is ==a uniquely identifiable association which includes one occurrence from each participating entity type==; reading left to right and right to left.
|
||||
- **Example:**
|
||||
- Left-to-Right: John Smith "works for" Research department.
|
||||
- Right-to-Left: Research department "has" John Smith.
|
||||
- What is the **degree** of a relationship type? #card
|
||||
card-last-interval:: 10.6
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-22T01:30:24.968Z
|
||||
card-last-reviewed:: 2022-11-11T11:30:24.969Z
|
||||
card-last-score:: 5
|
||||
collapsed:: true
|
||||
- Whenever an attribute of one entity type refers to another entity type, some relationship exists.
|
||||
- The **degree** of a relationship type is ^^the number of participating entity types.^^
|
||||
- Relationship types may have certain constraints.
|
||||
- What is the **Cardinality Ratio**? #card
|
||||
collapsed:: true
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-20T15:15:43.390Z
|
||||
card-last-reviewed:: 2022-11-17T20:15:43.391Z
|
||||
card-last-score:: 5
|
||||
- The **cardinality ratio** specifies ^^the number of relationship instances that an entity can participate in.^^
|
||||
- The possible cardinality ratios for binary relationship types are:
|
||||
- $1:1$, "one to one" - at most one instance of entity $A$ is associated with one instance of entity $B$.
|
||||
- $1:N$, "one to many" - for one instance of entity $A$, there are 0 or more instances of entity $B$.
|
||||
- $M:N$, "many to many" - for one instance of entity $A$, there are 0 or more instances of entity $B$, and for one instance of entity $B$, there are 0 or more instances of entity $A$.
|
||||
-
|
||||
- ### Structural Constraints on Relationships
|
||||
- Often, we may know the min & max of the cardinalities.
|
||||
- Example: limit on the number of books that can be borrowed from a library.
|
||||
- What are **Structural Constraints**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-25T13:06:19.301Z
|
||||
card-last-reviewed:: 2022-11-21T13:06:19.301Z
|
||||
card-last-score:: 3
|
||||
- **Structural constraints** specify a pair of integer numbers *(min, max)* for each entity participating in a relationship.
|
||||
- Examples: (0, 1), (1, 1), (1, N)., (1, 7).
|
||||
-
|
||||
- ## Attributes
|
||||
collapsed:: true
|
||||
- What are **Attributes**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T20:19:08.122Z
|
||||
card-last-score:: 1
|
||||
collapsed:: true
|
||||
- **Attributes** are ^^named property^^ or characteristic of an entity.
|
||||
- Each entity has a set of attributes associated with it.
|
||||
- Several types of attributes exist:
|
||||
- Key.
|
||||
- Composite.
|
||||
- Derived.
|
||||
- Multi-valued.
|
||||
- **Notation:**
|
||||
- **Chen:** An oval enclosing the name of the attribute.
|
||||
- 
|
||||
- **Crow:** Listed in the entity box.
|
||||
- 
|
||||
- What are **key attributes**? #card
|
||||
card-last-interval:: 5.52
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-20T04:37:24.678Z
|
||||
card-last-reviewed:: 2022-11-14T16:37:24.678Z
|
||||
card-last-score:: 3
|
||||
collapsed:: true
|
||||
- Each entity type must have an attribute or set of attributes that ^^uniquely identifies^^ each instance from other instances of the same type.
|
||||
- A **candidate key** is an attribute (or combination of attributes) that uniquely identifies each instance of an entity type.
|
||||
- A **primary key (PK)** is a candidate key that has been selected as the identifier for an entity type.
|
||||
- What is a **composite attribute**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:46:49.892Z
|
||||
card-last-score:: 1
|
||||
collapsed:: true
|
||||
- A **composite attribute** is an attribute that is composed of several atomic (simple) attributes.
|
||||
- If the composite attribute is referenced as a whole only, then there is no need to subdivide it into component attributes, otherwise you should divide it:
|
||||
- 
|
||||
- What is a **derived attribute**? #card
|
||||
card-last-interval:: 31.05
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-12-15T21:12:18.376Z
|
||||
card-last-reviewed:: 2022-11-14T20:12:18.376Z
|
||||
card-last-score:: 5
|
||||
collapsed:: true
|
||||
- A **derived attribute** is an attribute whose values can be determined from another attribute.
|
||||
- For Chen's notation, the notation is a *dotted oval*.
|
||||
- 
|
||||
- For Crow's Foot notation, derived attributes can be represented by enclosing the attribute in [square brackets], e.g., [age].
|
||||
- What is a **multi-valued attribute**? #card
|
||||
collapsed:: true
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T20:18:04.379Z
|
||||
card-last-score:: 1
|
||||
- A **multi-valued attribute** is an attribute which has lower & upper bounds on the number of values for an individual entry.
|
||||
- For Chen's notation, multi-valued attributes can be represented by one oval inside another.
|
||||
- 
|
||||
- For Crow's Foot notation, multi-valued attributes can be represented by enclosing the attribute in {curly brackets}.
|
||||
- E.g., {skills}.
|
||||
-
|
||||
-
|
||||
- # Total & Partial Participation
|
||||
collapsed:: true
|
||||
- What is **Total Participation**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-18T20:26:04.052Z
|
||||
card-last-reviewed:: 2022-11-14T20:26:04.052Z
|
||||
card-last-score:: 3
|
||||
- **Total Participation** (Mandatory Participation): ==All instances of an entity must participate in the relationship==, i.e., *every* entity instance in one set *must* be related to an entity instance in the second via the relationship.
|
||||
- For example, the entity "Student" must have **total participation** in the relationship "enrolled" with the entity "Course" - each student *must* be enrolled in a course.
|
||||
- What is **Partial Participation**? #card
|
||||
card-last-interval:: 7.45
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-22T02:28:50.125Z
|
||||
card-last-reviewed:: 2022-11-14T16:28:50.125Z
|
||||
card-last-score:: 3
|
||||
- **Partial Participation** (Optional Participation): Some subset of instances of an entity will participate in the relationship, but not all, i.e., *some* entity instances in one set are related to an entity instance in the second via the relationship.
|
||||
- For example, the entity "Course" would have a **partial participation** in the relationship "enrolled" with the entity "Student" - a course might not have any students enrolled in it.
|
||||
- ## Chen's Notation for Participation #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-23T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-22T13:38:31.943Z
|
||||
card-last-score:: 1
|
||||
- In both total & partial participation, the line(s) are drawn from the participating entity to the relationship (the diamond) to indicate the participation of that instance from that entity in the relationship,
|
||||
- **Total Participation:** Double parallel lines.
|
||||
- 
|
||||
- **Partial Participation:** Single line.
|
||||
- 
|
||||
- Examples:
|
||||
- 
|
||||
-
|
||||
- ## Crow's Foot Notation for Participation #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T20:19:01.789Z
|
||||
card-last-score:: 1
|
||||
collapsed:: true
|
||||
- Use the idea of **Ordinality / Optionality**.
|
||||
- **Optionality of 0:** If an entity $A$ has partial participation in a relationship to entity $B$, then $A$ is associated with 0 or more instances of entity $B$, so the **optionality sign** goes beside $B$.
|
||||
- The optionality sign for an **Optionality of 0** is a **bar**: $|$
|
||||
- **Optionality of 1:** If an entity $A$ has full participation in a relationship to entity $B$, then $A$ is associated with at least 1 or more of $B$, so the **optionality sign** goes beside $B$.
|
||||
- The optionality sign for an **Optionality of 1** is a **circle** or "o": $\bigcirc$
|
||||
- [And vice-versa.]
|
||||
- In Crow's Foot notation, there is no diamond, so there is always a direct relationship line between the entities.
|
||||
- The **optionality sign** is drawn on this line.
|
||||
- The optionality drawn beside some entity $A$ refers to how an instance of entity $B$ is related to entity $A$.
|
||||
- That is, whether $B$ can be involved partially (0) or not (1).
|
||||
- Example in *Right to Left* Relationships:
|
||||
- 
|
||||
-
|
||||
- ## Note on Weak Entities
|
||||
- **Note:** ^^A **weak entity type** always has a total participation constraint.^^
|
||||
- We need to show the "identifying relationship".
|
||||
- 
|
||||
- ### Chen's Notation for Weak Entities #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-19T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-18T18:34:03.316Z
|
||||
card-last-score:: 1
|
||||
collapsed:: true
|
||||
- **Entity:** Double rectangle.
|
||||
- **Relationship:** Double diamond.
|
||||
- The weak entity has full participation in the relationship.
|
||||
- 
|
||||
-
|
||||
- ### Crow's Foot Notation for Weak Entities #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T19:36:10.883Z
|
||||
card-last-score:: 1
|
||||
collapsed:: true
|
||||
- In Crow's Foot Notation, we can represent the **weak entity** as a normal entity, but do not choose any attributes as the primary key.
|
||||
- For an attribute that partially determines the entity instances, we choose the "required" option.
|
||||
- We usually represent the relationship between entities using a **solid line**.
|
||||
- This indicates that it is an "identifying" relationship.
|
||||
- 
|
||||
-
|
||||
-
|
||||
- In general, with entities, there may be two valid solutions, one with a weak entity, and one without.
|
||||
- There is not a huge difficulty if you do not identify weak entities in a solution so long as all the entities have **primary attributes**.
|
||||
- It may be slightly non-optimal in terms of introducing an additional primary key that is not needed, but this is not a huge problem for us at this level.
|
||||
-
|
||||
- # Entities or Multi-Valued Attributes?
|
||||
collapsed:: true
|
||||
- Sometimes, it may not be clear whether something should be modelled as a multi-valued attribute or an entity.
|
||||
- Both may be equally correct, as long as you represent all the information that you are asked to.
|
||||
- You may see (very little) difference between the two approaches if you map either approach to tables in a database.
|
||||
-
|
||||
- # Steps to Create an ER Model
|
||||
- 1. Identify entities.
|
||||
2. Identify relationships between entities.
|
||||
3. Draw entities & relationships.
|
||||
4. Add attributes to entities (& relationships, if appropriate).
|
||||
5. Add cardinalities to relationships.
|
||||
6. Add participation constraints (total or partial) to relationships.
|
||||
7. Check that all entities have primary keys identified.
|
||||
-
|
||||
- # Mapping ER Models to Tables in the Relational Model
|
||||
- Once you have you ER diagram, you now need to convert it into a set of tables so that you can implement it in a relational mode.
|
||||
- Example: As MySQL tables using `CREATE TABLES` commands.
|
||||
- This stage is called **Mapping ER Models to Tables in the Relational Model**, and it specifies a set of rules that must be followed in a certain order.
|
||||
- The rules specified here are based on **Chen's Notation**.
|
||||
- ## Steps
|
||||
- [1] For each entity, create a table $R$ that includes all the **simple** attributes of the entity.
|
||||
- [2] For strong entities, choose a key attribute as the primary key of the table.
|
||||
- [3] For weak entities $R$, include the primary key attributes of the table that corresponds to the owner as foreign key attributes of $R$.
|
||||
- The primary key of $R$ is a combination of the primary key of the owner and the partial key of the weak entity type.
|
||||
- The relationship of the weak & strong entity is generally taken care of by this step.
|
||||
- [4] For each **binary** $1:1$ relationship, identify entites $S$ & $T$ that participate in the relation.
|
||||
- If applicable, choose the entity that has **total participation** in the relation.
|
||||
- Include the primary key of the other relation as the foreign key in this table.
|
||||
- Include any attributes of the relationship as attributes of the chosen table.
|
||||
- If both entities have total participation in the relationship, you can choose either one for the foreign key and proceed as above, or you can map two entities & their associated attributes & relationship attributes into one table.
|
||||
- [5] For each **binary** $1:N$ relationship, identify the table $S$ that represents the $N$ side and the table $T$ that represents the $1$ side.
|
||||
- Include the primary key of table $T$ as a foreign key in $S$ such that each entity on the $N$ side is related to at most one entity instance on the $1$ side.
|
||||
- Include any attributes of the relationship as attributes of $S$.
|
||||
- For recursive $1:N$ relationships, choose the primary key of the table and include it as a foreign key in the same table with a different name.
|
||||
- [6] For each $M:N$ relationship, create a new table $S$ to represent the relationship.
|
||||
- Include the primary keys of the tables that represent the participating entity types as foreign keys in $S$ - their combination will form the primary key of $S$.
|
||||
- Also include in $S$ any attributes of the relationship.
|
||||
- For a recursive $M:N$ relationship, both foreign keys come from the same table (give different names to each) and become the new primary key.
|
||||
- [7] For each **multi-valued attribute** $A$ of an entity $S$, create a new table $R$.
|
||||
- $R$ will include:
|
||||
- An attribute corresponding to $A$.
|
||||
- The primary key of $S$, which will be a foreign key in $R$. Call this $K$.
|
||||
- The primary key of $R$ is a combination of $A$ & $K$.
|
||||
-
|
||||
-
|
||||
@ -0,0 +1,9 @@
|
||||
- # Exam Timetable
|
||||
- | **Date** | **Time** | **Module** |
|
||||
| 2022-12-08 Thursday | 13:00 - 15:00 | CT230 |
|
||||
| 2022-12-09 Friday | 13:00 - 15:00 | CT213 |
|
||||
| 2022-12-13 Tuesday | 09:30 - 11:30 | CT2106 |
|
||||
| 2022-12-15 Thursday | 09:30 - 11:30 | MA284 |
|
||||
| | 16:30 - 18:30 | ST20021 |
|
||||
-
|
||||
-
|
||||
282
year2/semester1/logseq-stuff/pages/Exploratory Data Analysis.md
Normal file
282
year2/semester1/logseq-stuff/pages/Exploratory Data Analysis.md
Normal file
@ -0,0 +1,282 @@
|
||||
- #[[ST2001 - Statistics in Data Science I]]
|
||||
- **Previous Topic:** null
|
||||
- **Next Topic:** [[Sampling]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- ## What is / are Statistics?
|
||||
collapsed:: true
|
||||
- What is a **statistic**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-11-26T13:40:07.042Z
|
||||
card-last-reviewed:: 2022-11-22T13:40:07.042Z
|
||||
card-last-score:: 5
|
||||
- A **statistic** is any quantity computed from sample data.
|
||||
- What is the **Science of Statistics**?
|
||||
card-last-interval:: 10.24
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-10-13T16:37:15.281Z
|
||||
card-last-reviewed:: 2022-10-03T11:37:15.284Z
|
||||
card-last-score:: 5
|
||||
- The collecting, classifying, summarising, organising, analysing, estimation, and interpretation of information.
|
||||
- What is the **role of statistics**?
|
||||
card-last-interval:: 9.28
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-10-09T18:10:56.000Z
|
||||
card-last-reviewed:: 2022-09-30T12:10:56.000Z
|
||||
card-last-score:: 5
|
||||
- The field of statistics deals with the collection, presentation, analysis, and use of data to:
|
||||
- make decisions
|
||||
- solve problems
|
||||
- design products & processes
|
||||
- Statistics is the ^^science of uncertainty.^^
|
||||
- What is the **role of probability** in statistics?
|
||||
- **Probability** provides the framework for the study & application of statistics.
|
||||
-
|
||||
- ## Types of Statistics
|
||||
collapsed:: true
|
||||
- What is **Descriptive Statistics**? #card
|
||||
card-last-interval:: 41.44
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-30T04:36:51.695Z
|
||||
card-last-reviewed:: 2022-11-18T18:36:51.696Z
|
||||
card-last-score:: 3
|
||||
- **Descriptive Statistics** is the science of summarising data, both numerically & graphically.
|
||||
- The analysis methods applicable depends on the variable being measured and the research questions that you are trying to answer.
|
||||
- What is **Inferential Statistics**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-11-26T13:37:26.721Z
|
||||
card-last-reviewed:: 2022-11-22T13:37:26.722Z
|
||||
card-last-score:: 3
|
||||
- **Inferential Statistics** is the science of using the ^^information in your sample^^ to ^^infer^^ something about the population of statistics.
|
||||
-
|
||||
- ## Important Terms
|
||||
collapsed:: true
|
||||
- What is an **experimental unit**? #card
|
||||
collapsed:: true
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:44:53.701Z
|
||||
card-last-reviewed:: 2022-11-14T16:44:53.701Z
|
||||
card-last-score:: 5
|
||||
- An **experimental unit** / individual is a single object upon which we collect data. e.g., a person, thing, transaction, or event.
|
||||
- What is a **population**? #card
|
||||
collapsed:: true
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:49:52.921Z
|
||||
card-last-reviewed:: 2022-11-14T16:49:52.922Z
|
||||
card-last-score:: 5
|
||||
- A **population** is a ^^collection of experimental units^^ / individuals that we are interested in studying.
|
||||
- What is a **sample**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:51:36.002Z
|
||||
card-last-reviewed:: 2022-11-14T16:51:36.002Z
|
||||
card-last-score:: 5
|
||||
- A **sample** is a subset of experimental units from the population.
|
||||
- What is a **variable**? #card
|
||||
collapsed:: true
|
||||
card-last-interval:: 10.64
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-11-25T07:35:49.776Z
|
||||
card-last-reviewed:: 2022-11-14T16:35:49.776Z
|
||||
card-last-score:: 5
|
||||
- A **variable** is a ^^characteristic or property of an individual experimental unit^^.
|
||||
- A variable may be measured, or more generally "observed" on each individual.
|
||||
- What is **Qualitative Data**? #card
|
||||
card-last-interval:: 8.72
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-11-23T09:37:05.082Z
|
||||
card-last-reviewed:: 2022-11-14T16:37:05.082Z
|
||||
card-last-score:: 3
|
||||
- **Qualitative Data** is data which can be classified into categories.
|
||||
- Two types of Qualitative Data:
|
||||
- **Ordinal:** ordered qualitative data - e.g., a grade,
|
||||
- **Nominal:** unordered qualitative data - e.g., a gender, a method of payment
|
||||
- What is **Quantitative Data**? #card
|
||||
card-last-interval:: 30.47
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.76
|
||||
card-next-schedule:: 2022-12-15T07:21:06.252Z
|
||||
card-last-reviewed:: 2022-11-14T20:21:06.252Z
|
||||
card-last-score:: 5
|
||||
- **Quantitative Data** is data in the form of counts or numbers - it cannot be classified into categories.
|
||||
- Two types of Quantitative Data:
|
||||
- **Discrete:** non-divisible, single points of data, **counts** - e.g., number of texts sent
|
||||
- **Continuous:** measurements that, if placed on a number scale, can be placed in an infinite number of spaces between two whole numbers - e.g., age, rent, temperature
|
||||
-
|
||||
- Pie charts make data very difficult to interpret & read - **don't use them**.
|
||||
-
|
||||
- ## Numerical Summaries
|
||||
- ### Central Tendency
|
||||
- What is a **numerical summary**? #card
|
||||
card-last-score:: 5
|
||||
card-repeats:: 5
|
||||
card-next-schedule:: 2023-02-06T22:21:22.599Z
|
||||
card-last-interval:: 84.1
|
||||
card-ease-factor:: 2.76
|
||||
card-last-reviewed:: 2022-11-14T20:21:22.599Z
|
||||
- A **numerical summary** is a way of summarising categorical data using a frequency count or percentage.
|
||||
- How do you calculate the **sample mean**? #card
|
||||
card-last-interval:: 29.26
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T22:47:38.996Z
|
||||
card-last-reviewed:: 2022-11-14T16:47:38.997Z
|
||||
card-last-score:: 5
|
||||
- Suppose that the observations in a sample are $x_1,\ x_2,\ ...\ ,\ x_n$. The **sample mean**, denoted by $\bar{x}$, is:
|
||||
- $$\bar{x} = \sum_{i=1}^{n}\frac{x_i}{n}=\frac{x_1+x_2+...+x_n}{n}$$
|
||||
:LOGBOOK:
|
||||
CLOCK: [2022-09-12 Mon 18:35:39]
|
||||
:END:
|
||||
- ^^The sample mean is **sensitive** to extreme values^^
|
||||
- How do you calculate the **sample median**? #card
|
||||
card-last-interval:: 8.72
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-11-23T09:49:27.636Z
|
||||
card-last-reviewed:: 2022-11-14T16:49:27.637Z
|
||||
card-last-score:: 5
|
||||
- Given that the observations in a sample are $x_1,\ x_2,\ ...\ ,\ x_n$, arranged in **increasing order** of magnitude, the **sample median** is:
|
||||
- $$\bar{x} = \begin{cases}x_{(n+1)/2}, & \text{if $n$ is odd},\\ \frac{1}{2}(x_{n/2} + x_{n/2+1}), &\text{if $n$ is even.} \\ \end{cases}$$
|
||||
- ^^The sample median is **not** sensitive to extreme values.^^
|
||||
- What is the **mode**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:51:42.814Z
|
||||
card-last-reviewed:: 2022-11-14T16:51:42.815Z
|
||||
card-last-score:: 5
|
||||
- The **mode** is the most frequent observation in a dataset.
|
||||
- ### Variation
|
||||
collapsed:: true
|
||||
- What is the **range** of a sample? #card
|
||||
collapsed:: true
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:51:53.283Z
|
||||
card-last-reviewed:: 2022-11-14T16:51:53.283Z
|
||||
card-last-score:: 5
|
||||
- The **range** of a sample is the **maximum** - **minimum**.
|
||||
- The range is a ^^poor measure of spread and is badly affected by outliers.^^
|
||||
- The range is also ^^badly affected by outliers.^^
|
||||
- #### Interquartile Range
|
||||
- What is the **interquartile range** of a sample? #card
|
||||
card-last-interval:: 41.44
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-26T06:18:35.901Z
|
||||
card-last-reviewed:: 2022-11-14T20:18:35.901Z
|
||||
card-last-score:: 5
|
||||
- The **interquartile range** is the middle 50% of the data.
|
||||
- Therefore, it is ^^robust to outliers.^^
|
||||
- To calculate the **IQR**, first split the data in 4 quarters and subtract the value at $Q_3$ from the value at $Q_1$.
|
||||
- $$IQR=Q_3-Q_1$$
|
||||
- 
|
||||
- #### Tukey's Method for IQR
|
||||
- There are also many other methods for calculating IQR.
|
||||
- 1. Put data in **ascending** order.
|
||||
2. The **lower quartile** ($Q_1$)is the **median** of the **lower** 50% of the data, including the median.
|
||||
3. The **upper quartile** ($Q_3$) is the **median** of the **upper** 50% of the data, including the median.
|
||||
- #### Standard Deviation #card
|
||||
card-last-interval:: 4.14
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-27T15:16:26.346Z
|
||||
card-last-reviewed:: 2022-11-23T12:16:26.350Z
|
||||
card-last-score:: 5
|
||||
- A common measure of spread is the **standard deviation**, which takes into account how far *each* data value is from the mean.
|
||||
- A **deviation** is the distance of a datapoint from the mean.
|
||||
- Since the sum of all the deviations would be zero, we square each deviation and find an average of the deviations called the **variance**.
|
||||
- We then get the positive square root of the **sample variance** to get the the **sample standard deviation**, which is preferable to the sample variance, as the sample variance is in squared units.
|
||||
- The **standard deviation** is ^^sensitive to outliers.^^
|
||||
- How do you calculate the **sample variance**, and hence, the **sample standard deviation**? #card
|
||||
card-last-interval:: 10.97
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-25T15:37:19.443Z
|
||||
card-last-reviewed:: 2022-11-14T16:37:19.444Z
|
||||
card-last-score:: 3
|
||||
- The **sample variance**, denoted by $s^2$, is given by:
|
||||
- $$s^2=\sum_{i=1}^{n} \frac{(x_i - \bar{x})^2}{n-1}$$
|
||||
- The **sample standard deviation**, denoted by $s$, is the **positive square root** of $s^2$, that is:
|
||||
- $$s=\sqrt{s^2}$$
|
||||
- ### Shape
|
||||
- #### Graphical Summaries of Data
|
||||
- Depends on the variable of interest.
|
||||
- **Categorical** response variable -> bar chart or pie chart.
|
||||
- **Categorical** response variable ^^with an explanatory variable^^ -> grouped bar chart.
|
||||
- **Continuous** response variable -> histogram, boxplot, densit plot.
|
||||
- **Continuous** response variable ^^with an explanatory variable^^ -> grouped boxplot.
|
||||
-
|
||||
- What is a **boxplot**? #card
|
||||
card-last-interval:: 5.52
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-20T04:34:53.491Z
|
||||
card-last-reviewed:: 2022-11-14T16:34:53.492Z
|
||||
card-last-score:: 3
|
||||
- A **boxplot** is a graphical display showing centre, spread, shape, & outliers.
|
||||
- It displays the **5-number summary**:
|
||||
- *min, Q1, median, Q3, max*
|
||||
- 
|
||||
- What is a **histogram**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:00:35.072Z
|
||||
card-last-score:: 1
|
||||
- **Histograms** are useful to show the general shape, location, and spread of data values.
|
||||
- Representation by *area*.
|
||||
- **Construction**
|
||||
- Determine range of data *minimum, maximum*.
|
||||
- Split into convenient intervals or *bins*.
|
||||
- Usually use 5 to 15 intervals.
|
||||
- Count number of observations in each interval - *frequency*.
|
||||
- When talking about the shape of the data, make sure to address the following 3 questions:
|
||||
- 1. Does the histogram have a single, central hump or several well-separated bumps?
|
||||
2. Is the histogram or boxplot **symmetric**, or more spread out in one direction (skewed)?
|
||||
3. Any unusual features? e.g.., outliers, spikes.
|
||||
- 
|
||||
- 
|
||||
-
|
||||
- #### Explanatory & Response Variables
|
||||
collapsed:: true
|
||||
- To identify the **explanatory** variable in a pair of variables, identify which of the two is suspected of affecting the other and plan an appropriate analysis
|
||||
- explanatory variable -might effect-> response variable
|
||||
- continent -might effect-> life expectancy.
|
||||
-
|
||||
- ## R Markdown
|
||||
- What is **R Markdown**? #card
|
||||
card-last-interval:: 28.93
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-12-13T14:49:15.636Z
|
||||
card-last-reviewed:: 2022-11-14T16:49:15.637Z
|
||||
card-last-score:: 5
|
||||
- **R Markdown** is a file format for making ^^dynamic documents in R.^^
|
||||
- R Markdown is written in Markdown and contains chunks of embedded R code (data management, summaries, graphics, analysis & interpretation) all in one document.
|
||||
- Documents can be **knitted** to HTML, PDF, Word, and many other formats.
|
||||
- ### Key Benefits of R Markdown
|
||||
- Makes it easy to produce statistical reports with code, analysis, outputs, and write-up all in one place.
|
||||
- Perfect for reproducible research.
|
||||
- Easy to convert to different document types.
|
||||
- ### Structure
|
||||
- R Markdown contains **three** types of content:
|
||||
- A **YAML Header**.
|
||||
- Text, formatted with Markdown.
|
||||
- Code chunks.
|
||||
3
year2/semester1/logseq-stuff/pages/Extra-Curriculars.md
Normal file
3
year2/semester1/logseq-stuff/pages/Extra-Curriculars.md
Normal file
@ -0,0 +1,3 @@
|
||||
- ### [[日本語]]
|
||||
- ### [[Irish Sign Language]]
|
||||
-
|
||||
222
year2/semester1/logseq-stuff/pages/File Organsiation.md
Normal file
222
year2/semester1/logseq-stuff/pages/File Organsiation.md
Normal file
@ -0,0 +1,222 @@
|
||||
- #[[CT230 - Database Systems I]]
|
||||
- **Previous Topic:** [[Query Processing & Optimisation]]
|
||||
- **Next Topic:**
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- Generally, we can assume that for a non-trivial relational database that the entire database will not fit in the main memory (RAM).
|
||||
- Note: Newer database system architectures, in-memory databases (such as SAP Hanna), manage their data through virtual memory, relying on the OS to manage the movement of data to & from the main memory through the OS paging mechanism.
|
||||
- One of the DBMS's tasks is to manage the physical organisation (storage & retrieval) of the tuples (rows) in each table in the database.
|
||||
- This is called **File Organisation**.
|
||||
- What is **File Organisation**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-16T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-15T18:42:32.857Z
|
||||
card-last-score:: 1
|
||||
- A database **file organisation** is the way in which tuples from a table are physically arranged in secondary storage to facilitate the storage of data and read/write requests by users (via queries).
|
||||
- A number of factors to consider, including:
|
||||
- Support of fast access of data - moving to/from secondary storage.
|
||||
- Cost.
|
||||
- Efficient use of secondary storage space.
|
||||
- Provision for table growth (when new tuples are added).
|
||||
- What is a **file**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-16T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-15T18:42:28.412Z
|
||||
card-last-score:: 1
|
||||
- A **file** is a collection of data stored in bulk.
|
||||
- In DBMS, we have referred to these files as *tables* or *relations*.
|
||||
- In DBMS, we know that such tables contain a sequence of **tuples**, where each tuple contains a **sequence of bytes** and is subdivided into **attributes** or **fields**. Each attribute contains a specific **piece of information**. Associated with each attribute is a **data type**.
|
||||
- In File Systems, we refer to these tuples as **records** containing **fields**.
|
||||
- # Records
|
||||
- Each recorder often begins with a *header* - a fixed-length region that stores information about the record such as:
|
||||
- Pointer to the database schema.
|
||||
- Length of the record.
|
||||
- Timestamp indicating the time the record was last modified or read.
|
||||
- Pointers to the fields of the record.
|
||||
- ## Size of records/tuples
|
||||
- **Fixed Length:** All records (tuples) in a file (table) exactly the same size.
|
||||
- **Variable Length:** Different records (tuples) in a file (table) have different size.
|
||||
- # File Organisation Issues
|
||||
- How can these records be organised to store in a **compact** manner on devices of limited capacity and provide convenient & quick access by programs?
|
||||
- # Blocks
|
||||
- Different terminology is used but generally speaking a Block = a Frame = a Page, where records from a file are assigned to Blocks/Pages/Frames.
|
||||
- Relational DBMS use the terminology of a **block**.
|
||||
- Therefore, a table can also be defined as a collection of blocks where each block contains a collection of records.
|
||||
- What is a **block**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-17T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-16T21:17:50.239Z
|
||||
card-last-score:: 1
|
||||
- A **block** is the unit of data transfer between secondary storage & memory.
|
||||
- The block size $B$ is fixed.
|
||||
- Records of a file must be allocated to blocks.
|
||||
- Typically, the block size is larger than the record size, so each block will contain a number of records.
|
||||
- Some files may have very large records that cannot fit in one block, so they **span** recrods over a number of blocks.
|
||||
- A number of blocks is typically associated with a table.
|
||||
- Blocks also have a header that holds information about the block such as:
|
||||
- Links to one or more blocks associated with the table.
|
||||
- Which table (in the schema) the blocks belong to.
|
||||
- Timestamp of last access to block (read or write).
|
||||
- What is the **Blocking Factor**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T09:46:11.528Z
|
||||
card-last-score:: 1
|
||||
- The **Blocking Factor** is the average number of records that fit per block.
|
||||
- Given a block size $B$ (in bytes) and record size $R$ (in bytes), then with $B \geq R$, we can fit $\text{floor} \left( \frac{B}{R} \right)$ records per block.
|
||||
- We must ensure that the header information is also accounted for.
|
||||
- ### Example
|
||||
- With unspanned memory organisation and $B = 1024 \text{ Bytes}$ (once header information is stored) and $R = 100 \text{ Bytes (and of fixed length)}$, the blocking factor is $\text{floor} \left( \frac{1024}{100} \right) = 10$.
|
||||
- ## Spanned vs Unspanned Organisations
|
||||
- In **Spanned Organisation**, records can span more than one block.
|
||||
- In **Unspanned Organisation**, records are not allowed to cross block boundaries.
|
||||
- So can only use when $B \geq R$ (i.e., when block size is greater than record size).
|
||||
- ## Why use blocking?
|
||||
- Say we need to retrieve a file with 1000 records.
|
||||
- If not blocked, then we would need 1000 data transfers.
|
||||
- If blocked with a blocking factor of 10, and records are stored one after another in blocks, then the same operation requires 100 data transfers.
|
||||
- # Operations Performed on a File
|
||||
- All the operations that we have been performing with SQL code can be performed on a file:
|
||||
- Scan or fetch all records.
|
||||
- Search records that satisfy an equality condition (i.e., find specific records).
|
||||
- Search records where a value in the record is within a certain range.
|
||||
- Insert records.
|
||||
- Delete records.
|
||||
- # Steps to Search for a Records on a Disk #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T09:45:33.206Z
|
||||
card-last-score:: 1
|
||||
- 1. Locate the relevant blocks.
|
||||
2. Move these blocks to main memory buffers.
|
||||
3. Search through block(s) looking for the required records.
|
||||
4. At worst (*the worst case*), we may have to retrieve and check through all the blocks for the record.
|
||||
- Generally, when accessing records, to support record-level operations we must:
|
||||
- Keep track of the **blocks** associated with a file.
|
||||
- Keep track of the **free space** on the blocks.
|
||||
- Keep track of the **records** on a block.
|
||||
- # Options for Organising Records
|
||||
- Heap file organisation (unordered).
|
||||
- Sequential file organisation (ordered).
|
||||
- Hashing/hashed file organisation.
|
||||
- Indexed file organisation (Primary, Clustered, B-Trees, B+ Trees).
|
||||
- ## Heap File Organisation #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T09:46:39.719Z
|
||||
card-last-score:: 1
|
||||
- **Approach:** Any record can be placed in any block where there is space for the record (no ordering of records).
|
||||
- **Insertion:** The last disk block associated with the file (table) is copied into the buffer and the record is added; the block copied back to disk.
|
||||
- **Searching:** Must search all blocks (linear search).
|
||||
- **Deletion:** Find the block with the record (linear search); delete the link to the record.
|
||||
- ### Advantages
|
||||
- Insertion is efficient & easy - the last disk block is copied into the buffer and the record is added; the block is copied back to the disk.
|
||||
- ### Disadvantages
|
||||
- Searching is inefficient - must search all blocks (linear search).
|
||||
- Deleting is inefficient - search first; delete and then leave unused space in the block if using the "easy" insert approach.
|
||||
- ## Sequential File Organisation #card
|
||||
card-last-interval:: 0.98
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-18T08:45:18.181Z
|
||||
card-last-reviewed:: 2022-11-17T09:45:18.183Z
|
||||
card-last-score:: 3
|
||||
- **Approach:** Records are stored in *sequential* order, based on the value of some key of each record - often the primary key.
|
||||
- We usually use an **index** with sequential file organisation.
|
||||
- Sequential File Organisation allows records to be read in sorted order.
|
||||
- ### Advantages
|
||||
- Reading records in order is efficient.
|
||||
- Searching is efficient on the key field (binary search).
|
||||
- Easy to find the "next record".
|
||||
- ### Disadvantages
|
||||
- Insertion & deletion is expensive as records must remain physically ordered.
|
||||
- Pointer chains are used (part of the header information).
|
||||
- Searching is inefficient on a non-key field.
|
||||
- ## Hashing / Hashed File Organisation #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-17T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-16T21:17:57.726Z
|
||||
card-last-score:: 1
|
||||
- A **hash function** is computed on some attributes of each record (often a key value).
|
||||
- The output of the hash function is the **block address** where the record should be placed.
|
||||
- 
|
||||
- ### Hash Functions
|
||||
- A common hash function is the `MOD` or modulus function where `a MOD b` or `a % b` returns the remainder on dividing `a` by `b`, i.e. integer division.
|
||||
- ### Criteria for Choosing the Hash Function
|
||||
- Should be easy & quick to compute.
|
||||
- Should uniformly distribute hash addresses across the available space.
|
||||
- Picking a prime number for the mod function helps with this, but cannot guarantee it.
|
||||
- Should anticipate file growth (insertions & deletions) so that only a fraction of each block is initially filled, thus leaving room to insert new records.
|
||||
- ### Collisions
|
||||
- However, at any stage, two or more key field values can hash to the same location.
|
||||
- If there is no room to place a record, this is called a **collision**.
|
||||
- If a collision occurs, and there is no space in the block for a new record, then the record must find a new location.
|
||||
- This is called **collision resolution**.
|
||||
- One approach to collision resolution is **Linear Probing**.
|
||||
- Hash function returns block location $i$ for the record.
|
||||
- If there is no room in block $i$, check block $i+1$, $i+2$, etc. until a block with room is found.
|
||||
- ## Indexed File Organisation #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T09:46:30.122Z
|
||||
card-last-score:: 1
|
||||
- Indexing speeds up operations that are not efficiently supported by the basic file organisation.
|
||||
- Consists of **index entries**.
|
||||
- Each index entry consists of:
|
||||
- Index key.
|
||||
- Record or block pointer.
|
||||
- The index entries are placed on the disk, either in sequential **sorted order (ordered indices)** or hashed order.
|
||||
- A complete index may be able to reside in main memory.
|
||||
- ### To Access a Record Using Indexing Key
|
||||
- 1. Retrieve the index file.
|
||||
2. Search through it for the required field (based on the index key value).
|
||||
3. Answer the query or return to secondary storage for the block which contains the required record.
|
||||
- ### Dense vs Sparse Indices #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-17T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-16T21:17:44.546Z
|
||||
card-last-score:: 1
|
||||
- An index is **dense** if it contains an entry for every record in the file.
|
||||
- A dense index may be created for any index key.
|
||||
- A **sparse** (or non-dense) index contains an entry for each block rather than an entry for every record in the file.
|
||||
- Sparse indices can only be used if the records are assigned to blocks in sorted (sequential) order based on the primary index key.
|
||||
- A sparse index is called a **primary index**.
|
||||
- ### More on Primary Indices
|
||||
- The total number of entries in a primary index is the same as the total number of **blocks** in the ordered file.
|
||||
- The first record in each block is called the **anchor record** of the block.
|
||||
- #### Advantages
|
||||
- Fewer index entries than records, so the index file is smaller.
|
||||
- #### Disadvantages
|
||||
- Insertions & deletions are a problem - may have to change anchor record.
|
||||
- Searching may take longer.
|
||||
- ### Clustered & Secondary Indices #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T09:46:03.592Z
|
||||
card-last-score:: 1
|
||||
- Records that are logically related are physically stored close together on the disk (i.e., in the same blocks or consecutive blocks).
|
||||
- Records are physically ordered on a non-key field that does not have a distinct value for each record.
|
||||
- The clustering index consists of:
|
||||
- A clustering field value.
|
||||
- A block pointer to the first block that has a record with that value for the clustering field.
|
||||
-
|
||||
73
year2/semester1/logseq-stuff/pages/Firebase Functions.md
Normal file
73
year2/semester1/logseq-stuff/pages/Firebase Functions.md
Normal file
@ -0,0 +1,73 @@
|
||||
- #[[CT216 - Software Engineering I]]
|
||||
- **Previous Topic:** [[Introduction to NodeJS]]
|
||||
- **Next Topic:** [[Introduction to Firestore]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- **Firebase Functions** is a compute service that lets you run code without provisioning or managing servers.
|
||||
- Similar to AWS Lambda, Azure Functions, etc.
|
||||
- It runs your code only when needed and scales automatically, from a few requests per day to thousands per second.
|
||||
- You pay only for the compute time you consume - there is no charge when your code is not running.
|
||||
- # HTTP Requests
|
||||
- ## HTTP Verbs
|
||||
- `GET` and `POST` are HTTP request methods to transfer data from client to server.
|
||||
- Both can be used to send requests & receive responses.
|
||||
- `PUT` is used to update / replace, `DELETE` is used to delete, & `PATCH` is used to partially update / modify.
|
||||
- ### `GET`
|
||||
- `GET` is designed to request data from a specified resource.
|
||||
- `GET` requests can be cached.
|
||||
- `GET` requests remain in the browser history (you can go back).
|
||||
- `GET` can't be used to send binary data, like images or word documents to the server.
|
||||
- `GET` requests can be bookmarked.
|
||||
- `GET`requests have length restrictions.
|
||||
- `GET` requests should only be used to retrieve data.
|
||||
- Using `GET`, data can be sent to the server by adding name=value pairs at the end of the URL, i.e., Querystring.
|
||||
- ### `POST`
|
||||
- `POST` is designed to submit data to the specified resource.
|
||||
- `POST` requests are never cached.
|
||||
- `POST` requests do not remain in the browser history.
|
||||
- `POST` requests cannot be bookmarked.
|
||||
- `POST` requests have no restrictions on data length.
|
||||
- The `POST` method can be used to send ASCII as well as binary data.
|
||||
- Form data is often sent to the server via a `POST` request.
|
||||
- ### `GET` vs `POST`
|
||||
- Use `GET` if you are requesting a resource.
|
||||
- You may need to send some data to get the correct response back, but in general the idea is to `GET` a resource.
|
||||
- Use `POST` if you want to send data to the server.
|
||||
- ## Request Structure #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:50:44.830Z
|
||||
card-last-score:: 1
|
||||
- All HTTP requests have three main parts.
|
||||
- ### Request Line
|
||||
- HTTP Method (`GET`, `POST`, etc.).
|
||||
- URL - the address of the resource that is being requested.
|
||||
- HTTP version.
|
||||
- ### Headers
|
||||
- Additional information passed between the browser & the server, i.e., cookies, browser version, OS version, auth tokens, content-type.
|
||||
- ### Message Body
|
||||
- Client & server use the message body to transmit data back & forth between each other.
|
||||
- `POST` requests will usually have data in the body.
|
||||
- `GET` requests leave the message data empty.
|
||||
- ## Postman Client
|
||||
- When writing backend APIs, it's often necessary to test it quickly.
|
||||
- You don't want to have to write a client-side request to test each API.
|
||||
- Sometimes, you may even want to pass in values which would take even longer to code up.
|
||||
- Postman can help.
|
||||
- Postman is good for testing APIs without having to write client-side code to make the requests.
|
||||
- It will work for all request methods, i.e., `GET`, `POST`, `PUT`. etc.
|
||||
- You can code the backend, independent of the frontend.
|
||||
- # JSON
|
||||
- What is **JSON**? #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T11:23:52.503Z
|
||||
card-last-reviewed:: 2022-11-14T16:23:52.503Z
|
||||
card-last-score:: 5
|
||||
- **JavaScript Object Notation (JSON)** is an open, human & machine readable standard that facilitates data interchange.
|
||||
- Along with XML, JSON is the main data interchange format on the web.
|
||||
- Firestore uses JSON documents to store records of information.
|
||||
-
|
||||
196
year2/semester1/logseq-stuff/pages/First Java Code.md
Normal file
196
year2/semester1/logseq-stuff/pages/First Java Code.md
Normal file
@ -0,0 +1,196 @@
|
||||
- #[[CT2106 - Object-Oriented Programming]]
|
||||
- **Previous Topic:** [[Introduction to Java]]
|
||||
- **Next Topic:** [[More Java Code]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- What is the **structure of a class**? #card
|
||||
card-last-interval:: 21.53
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-12-01T00:46:31.046Z
|
||||
card-last-reviewed:: 2022-11-09T12:46:31.046Z
|
||||
card-last-score:: 3
|
||||
- Every class has the following structure:
|
||||
- ```java
|
||||
public class ClassName
|
||||
{
|
||||
Fields
|
||||
Constructors
|
||||
Methods
|
||||
}
|
||||
```
|
||||
- ## Fields
|
||||
- What are **Fields**? #card
|
||||
card-last-interval:: 86.42
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2023-02-09T06:22:08.706Z
|
||||
card-last-reviewed:: 2022-11-14T20:22:08.706Z
|
||||
card-last-score:: 5
|
||||
- **Fields**, also known as **instance variables**, store values for an object.
|
||||
- Fields define the state of an object.
|
||||
- In BlueJ, use *Inspect* to view the state.
|
||||
- Some values change frequently, others rarely, or not at all.
|
||||
- ## Encapsulation
|
||||
- What is **Encapsulation**? #card
|
||||
card-last-interval:: 9.68
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-11-24T08:35:40.664Z
|
||||
card-last-reviewed:: 2022-11-14T16:35:40.665Z
|
||||
card-last-score:: 5
|
||||
- In **encapsulation**, the ^^variables of a class will be hidden from other classes^^ and can only be accessed through the methods of their current class.
|
||||
- This is also known as **data hiding**.
|
||||
- Why use encapsulation? #card
|
||||
card-last-interval:: 22.66
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.38
|
||||
card-next-schedule:: 2022-12-07T11:20:26.959Z
|
||||
card-last-reviewed:: 2022-11-14T20:20:26.960Z
|
||||
card-last-score:: 5
|
||||
- In OOP, ^^each object is responsible for its own data.^^
|
||||
- This allows an object to have greater control over which data is available to be viewed externally, and how external objects can mutate the object's state.
|
||||
- ### Encapsulation Type: Private
|
||||
- What is the effect of making a field **private**? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-11-17T15:33:20.443Z
|
||||
card-last-reviewed:: 2022-10-20T08:33:20.443Z
|
||||
card-last-score:: 5
|
||||
- Making a field **private** encapsulates their values inside their object.
|
||||
- No external class or object can access a private field.
|
||||
-
|
||||
- ## Constructors
|
||||
- What are **constructors**? #card
|
||||
card-last-interval:: 25.4
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-12-10T01:49:12.088Z
|
||||
card-last-reviewed:: 2022-11-14T16:49:12.088Z
|
||||
card-last-score:: 3
|
||||
- Constructors:
|
||||
- Initialise an object.
|
||||
- Have the same name as their class.
|
||||
- Have a close association with the fields:
|
||||
- They contain the initial values stored in the fields.
|
||||
- They contain the parameter values often used for these.
|
||||
- What is the point of the keyword `this`? #card
|
||||
card-last-score:: 5
|
||||
card-repeats:: 4
|
||||
card-next-schedule:: 2022-12-18T07:50:05.102Z
|
||||
card-last-interval:: 33.64
|
||||
card-ease-factor:: 2.9
|
||||
card-last-reviewed:: 2022-11-14T16:50:05.103Z
|
||||
- The `this` keyword refers to the current object in a method or constructor.
|
||||
- The most common use of `this` is to distinguish between class attributes & parameters of the same name.
|
||||
- If the input parameter variables in your constructor have the **same name** as your fields, you must use the `this` keyword to distinguish between the two.
|
||||
- `this` = "belonging to this object".
|
||||
- E.g.,
|
||||
- ```java
|
||||
public Bicycle(int speed, int gear, int cadence)
|
||||
{
|
||||
this.speed = speed;
|
||||
this.gear = gear;
|
||||
this.cadence = cadence;
|
||||
}
|
||||
```
|
||||
-
|
||||
- ## Methods
|
||||
- What are **methods**? #card
|
||||
card-last-score:: 5
|
||||
card-repeats:: 5
|
||||
card-next-schedule:: 2022-12-18T19:12:15.540Z
|
||||
card-last-interval:: 33.96
|
||||
card-ease-factor:: 2.04
|
||||
card-last-reviewed:: 2022-11-14T20:12:15.540Z
|
||||
- **Methods** implement the *behaviour* of an object.
|
||||
- They have a consistent structure comprised of a *header* and a *body*.
|
||||
- ### Accessor Methods
|
||||
- What are **accessor** methods? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-09T18:39:30.677Z
|
||||
card-last-reviewed:: 2022-11-11T11:39:30.678Z
|
||||
card-last-score:: 5
|
||||
- **Accessor** methods provide information about the state of an object.
|
||||
- An accessor method always returns a type that is **not** `void`.
|
||||
- An accessor method returns a value (*result*) of the type given in the **header**.
|
||||
- The method will contain a **return** statement to return the value.
|
||||
- ### Mutator Methods
|
||||
- What are **mutator** methods? #card
|
||||
card-last-interval:: 29.26
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T22:48:10.566Z
|
||||
card-last-reviewed:: 2022-11-14T16:48:10.566Z
|
||||
card-last-score:: 5
|
||||
- **Mutator** methods alter (*mutate*) the state of an object.
|
||||
- Achieved through changing the value of one or more fields.
|
||||
- They typically contain one or more *assignment* statements.
|
||||
- Often receive parameters.
|
||||
- 
|
||||
- ### Mutator Methods: Set
|
||||
- Each field may have a dedicated **set** mutator method.
|
||||
- These have a simple, distinctive form:
|
||||
- **void** return type
|
||||
- method name related to the field name
|
||||
- a single formal parameter, with the same type as the type of the field
|
||||
- a single assignment statement
|
||||
- A typical "set" method:
|
||||
- ```java
|
||||
public void setGear (int number)
|
||||
{
|
||||
gear = number;
|
||||
}
|
||||
```
|
||||
- ### Protector Mutators
|
||||
- A set method does not always have to assign unconditionally to the field.
|
||||
- The parameter may be checked for validity and rejected if innappropriate.
|
||||
- Mutators thereby protect fields.
|
||||
- Mutators also support *encapsulation*.
|
||||
- #### Protecting a Field
|
||||
- ```java
|
||||
public void setGear (int gearing)
|
||||
{
|
||||
// this conditional statement prevents innapropriate action.
|
||||
// if protects the "gear" field from values that are too large or too small.
|
||||
if (gearing >= 1 && gearing <= 18)
|
||||
{
|
||||
gear = gearing;
|
||||
}
|
||||
else
|
||||
{
|
||||
System.out.println("Exceeds maximum gear ratio. Gear not set");
|
||||
}
|
||||
}
|
||||
```
|
||||
- ### Method Structure
|
||||
- The **header**:
|
||||
- The head tells us:
|
||||
- the *visibility* of the method to objects of other class.
|
||||
- whether or not the method *returns a result*.
|
||||
- the *name* of the method.
|
||||
- whether or not the method takes *parameters*.
|
||||
- E.g.,
|
||||
- ```java
|
||||
public int getSpeed()
|
||||
```
|
||||
- The **body** encloses the method's *statements*.
|
||||
-
|
||||
- ## C vs Java
|
||||
- Unlike C, an OOP program will **not** have a pool of global variables that each method can access.
|
||||
- Instead, ^^each object has its own data^^, and other objects rely on the *accessor* methods of the object to access the data.
|
||||
-
|
||||
- ## Conditional Statements
|
||||
- Conditional statements in Java have the same format as in C.
|
||||
- ```java
|
||||
if (condition) {
|
||||
do something;
|
||||
}
|
||||
else {
|
||||
do somethingElse;
|
||||
}
|
||||
```
|
||||
- 
|
||||
459
year2/semester1/logseq-stuff/pages/GDPR.md
Normal file
459
year2/semester1/logseq-stuff/pages/GDPR.md
Normal file
@ -0,0 +1,459 @@
|
||||
- #[[CT255 - Next Generation Technologies II]]
|
||||
- **Previous topic:** [[Introduction to Cybersecurity]]
|
||||
- **Next Topic:** [[Introduction to Cryptography]]
|
||||
- **Relevant lecture slides:** 
|
||||
-
|
||||
- ## Motivation
|
||||
- What are **Cyberattacks**?
|
||||
card-last-interval:: 11.2
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-10-12T17:25:05.425Z
|
||||
card-last-reviewed:: 2022-10-01T13:25:05.425Z
|
||||
card-last-score:: 5
|
||||
- Cyberattacks are aimed at **accessing, changing, or destroying sensitive information**, extorting money, or interrupting normal business processes.
|
||||
- Managing sensitive data may reduce the attack probability, or at least its impact.
|
||||
- **GDPR** provides such a regulatory framework
|
||||
-
|
||||
- ## General Data Protection Regulation
|
||||
- What is **GDPR**? #card
|
||||
card-last-interval:: 56.69
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2023-01-07T03:40:11.348Z
|
||||
card-last-reviewed:: 2022-11-11T11:40:11.348Z
|
||||
card-last-score:: 5
|
||||
- The **General Data Protection Regulation** is a binding regulation in EU law on data protection in the European Union and the European Economic Area (EEA).
|
||||
- The primary aim of GDPR is to ^^enhance individuals' control & rights over their personal data and to simplify the regulatory environment for international business.^^
|
||||
- The regulation contains ^^provisions & requirements related to the processing of personal data of individuals^^ who are located in the EEA, and applies to any enterprise that is processing the personal data of individuals inside the EEA - ^^regardless of its location and the data subjects' citizenship or residence.^^
|
||||
- ### GDPR Overview
|
||||
- The GDPR sets out several key principles: #card
|
||||
card-last-interval:: 9.28
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-11-24T02:20:42.714Z
|
||||
card-last-reviewed:: 2022-11-14T20:20:42.715Z
|
||||
card-last-score:: 5
|
||||
- Lawfulness
|
||||
- Fairness & Transparency
|
||||
- Purpose Limitation
|
||||
- Data Minimsation
|
||||
- Accuracy
|
||||
- Storage Limitation
|
||||
- Integrity & Confidentiality (Security)
|
||||
- Accountability
|
||||
- What is **Lawfulness** in GDPR? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-11-17T15:33:16.784Z
|
||||
card-last-reviewed:: 2022-10-20T08:33:16.785Z
|
||||
card-last-score:: 5
|
||||
- You must identify ^^**valid grounds** under the GDPR (known as a "**lawful basis**")^^ for collecting & using personal data.
|
||||
- Processing shall be lawful if and to the extent that at least one of the following applies:
|
||||
- Consensual
|
||||
- Necessary for the performance of a contract
|
||||
- Necessary for compliance with a legal obligation
|
||||
- Necessary to protect the vital interests of the data subject or another person
|
||||
- Necessary for the performance of a task carried out in public interest
|
||||
- Necessary for the purpose of legitimate interests
|
||||
- What is **Fairness & Transparency** in GDPR? #card
|
||||
card-last-interval:: 54.82
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2023-01-08T15:19:16.362Z
|
||||
card-last-reviewed:: 2022-11-14T20:19:16.362Z
|
||||
card-last-score:: 5
|
||||
- You must ^^use personal data in a way that is fair.^^ This means that you must not process the data in a way that is unduly detrimental, unexpected, or misleading to the individuals concerned.
|
||||
- You must be ^^clear, open, & honest^^ with data subjects from the start about how you will use their personal data.
|
||||
- At the time personal data is being collected from data subjects, they must be informed via a "**Data Protection Notice**".
|
||||
- What is a **Data Protection Notice**? #card
|
||||
card-last-interval:: 21.53
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-12-06T08:01:49.347Z
|
||||
card-last-reviewed:: 2022-11-14T20:01:49.348Z
|
||||
card-last-score:: 5
|
||||
- A **Data Protection Notice** entails:
|
||||
- The identity & contact details of the **data controller**
|
||||
- The contact details of the **data protection officer**
|
||||
- The **purpose of the processing** & the legal basis for the processing
|
||||
- The recipients or categories of **recipients of the data**
|
||||
- Details of any transfers out of the EEA, the safeguards in place, and the means by which to obtain a copy of them
|
||||
- The **data retention** period or the criteria to determine the data retention period
|
||||
- The **individual's rights** (access, rectification & erasure, restriction, complaint)
|
||||
- What is **Purpose Limitation** in GDPR? #card
|
||||
card-last-interval:: 75.28
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2023-01-25T17:31:58.536Z
|
||||
card-last-reviewed:: 2022-11-11T11:31:58.537Z
|
||||
card-last-score:: 5
|
||||
- You must be ^^clear about what your purposes for processing^^ are from the start.
|
||||
- You must ^^record your purposes^^ as part of your documentation obligations and specify them in your privacy information for individuals.
|
||||
- You ^^can only use the personal data for a new purpose^^ if it is either compatible with your original purpose, you get **consent**, or you have a **clear basis in law**.
|
||||
- What is **Data Minimisation** in GDPR? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:46:12.936Z
|
||||
card-last-reviewed:: 2022-11-14T16:46:12.936Z
|
||||
card-last-score:: 5
|
||||
- You must ensure that the personal data that you are processing is:
|
||||
- **adequate** - sufficient to properly fulfil your stated purpose
|
||||
- **relevant** - has a rational link to that purpose
|
||||
- **limited** to what is necessary - you do not hold more than what you need for your stated purpose
|
||||
- What is **Accuracy** in GDPR? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-11-17T15:35:02.681Z
|
||||
card-last-reviewed:: 2022-10-20T08:35:02.682Z
|
||||
card-last-score:: 5
|
||||
- You should take all reasonable steps to ensure that the personal data you hold is ^^not incorrect or misleading^^ as to any matter of fact.
|
||||
- You may need to ^^keep the personal data updated^^, although this will depend on what you are using it for.
|
||||
- If you ^^discover that personal data is incorrect or misleading^^, you must take reasonable steps to correct or erase it as soon as possible.
|
||||
- You must ^^carefully consider any challenges to the accuracy^^ of personal data.
|
||||
- What is **Storage Limitation** in GDPR? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:37:31.248Z
|
||||
card-last-reviewed:: 2022-11-14T16:37:31.249Z
|
||||
card-last-score:: 5
|
||||
- You must not keep personal data for ^^longer than you need it^^.
|
||||
- You need to think about - and be able to justify - ^^how long you keep personal data^^. This will depend on your purposes for holding the data.
|
||||
- You need a policy ^^setting standard retention periods^^ wherever possible, to comply with documentation requirements.
|
||||
- You should also ^^periodically review the data you hold^^, and erase or anonymise it when you no longer need it.
|
||||
- You must ^^carefully consider any challenges to your retention of data^^.
|
||||
- Individuals have a **right to erasure** if you no longer need the data.
|
||||
- You can ^^keep personal data for longer^^ if you are only keeping it for ^^personal interest archiving, scientific or historical research, or statistical purposes.^^
|
||||
- What is **Accountability & Governance** in GDPR? #card
|
||||
card-last-interval:: 28.93
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-12-13T14:49:09.573Z
|
||||
card-last-reviewed:: 2022-11-14T16:49:09.573Z
|
||||
card-last-score:: 5
|
||||
- **Accountability** is one of the **data protection principles** - it makes you responsible for complying with the GDPR and says that ^^you must be able to demonstrate your compliance.^^
|
||||
- You need to put in place appropriate technical & organisational measures to meet the requirements of accountability.
|
||||
- Accountability requires controllers to maintain records of processing activities in order to demonstrate how they comply with the data protection principles, i.e.:
|
||||
- Inventory of personal data
|
||||
- Providing assurance of compliance
|
||||
- Need to document
|
||||
- Why it is held
|
||||
- How it is collected
|
||||
- When it will be deleted
|
||||
- Who may gain access to it
|
||||
- What is **Integrity & Confidentiality** in GDPR? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-11-16T15:43:04.896Z
|
||||
card-last-reviewed:: 2022-10-19T08:43:04.897Z
|
||||
card-last-score:: 5
|
||||
- A key principle of GDPR is that you process personal data ^^securely by means of "appropriate technical & organisational measures"^^ - this is the "**security principle**".
|
||||
- Doing this requires you to consider things like ^^risk analysis, organisational policies, and physical + technical measures.^^
|
||||
- Where appropriate, you should look to use measures such as **pseudoanonymisation** and **encryption**.
|
||||
- Your measures must ensure the ^^"confidentiality, integrity, & availability"^^ of your systems & services and the personal data you process with them.
|
||||
- The measures must also enable you to ^^restore access & availability^^ to personal data in a timely manner in the event of a physical or technical incident.
|
||||
- What is **Data Protection**? #card
|
||||
card-last-interval:: 11.34
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-26T00:46:23.031Z
|
||||
card-last-reviewed:: 2022-11-14T16:46:23.032Z
|
||||
card-last-score:: 5
|
||||
- **Data Protection** is about an ^^individual's fundamental right to privacy.^^
|
||||
- When an individual gives their personal data to any organisation, the recipient has the duty to keep the data both safe & private. This applies to both printed & electronic data.
|
||||
- What does Data Protection Legislation do? #card
|
||||
card-last-interval:: 19.01
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-03T16:40:10.475Z
|
||||
card-last-reviewed:: 2022-11-14T16:40:10.475Z
|
||||
card-last-score:: 5
|
||||
- Data Protection Legislation:
|
||||
- governs the way we deal with personal data / information
|
||||
- provides a mechanism for safeguarding the privacy rights of individuals in relation to the processing of their data
|
||||
- upholds rights and enforces obligations
|
||||
- What is **Personal Data**? #card
|
||||
card-last-interval:: 29.26
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T22:47:49.984Z
|
||||
card-last-reviewed:: 2022-11-14T16:47:49.984Z
|
||||
card-last-score:: 5
|
||||
- **Personal Data** is any information relating to an identified or ^^identifiable natural person^^ ("data subject").
|
||||
- What is an **identifiable natural person**? #card
|
||||
card-last-interval:: 23.43
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-12-08T02:44:34.994Z
|
||||
card-last-reviewed:: 2022-11-14T16:44:34.995Z
|
||||
card-last-score:: 5
|
||||
- An **identifiable natural person** is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier to one or more factors specific to the ^^physical, physiological, genetic, mental, economic, cultural, or social identity^^ of that natural person.
|
||||
- What is **Data Processing**? #card
|
||||
card-last-interval:: 54.82
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2023-01-08T15:21:19.993Z
|
||||
card-last-reviewed:: 2022-11-14T20:21:19.993Z
|
||||
card-last-score:: 5
|
||||
- **Data Processing** is ^^performing any operation on personal data^^, either manually or by automated means, including:
|
||||
- Obtaining
|
||||
- Storing
|
||||
- Transmitting
|
||||
- Recording
|
||||
- Organising
|
||||
- Altering
|
||||
- Disclosing
|
||||
- Erasing
|
||||
- ### Entities in GDPR
|
||||
- GDPR distinguishes between:
|
||||
- The **Data Subject**
|
||||
- The **Data Protection Officer (DPO)**
|
||||
- The **Data Controller**
|
||||
- The **Data Processor**
|
||||
-
|
||||
- What is the **Data Subject**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:52:24.372Z
|
||||
card-last-reviewed:: 2022-11-14T16:52:24.372Z
|
||||
card-last-score:: 5
|
||||
- The **Data Subject** is the person to whom the data relates.
|
||||
- GDPR only applies to living individuals, but any duty of confidence in place prior to the death extends beyond that point.
|
||||
- In Ireland, the next of kin of the deceased are entitled to a Freedom of Information request to the deceased's personal data.
|
||||
- What is the **DPO**? #card
|
||||
card-last-interval:: 11.34
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-26T00:46:36.130Z
|
||||
card-last-reviewed:: 2022-11-14T16:46:36.130Z
|
||||
card-last-score:: 5
|
||||
- The primary role of the **Data Protection Officer (DPO)** is to ^^ensure that their organisation processes the personal data of its staff, customers, and other data subjects in compliance with the applicable data protection rules.^^
|
||||
- The Data Protection officer is required to be an expert within this field, along with the requirement for them to report to the highest management level.
|
||||
- With this being a challenging aspect of GDPR compliance for smaller organisations, there is the option to make an external appointment of a third-part DPO.
|
||||
- When is the DPO a mandatory role? #card
|
||||
card-last-interval:: 9.28
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-11-23T22:35:00.574Z
|
||||
card-last-reviewed:: 2022-11-14T16:35:00.574Z
|
||||
card-last-score:: 5
|
||||
- The DPO is a mandatory role within 3 different scenarios:
|
||||
- 1. When the processing is undertaken by a public authority or body.
|
||||
- 2. When an organisation's main activities require the frequent & large-scale monitoring of individual people.
|
||||
- 3. Where large-scale processing of special categories of data or data relating to criminal records forms the core activities.
|
||||
- What is the **Data Controller**? #card
|
||||
card-last-interval:: 9.68
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-11-24T08:43:13.191Z
|
||||
card-last-reviewed:: 2022-11-14T16:43:13.191Z
|
||||
card-last-score:: 5
|
||||
- The **Data Controller** is the company or an individual who ^^has overall control over the processing of personal data.^^
|
||||
- The Data Controller takes on the responsibility for GDPR compliance.
|
||||
- A Data Controller needs to have had sufficient training and to be able to competently ensure the security & protection of data held within the organisation.
|
||||
- What is the **Data Processor**? #card
|
||||
card-last-interval:: 4.28
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-23T00:35:18.504Z
|
||||
card-last-reviewed:: 2022-11-18T18:35:18.505Z
|
||||
card-last-score:: 5
|
||||
- The **Data Processor** is the person who is ^^responsible for the processing of personal information.^^
|
||||
- Generally, this role is undertaken under the instruction of the **data controller**.
|
||||
- This might mean obtaining or recording the data, its adaption, and use. It may also include the disclosure of the data or making it available to others.
|
||||
- Generally, the Data Processor is involved in the more technical elements of the operation, while the interpretation & main decision-making is the role of the Data Controller.
|
||||
-
|
||||
- ### Cloud Services & GDPR
|
||||
- What makes a **Cloud Service Provider** a **Data Processor**? #card
|
||||
card-last-interval:: 23.43
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-12-08T06:06:16.813Z
|
||||
card-last-reviewed:: 2022-11-14T20:06:16.814Z
|
||||
card-last-score:: 5
|
||||
- A **Cloud Service Provider** will be considered a **Data Processor** under GDPR if it provides **data processing services** (e.g., storage) on behalf of the **Data Controller** ^^even without determining the purposes & means of processing.^^
|
||||
- A Cloud Service Provider that offers personal data processing services directly to Data Subjects will be considered a **Data Controller**.
|
||||
- What are some key benefits of GDPR for Data Subjects? #card
|
||||
collapsed:: true
|
||||
card-last-interval:: 19.01
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-03T16:40:34.643Z
|
||||
card-last-reviewed:: 2022-11-14T16:40:34.643Z
|
||||
card-last-score:: 5
|
||||
- More information must be given to data subjects (e.g., how long the data will be kept, right to lodge a complaint).
|
||||
- The Data Controller must explain & document the legal basis for processing the personal data.
|
||||
- GDPR tightens the rules on how consent can be obtained.
|
||||
- Must be distinguishable from other matters and in clear, plain language.
|
||||
- It must be as easy to withdraw consent as it is to give it.
|
||||
- Mandatory notification of security breaches without "undue delay" to the Data Protection Commissioner (within 72 hours).
|
||||
- What are some key rights of Data Subjects? #card
|
||||
card-last-interval:: 41.44
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-26T06:18:29.246Z
|
||||
card-last-reviewed:: 2022-11-14T20:18:29.246Z
|
||||
card-last-score:: 5
|
||||
- Right of Access (copy to be provided within one month)
|
||||
- Right to Erasure (the right to be forgotten)
|
||||
- Right to Restriction of Processing
|
||||
- Right to Object to Processing
|
||||
- Right not to be subject to a decision based solely upon automated processing
|
||||
- What are **Personal Data Security Breaches**? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-11-17T15:32:03.843Z
|
||||
card-last-reviewed:: 2022-10-20T08:32:03.844Z
|
||||
card-last-score:: 5
|
||||
- **Personal Data Security Breaches** include:
|
||||
- Disclosure of confidential data to unauthorised individuals.
|
||||
- Loss or theft of data or equipment upon which data is stored.
|
||||
- Hacking, viruses, or other security attacks on IT equipment / systems / networks.
|
||||
- Inappropriate access controls allowing unauthorised use of information.
|
||||
- Emails containing personal data sent in error to the wrong recipient.
|
||||
- Personal Data Security Breaches apply to both paper & electronic records.
|
||||
-
|
||||
- ## HTTP Cookies
|
||||
- What is a **(HTTP) Cookie**? #card
|
||||
card-last-interval:: 9.28
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-11-23T22:35:54.977Z
|
||||
card-last-reviewed:: 2022-11-14T16:35:54.977Z
|
||||
card-last-score:: 5
|
||||
- A **(HTTP) Cookie** is a small piece of data stored on the user's computer by the web browser while browsing a website.
|
||||
- Cookies were designed to be a reliable mechanism for websites to remember stateful information (such as items in the shopping cart in an online store) or to record the user's browsing activity.
|
||||
- They can be also be used to remember pieces of information that the user previously entered into form fields.
|
||||
- **Authentication Cookies** are the most common method used by web servers to know whether the user is logged in or not, and which account they are logged into.
|
||||
-
|
||||
- #### Cookie Implementation
|
||||
- How are cookies implemented? #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T11:27:17.132Z
|
||||
card-last-reviewed:: 2022-11-14T16:27:17.133Z
|
||||
card-last-score:: 5
|
||||
- Cookies are ^^arbitrary pieces of data^^ (i.e., large, random strings), usually chosen & first sent by the web server, and stored on the client computer by the web browser.
|
||||
- The browser then sends them back to the server with every request.
|
||||
- Browsers are required to: #card
|
||||
card-last-score:: 5
|
||||
card-repeats:: 2
|
||||
card-next-schedule:: 2022-11-17T11:25:54.217Z
|
||||
card-last-interval:: 2.8
|
||||
card-ease-factor:: 2.6
|
||||
card-last-reviewed:: 2022-11-14T16:25:54.218Z
|
||||
- support cookies as large as 4,906 bytes in size
|
||||
- support at least 50 cookies per domain
|
||||
- support at least 3,000 cookies in total
|
||||
-
|
||||
- #### Cookie Structure
|
||||
- What are the components of a cookie? #card
|
||||
card-last-interval:: 8.35
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-29T21:09:38.375Z
|
||||
card-last-reviewed:: 2022-11-21T13:09:38.376Z
|
||||
card-last-score:: 5
|
||||
- A cookie consists of the following components:
|
||||
- Name
|
||||
- Value
|
||||
- Zero or more attributes (name - value pairs). These attributes store information such as the cookie's expiration, domain, and flags (such as *Secure* and *HttpOnly*)
|
||||
-
|
||||
- ### Session Cookies
|
||||
- What is a **session cookie**? #card
|
||||
card-last-interval:: 19.01
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-03T16:40:31.570Z
|
||||
card-last-reviewed:: 2022-11-14T16:40:31.571Z
|
||||
card-last-score:: 5
|
||||
- A **session cookie** (aka in-memory cookie, transient cookie, or non-persistent cookie) is a cookie that ^^exists only in temporary memory while the user navigates its website.^^
|
||||
- Web browsers normally delete session cookies when the user closes the browser.
|
||||
- Session cookies do not have an expiration date assigned to them, which is how the browser know to treat them as session cookies.
|
||||
-
|
||||
-
|
||||
- ### Persistent Cookies
|
||||
- What is a **persistent cookie**? #card
|
||||
card-last-interval:: 23.43
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-12-04T21:33:28.732Z
|
||||
card-last-reviewed:: 2022-11-11T11:33:28.733Z
|
||||
card-last-score:: 5
|
||||
- A **persistent cookie** is a cookie which ^^expires at a specific data or after a specific length of time.^^
|
||||
- A persistent cookie's information will be transmitted to the server every time the user visits the website that the cookie belongs to, for the lifespan of the persistent cookie (as set by its creator), or every time that the user views a resource belonging to that website from another website (such as an advertisement).
|
||||
-
|
||||
- Persistent cookies are sometimes referred to as **tracking cookies** because they can be used by advertisers to record information about a user's web browsing habits.
|
||||
- However, tracking cookies are mainly used for legitimate reasons, such as keeping users logged into their accounts on website to avoid re-entering login credentials at every visit.
|
||||
-
|
||||
- ### Cookie Attributes
|
||||
- Consider the following response header sent by a webserver that contains 3 persistent cookies:
|
||||
- 
|
||||
- What do the *Domain* and *Path* attributes do? #card
|
||||
card-last-interval:: 9.28
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-11-18T18:45:59.521Z
|
||||
card-last-reviewed:: 2022-11-09T12:45:59.521Z
|
||||
card-last-score:: 3
|
||||
- The *Domain* and *Path* attributes define the cookie's scope.
|
||||
- What does the *Secure* attribute do? #card
|
||||
card-last-interval:: 84.1
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.76
|
||||
card-next-schedule:: 2023-02-06T22:21:24.146Z
|
||||
card-last-reviewed:: 2022-11-14T20:21:24.147Z
|
||||
card-last-score:: 5
|
||||
- The *Secure* attribute ensures that the cookie can only be transmitted over an **encrypted connection**, making it a "**secure cookie**".
|
||||
- What does the *HttpOnly* attribute do? #card
|
||||
card-last-interval:: 64.01
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.52
|
||||
card-next-schedule:: 2023-01-24T13:10:00.242Z
|
||||
card-last-reviewed:: 2022-11-21T13:10:00.242Z
|
||||
card-last-score:: 5
|
||||
- The *HttpOnly* attribute ^^directs cookies not to expose cookies through channels other than HTTP / HTTPS.^^
|
||||
- This means that this HttpOnly cookie cannot be accessed via client-side scripting languages (notably JavaScript).
|
||||
-
|
||||
- ## GDPR & Cookies
|
||||
- Generally, a user's consent must be sought before a cookie is installed in a web browser.
|
||||
- There are **two** expemptions:
|
||||
- The **Communications Exemption**
|
||||
- The **Strictly Necessary Exemption**
|
||||
-
|
||||
- What is the **Communications Exemption**? #card
|
||||
card-last-interval:: 41.44
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-26T06:18:30.530Z
|
||||
card-last-reviewed:: 2022-11-14T20:18:30.530Z
|
||||
card-last-score:: 5
|
||||
- The **Communications Exemption** applies to cookies ^^whose sole purpose is for carrying out the transmission of a communication over a network^^, for example, to identify the communication endpoints.
|
||||
- Cookies that meet these criteria are exempted from being required to ask for the user's consent prior to installation.
|
||||
- **Example:** load-balancing cookies that distribute network traffic across different backend servers, also known as **session stickiness**.
|
||||
- Here, a **load-balancer** creates an affinity between a client and a specific network server for the duration of a session using a cookie with a random & unique tracking ID.
|
||||
- Subsequently, the load-balancer routes all the of the requests from this client to a specific backend server using the tracking ID, for the duration of the session.
|
||||
- {:height 426, :width 529}
|
||||
-
|
||||
-
|
||||
- What is the **Strictly Necessary** exemption? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-11-17T15:34:39.740Z
|
||||
card-last-reviewed:: 2022-10-20T08:34:39.740Z
|
||||
card-last-score:: 5
|
||||
- The **Strictly Necessary** exemption exempts cookies that are strictly necessary to provide the service of delivered over the internet, i.e., a website or app from being required to ask the user's consent prior to installation.
|
||||
- ^^This service must have been explicitly requested by the user (i.e., typing in the URL), and the use of the cookie must be restricted to what is strictly necessary to provide that service.^^
|
||||
- Cookies related to advertising are **not** strictly necessary, and must be consented to.
|
||||
- Examples:
|
||||
- A website uses session cookies to keep track of items that a user places in an online shopping basket (assuming that this cookie will be deleted once the session is over).
|
||||
- Cookies that a record a user's language or country preference.
|
||||
@ -0,0 +1,81 @@
|
||||
- #[[CT255 - Next Generation Technologies II]]
|
||||
- **Previous Topic:** [[Human Security & Passwords]]
|
||||
- **Next Topic:** [[Social Engineering]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Hash Cracking
|
||||
- Reverse-engineering a password involves reversing a one-way function, so it is not possible.
|
||||
- But hash functions are public.
|
||||
- ## Dictionary-Based Brute Force Search #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-18T20:09:33.480Z
|
||||
card-last-reviewed:: 2022-11-14T20:09:33.481Z
|
||||
card-last-score:: 5
|
||||
- Dictionary searches can be used to systematically identify a match for a given hash value.
|
||||
- To do this, the underlying hash function must be known.
|
||||
- Dictionaries are based on large word, phrase, or password collections.
|
||||
- ### Pros
|
||||
- Straightforward process.
|
||||
- ### Cons
|
||||
- Significant computational effort to find a match.
|
||||
- No guaranteed result.
|
||||
- ## Lookup Table Based Attacks #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T15:07:31.246Z
|
||||
card-last-reviewed:: 2022-11-14T20:07:31.246Z
|
||||
card-last-score:: 5
|
||||
- For a given hash function & dictionary:
|
||||
- 1. Calculate the hash value for all dictionary entries.
|
||||
2. Add both values to a table (i.e., one line per entry).
|
||||
3. Sort the table (e.g., in ascending order of hash values).
|
||||
- This table is also called a **lookup table**.
|
||||
- The matching password for a given hash value can be recovered by systematically searching for it in a dictionary.
|
||||
- ### Pros
|
||||
- Such a table can be generated offline.
|
||||
- The lookup process itself is fast (approx. $O(log_2(N))$) with **binary search**.
|
||||
- A table containing 1.8E19 entries would require just 64 guesses to find (or not) the correct password for a given hash value.
|
||||
- ### Cons
|
||||
- Huge table, with no guaranteed result.
|
||||
- Different table required for every hash function.
|
||||
- ## Rainbow Tables
|
||||
- Uses less computer processing time but more storage than a brute force attack.
|
||||
- Uses more processing time but less storage than a simple lookup table.
|
||||
- #### Pre-Computed Hash Chains
|
||||
- Calculate long chains of hash values (using a hash value "->" and a reduction function
|
||||
" <ins>-></ins> ", e.g:
|
||||
- aaaaaa -> 173bdfede2ee3ab3 <ins>-></ins> jdjkuo -> 9fdde3a0027fbb36 <ins>-></ins> ... <ins>-></ins> k3rtol
|
||||
- In this example, wes only consider passwords that are 6 characters long.
|
||||
- Each chain starts with a random password & has a fixed length, e.g. 10,000 segments.
|
||||
- Here, " <ins>-></ins> " converts the 64-bit hash value into an arbitrary 6 byte long string.
|
||||
- It is **not** an inverted hash function.
|
||||
- We only store the first and the last value (starting point & end point).
|
||||
- ### Chain Lookup
|
||||
- Assume that we have a table with just 2 chains (with start & end values), and a hash value `759858fde66e8aa8` that we'd like to crack.
|
||||
- 
|
||||
- We apply consecutively " <ins>-></ins> " and "->" until we either:
|
||||
- hit a known end value, or
|
||||
- have repeated the operation $n$ times, where $n$ is the length of the chain.
|
||||
- If we hit the known end value `prp56e`, we repeat the transformation starting with its start value, until we hit the `hfk39f` again.
|
||||
- The password `delphi` that led to this hash is the solution.
|
||||
- #### Chain Lookup Pseudocode
|
||||
- 1. Input: Hash value $H$.
|
||||
2. Reduce $H$ into another plaintext $H$.
|
||||
3. Look for the plaintext $P$ in the list of final plaintexts (i.e., end values), if it is there, break out of the loop & go to step 6.
|
||||
4. If it isn't there, calculate the hash $H$ of the plaintext $P$.
|
||||
5. Go to step 2, unless you've done the maximum number of iterations.
|
||||
6. If $P$ matches one of the final plaintexts, you've got a matching chain; in this case, walk through the chain again starting with the corresponding start value, until you find the text that translates into $H$.
|
||||
- ### Chain Collisions
|
||||
- Consider the following scenario:
|
||||
- 
|
||||
- Two chains merge because either:
|
||||
- the reduction function translates two different hashes into the same password, or
|
||||
- the hash function translates two different passwords into the same hash (which should not happen)
|
||||
- Because of collisions, there is no guarantee that you chains will ever cover all possible passwords.
|
||||
- **Rainbow Tables** effectively solve the problem of collisions with ordinary hash chains by replacing the single reduction function $R$ with a sequence of related reductions functions $R$ through $R_k$ (one reduction function per column).
|
||||
- In this way, for two chains to collide & merge they must hit the same value on the same iteration, which is rather unlikely.
|
||||
- ### Perfect & Imperfect Rainbow Tables
|
||||
-
|
||||
@ -0,0 +1,87 @@
|
||||
- #[[CT255 - Next Generation Technologies II]]
|
||||
- **Previous Topic:** [[Introduction to Cryptography]]
|
||||
- **Next Topic:** [[Hash Cracking Using Rainbow Tables]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- What is a **password**? #card
|
||||
card-last-interval:: 10.6
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-25T06:28:38.024Z
|
||||
card-last-reviewed:: 2022-11-14T16:28:38.024Z
|
||||
card-last-score:: 5
|
||||
- A **password** is a memorised secret used to confirm the identity of a user.
|
||||
- Typically, an arbitrary string of characters including letters, digits, or other symbols.
|
||||
- A purely numeric secret is called a **Personal Identification Number (PIN)**.
|
||||
- The secret is memorised by a party called the **claimant** while the party verifying the identity of the claimant is called the **verifier**.
|
||||
- The claimant & the verifier communicate via an **authentication protocol**.
|
||||
- # Some Password Alternatives
|
||||
- One-Time Password (OTP).
|
||||
- Transaction Authentication Number (TAN) list used for online banking - they can only be used once.
|
||||
- Time-synchronised one-time passwords.
|
||||
- Biometric methods.
|
||||
- Fingerprints, irises, voice, face.
|
||||
- Cognitive passwords.
|
||||
- Use question & answer cue/response pairs to verify identity.
|
||||
-
|
||||
- # Algorithmic Generation of OTP
|
||||
- Paper-based TANs are hard to manage -> both the claimant and the verifier need to have a copy of every OTP (possibly hundreds of them).
|
||||
- Idea: each OTP may be created from the passt OTPs used.
|
||||
- An example of this type of algorithm, credited to Leslie Lamport, uses a **one-way function** (hash function).
|
||||
- ## One-Way Functions
|
||||
- What is a **hash function**? #card
|
||||
card-last-interval:: 29.99
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-12-14T19:04:01.691Z
|
||||
card-last-reviewed:: 2022-11-14T20:04:01.691Z
|
||||
card-last-score:: 5
|
||||
- A **one-way function** $H$ produces a fixed-size output $h$ based on a variable size input $s$.
|
||||
- $$H(s) = h$$
|
||||
- $H$ is also called a **hash function**, $h$ is called a **hash** (value).
|
||||
- Important: *one-way property*:
|
||||
- For a given hash code $h$, it is infeasible to find $s$ that $H(s) = h$.
|
||||
- ### Leslie Lamport's Algorithm #card
|
||||
card-last-interval:: 7.8
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-22T15:17:39.453Z
|
||||
card-last-reviewed:: 2022-11-14T20:17:39.454Z
|
||||
card-last-score:: 5
|
||||
- For every claimant, a random seed (starting value) $s$ is chosen.
|
||||
- A hash function $H(s)$ is applied repeatedly (e.g., 1,000 times) to the seed, giving a value of:
|
||||
- $$H(H(H(...(H(s)....))))$$
|
||||
- The user's first login uses an OTP $p$ derived by applying $H$ 999 times to the seed, i.e., $H^{999}(s)$.
|
||||
- The verifier can authenticate that this is the correct OTP, because $H(p) = H^{1000}(s)$, the value stored.
|
||||
- The value stored is then replaced by $p$ and the user is allowed to log in.
|
||||
- The next login must be accompanied by $H^{998}(s)$.
|
||||
- Again, this can be validated because hashing gives $H^{999}(s)$ which is $p$, the value stored after the previous login.
|
||||
- The new value replaces $p$ and the user is authenticated.
|
||||
- This process can be repeated another 997 times, each time the password will be $H$ applied one fewer times.
|
||||
- ### Time-Synchronised OTP #card
|
||||
card-last-interval:: 8.63
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-20T02:38:06.966Z
|
||||
card-last-reviewed:: 2022-11-11T11:38:06.967Z
|
||||
card-last-score:: 5
|
||||
- Each user has a unique piece of hardware called a **security token** that generates an OTP (e.g., mobile phone).
|
||||
- Inside the token is an accurate clock that has been synchronised with the clock of the verifer.
|
||||
- Both claimant token and verifier server calculate identical OTPs that are based on time.
|
||||
- 
|
||||
-
|
||||
- # Some New Biometric Methods
|
||||
- **Hand geometry:** Measurement & comparison of the (unique) different physical characteristics of the hand.
|
||||
- **Palm vein authentication:** Uses an infrared beam to penetrate the user's hand as it is waved over the system; the veins within the palm are returned as black lines.
|
||||
- **Retina scan:** Provides an analysis of the capillary blood vessels located in the back of the eye.
|
||||
- **Iris scan:** Provides an analysis of the rings, furrows, & freckles in the coloured ring that surrounds the pupil of the eye.
|
||||
- Face recognition, signature, & voice analysis.
|
||||
- **Behavioural biometrics:**
|
||||
- 
|
||||
-
|
||||
- # Multi-Factor Authentication
|
||||
- This may include a combination of the following:
|
||||
- Some physical object in the possession of the user, e.g., a USB stick with a secret token, a bank card, a key, etc.
|
||||
- Some secret known only to the user, such as a password, PIN, TAN, etc.
|
||||
- Some physical characteristic of the user (biometrics), such as a fingerprint, eye iris, voice, typing speed, pattern in key press intervals, etc.
|
||||
- Somewhere you are, such as connection to a specific computing network or utilising a GPS signal to identify the location.
|
||||
146
year2/semester1/logseq-stuff/pages/Hypothesis Testing.md
Normal file
146
year2/semester1/logseq-stuff/pages/Hypothesis Testing.md
Normal file
@ -0,0 +1,146 @@
|
||||
- #[[ST2001 - Statistics in Data Science I]]
|
||||
- **Previous Topic:** [[Sampling Distributions & Confidence Intervals]]
|
||||
- **Next Topic:** [[Correlation & Linear Regression]]
|
||||
- **Relevant Slides:** _1667837679625_0.pdf)
|
||||
-
|
||||
- What is a **hypothesis test**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:21:16.988Z
|
||||
card-last-score:: 1
|
||||
- A **hypothesis test** is intended to assess whether a population **parameter** of interest is equal to some specified value of direct interest to the researcher.
|
||||
- Hypothesis tests are structured in a very specific manner.
|
||||
- The CLT and t-distribution provide the framework for assessing if the sample mean is not the same as the proposed parameter mean.
|
||||
- # Null & Alternative Hypotheses #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T11:15:25.890Z
|
||||
card-last-reviewed:: 2022-11-14T16:15:25.891Z
|
||||
card-last-score:: 5
|
||||
- The **null hypothesis** is a claim to be tested - often the sceptical claim of "no effect", i.e.:
|
||||
- $$H_0 : \mu = \mu_0$$
|
||||
- The **alternative hypothesis** is an alternative claim under consideration, often represented by a range of parameter values, i.e.:
|
||||
- $$H_1 : \mu \neq \mu_0$$
|
||||
- We only reject the null in favour of the alternative if there is strong supporting evidence.
|
||||
- We decide *a priori* how much evidence is "strong" enough to reject the null.
|
||||
- # Stages in Hypothesis Testing #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:53:56.498Z
|
||||
card-last-score:: 1
|
||||
- 1. **Null Hypothesis:** The hypothesis that the population parameter is equal to some claimed value ($H_0$).
|
||||
2. **Study** or **Alternative Hypothesis:** The hypothesis that must be true if the null hypothesis is false ($H_1$).
|
||||
3. Collect appropriate data.
|
||||
4. ^^Assess, through a **test statistic**, how probable (the p-value) it would be to observe data as or more extreme than the data actually collected if, in fact, the null hypothesis was **true**.^^
|
||||
5. Come to a conclusion whether or not to reject the null hypothesis.
|
||||
- ## Rejecting / Not Rejecting the Null
|
||||
- If we do not reject the null hypothesis in favour of the alternative, we are saying that the effect indicated by the sample is due only to sampling variation.
|
||||
- If we do reject the null hypothesis in favour of the alternative, we are saying that the effect indicated by the sample is real, in that it is more than can be attributed to sampling variation.
|
||||
- # Formal Testing Using p-values
|
||||
- What is the **p-value**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-19T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-18T18:36:35.132Z
|
||||
card-last-score:: 1
|
||||
- The **p-value** is the ==probability of observing data at least as favourable to the alternative hypothesis== as our current data set, if the null hypothesis is true.
|
||||
- The **p-value** is a way of quantifying the strength of the evidence against the null hypothesis and in favour of the alternative. Formally, the p-value is a conditional probability.
|
||||
- The smaller the p-value, the stronger the data favours $H_1$ over $H_0$. A small p-value (usually < 0.05) corresponds to sufficient evidence to reject $H_0$ in favour of $H_1$.
|
||||
- # One-Sample Tests for the Population Mean
|
||||
- ## Steps #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:16:23.254Z
|
||||
card-last-score:: 1
|
||||
- 1. Specify the hypotheses about $\mu$.
|
||||
2. Calculate a **test statistic** - based on the sampling distribution of the sample mean.
|
||||
3. See how extreme the test statistic is if the null hypothesis was true - compare the test statistic with the t or Normal Distribution.
|
||||
4. Make a decision: reject the null, or fail to reject it.
|
||||
- ## Strategy #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:13:48.280Z
|
||||
card-last-score:: 1
|
||||
- If the sample came from the population in question, the sample mean should be "close" to the population mean in question.
|
||||
- "Close" needs to take into account the sample size used and the variability in the measure (i.e., the standard error).
|
||||
- For testing means, the ((6356abee-cb6a-48c5-8f8b-72122b6099eb)) or t-distribution (or the bootstrap) is key.
|
||||
- ## Conditions
|
||||
- **Independence:** Random samples / assignment.
|
||||
- **Normality:** For small samples where we use the t-distribution, we require the observations to be approximately normally distributed. For larger ($n \geq 30$) samples with no extreme skew we can use the CLT and do not require the observations to be normally distributed.
|
||||
- ## p-values & ($\alpha$) Significance Levels #card
|
||||
card-last-interval:: 0.98
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T15:23:09.685Z
|
||||
card-last-reviewed:: 2022-11-14T16:23:09.685Z
|
||||
card-last-score:: 3
|
||||
- A p-value $\leq 0.05$ is (typically) considered as sufficient evidence against a null hypothesis (i.e., sufficient evidence to reject the null).
|
||||
- If the p-value for the test of a parameter with 2-sided alternative is $< 0.05$, the 95% Confidence Interval will not include the parameter.
|
||||
- A p-value is **not** the probability of the null hypothesis being true given the data observed - It is the probability of observing such data (or more extreme data) given that the null hypothesis is actually true.
|
||||
- A **non-significant test** does not imply that the null hypothesis is true - It actually means that ==we do not have enough evidence to reject the null hypothesis.==
|
||||
- A **significant** result does not mean that the alternative hypothesis is true - It means that we have ==enough evidence to reject the null.==
|
||||
- ### Statistical Signifance
|
||||
- Whenever the p-value is less than a particular threshold, the result is said to be **statistically significant** at that level.
|
||||
- The threshold should be decided *a priori*, before you calculate the test statistic.
|
||||
- For example, if the threshold is $p \leq 0.05$, the result is statistically significant at the 5% level; if $p \leq 0.01$, the result is statistically significant at the 1% level, and so on.
|
||||
- If a result is statistically significant at the $100\alpha\%$ level, we can also say that the null hypothesis is "rejected at level $100\alpha\%$
|
||||
- ### Example: Golf Club Design
|
||||
- An experiment was performed in which 15 drivers produced by a particular club-maker were selected at random, and their coefficients of restitution measured. It is of interest to determine if there is evidence (with $\alpha = 0.05$ significance level) to support a claim that the mean coefficient of restitution *exceeds* 0.82.
|
||||
background-color:: green
|
||||
- The sample mean & sample standard deviation are $\bar x = 0.83725$ & $s = 0.02456$.
|
||||
background-color:: green
|
||||
- The objective of the experimenter is to demonstrate that the mean coefficient of restitution exceeds 0.82, hence, a one-sided alternative hypothesis is appropriate.
|
||||
- The **parameter of interest** is the mean coefficient of restitution, $\mu$.
|
||||
- The **null hypothesis** is $H_0: \mu = 0.82$.
|
||||
- The **alternative hypothesis** is $H_1: \mu > 0.82$.
|
||||
- We decide *a priori* that we will reject $H_0$ is the p-value is $< 0.05$.
|
||||
- The **test statistic** is
|
||||
- $$T_0 = \frac{\bar X - \mu_0}{S / \sqrt{n}}$$
|
||||
- **Computations:** Since $\bar x = 0.83725, s = 0.02456, \mu = 0.82,$ and $n = 15$, our observed test statistic is
|
||||
- $$t_0 = \frac{0.83725 - 0.82}{0.02456 / \sqrt{15}} = 2.72$$
|
||||
- 
|
||||
- **Conclusions:** The probability of observing such data (or more extreme data) if the null hypothesis is true is less than 0.008.
|
||||
- **Interpretation:** There is strong evidence ($p = 0.008$) to conclude that the mean coefficient of restitution exceeds 0.82.
|
||||
- A CI would give an interval estimate as to what it actually is.
|
||||
- ## Connection Between Hypothesis Tests & Confidence Intervals
|
||||
- A close relationship exists between the test of a hypothesis for $\theta$ & the confidence interval for $\theta$.
|
||||
- If $[I, u]$ is a 95% confidence interval for the parameter $\theta$, the test of the null hypothesis against a 2-sided alternative at the 0.05 significance level
|
||||
- $$H_0: \theta = \theta_0$$
|
||||
- $$H_1: \theta \neq \theta_0$$
|
||||
- will lead to rejection of $H_0$ if and only if $\theta_0$ is **not** in the 95% CI $[I,u]$.
|
||||
-
|
||||
- # Decision Errors
|
||||
- What is a **type 1 error**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:53:18.720Z
|
||||
card-last-score:: 1
|
||||
- A **type 1 error** is rejecting the null hypothesis when $H_0$ is true.
|
||||
- ### Type 1 Error Rate
|
||||
- As a general rule, we reject $H_0$ if the p-value is less than 0.05, i.e., we use a **significance level** of 0.05, $\alpha = 0.05$.
|
||||
- This means that, for those cases where $H_0$ is actually true, we do not want to incorrectly reject it more than 5% of the times.
|
||||
- In other words, when using a 5% significance level, there is about a 5% chance of making a Type 1 Error if the null hypothesis is true.
|
||||
- $$P(\text{Type 1 Error}) = \alpha$$
|
||||
- $$P(\text{Reject }H_0 | H_0 \text{ true}) = \alpha$$
|
||||
- This is why we prefer small values of $\alpha$ - increasing $\alpha$ increases the Type 1 Error rate.
|
||||
- What is a **type 2 error**? #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T10:54:03.881Z
|
||||
card-last-reviewed:: 2022-11-14T15:54:03.881Z
|
||||
card-last-score:: 5
|
||||
- A **type 2 error** is failing to reject the null hypothesis when $H_A$ is true.
|
||||
-
|
||||
57
year2/semester1/logseq-stuff/pages/Interfaces.md
Normal file
57
year2/semester1/logseq-stuff/pages/Interfaces.md
Normal file
@ -0,0 +1,57 @@
|
||||
- #[[CT2106 - Object-Oriented Programming]]
|
||||
- **Previous Topic:** [[Abstraction & Polymorphism]]
|
||||
- **Next Topic:** [[Static Fields & Exceptions]]
|
||||
- **Relevant Slides:**  
|
||||
-
|
||||
- # Multiple Inheritance
|
||||
- What is **multiple inheritance**? #card
|
||||
card-last-interval:: 3.05
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T21:22:31.707Z
|
||||
card-last-reviewed:: 2022-11-14T20:22:31.708Z
|
||||
card-last-score:: 5
|
||||
- **Multiple inheritance** is where a class has multiple simultaneous superclasses.
|
||||
- However, Java does not support multiple inheritance as it has led to major problems in OOP due to conflicting field & method implementations inherited from superclasses.
|
||||
- # Interface
|
||||
- What is an **interface**? #card
|
||||
card-last-interval:: 3.05
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T21:25:49.658Z
|
||||
card-last-reviewed:: 2022-11-14T20:25:49.659Z
|
||||
card-last-score:: 5
|
||||
- Java uses a structure called an **interface** to achieve a form of *multiple inheritance*.
|
||||
- An interface is like a class, but it is really more like ==an outline of what methods a class should have.==
|
||||
- Like a class, an interface can be used as a **type**.
|
||||
- By convention, interface names often end in -`able`.
|
||||
- While a class can only extend one super class (direct inheritance), a class can implement multiple interfaces.
|
||||
- ## Examples
|
||||
- ```java
|
||||
public interface Eatable
|
||||
{
|
||||
public int getCalories(); // note: method definitions have no body
|
||||
public int extractEnergy;
|
||||
}
|
||||
```
|
||||
- ```java
|
||||
public class Canary extends Bird implements Food, Comparable() ....
|
||||
```
|
||||
- What does it mean if a class implements an interface? #card
|
||||
card-last-interval:: 0.98
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T15:21:59.543Z
|
||||
card-last-reviewed:: 2022-11-14T16:21:59.544Z
|
||||
card-last-score:: 3
|
||||
- 1. Any class that implements said interface can be treated as that interface's type (polymorphism).
|
||||
2. Any class that implements that interface *must* provide **concrete implementations** of its method.
|
||||
- ## Interface VS Abstract
|
||||
- ### Similarities
|
||||
- Both can be used to provide "templates" for what subclasses can implement.
|
||||
- An abstract method plays the same role as an interface method - both *must* be implemented in concrete form by a subclass.
|
||||
- An abstract class and an Interface can be used as the **type** for a reference variable.
|
||||
- ### DIfferences
|
||||
- An abstract class is used for class inheritance purposes - providing an abstract structure that subclasses inherit. Therefore, the subclasses have a lot in common.
|
||||
- However, an interface is often used to impose common functionality on classes that have nothing in common.
|
||||
-
|
||||
@ -0,0 +1,101 @@
|
||||
- #[[CT216 - Software Engineering I]]
|
||||
- **Previous Topic:** [[Software Processes]]
|
||||
- **Next Topic:** [[SCRUM Roles & Ceremonies]]
|
||||
- **Relevant Slides:** _1663848442133_0.pdf)
|
||||
-
|
||||
- # Software Development Lifecycle
|
||||
- What is the **Software Lifecycle**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-22T18:34:10.895Z
|
||||
card-last-reviewed:: 2022-11-18T18:34:10.895Z
|
||||
card-last-score:: 5
|
||||
- The **software lifecycle** is an abstract representation of a software process. It defines the steps, methods, tools, activities, and deliverables of a software development project.
|
||||
- The following **lifecycle phases** are considered:
|
||||
- 1. Requirement Analysis
|
||||
2. System Design
|
||||
3. Implementation
|
||||
4. Integration & Deployment
|
||||
5. Operation & Maintenance
|
||||
- ## SDLC Limitations
|
||||
- Classical project planning methods have a lot of disadvantages:
|
||||
- Huge efforts during the planning phase (requirements + design).
|
||||
- Poor requirements conversion in a rapidly changing environment.
|
||||
- Treatment of staff as a factor of production.
|
||||
-
|
||||
- # Agile
|
||||
- What is **Agile**? #card
|
||||
card-last-interval:: 9.28
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-11-23T22:34:56.520Z
|
||||
card-last-reviewed:: 2022-11-14T16:34:56.520Z
|
||||
card-last-score:: 5
|
||||
- There is no single definition of Agile, but the Agile Manifesto is the closest to a defintion.
|
||||
- Set of principles.
|
||||
- Developed by Agile Alliance.
|
||||
- Agile methods focus on:
|
||||
- Individuals & interactions over processes & tools.
|
||||
- Working software over comprehensive documentation.
|
||||
- Customer collaboration over contract negotiation.
|
||||
- Responding to change over following a plan.
|
||||
- The [Agile Alliance](www.agilealliance.org) is a non-profit organisation promotes agile development.
|
||||
- ## Agile Motivation
|
||||
- Agile proponents argue:
|
||||
- Software development processes relying on lifecycle models are too heavyweight or cumbersome.
|
||||
- Too many things are done that are not directly related to the software product being produced, i.e., design, models, requirements docs, documentation that isn't shipped as part of the product.
|
||||
- Difficulty with incomplete or changing requirements.
|
||||
- Short development cycles (Mobile Apps).
|
||||
- More active customer involvement needed.
|
||||
- There are several Agile methods, including **Scrum** and **Extreme Programming (XP)**.
|
||||
- ## SCRUM
|
||||
- What is **Scrum**? #card
|
||||
card-last-score:: 5
|
||||
card-repeats:: 4
|
||||
card-next-schedule:: 2022-12-06T08:19:38.287Z
|
||||
card-last-interval:: 21.53
|
||||
card-ease-factor:: 2.32
|
||||
card-last-reviewed:: 2022-11-14T20:19:38.287Z
|
||||
- **Scrum** is an agile project management methodology for managing product development.
|
||||
- It allows us to rapidly and repeatedly inspect actual working software (every two weeks to one month).
|
||||
- The business sets the priorities. The teams **self-manage** to determine the best way to deliver the highest priority features.
|
||||
- Every two weeks to a month, anyone can see real, working software and decide to release it as is or continue to enhance it for another iteration.
|
||||
- ### Characteristics of Scrum #card
|
||||
card-last-score:: 3
|
||||
card-repeats:: 3
|
||||
card-next-schedule:: 2022-11-19T18:30:55.633Z
|
||||
card-last-interval:: 8.32
|
||||
card-ease-factor:: 2.08
|
||||
card-last-reviewed:: 2022-11-11T11:30:55.634Z
|
||||
- Self-organising teams.
|
||||
- No need for project manager (in theory).
|
||||
- Product progresses in a series of month-long or biweekly **sprints**.
|
||||
- Assumes that the software cannot be well defined and requirements will change frequently.
|
||||
- Requirements are captured as items in a list of **product backlog**.
|
||||
- No specific engineering practices prescribed.
|
||||
- XP, TDD, FDD.
|
||||
- Best approach is to start with Scrum and then invent your own version using XP, TDD< FDD, etc.
|
||||
- ### Daily SCRUM / Standup #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-21T00:50:15.178Z
|
||||
card-last-reviewed:: 2022-11-17T09:50:15.179Z
|
||||
card-last-score:: 5
|
||||
- Parameters:
|
||||
- Daily.
|
||||
- 15-minutes.
|
||||
- Stand-up.
|
||||
- **Not** for problem solving.
|
||||
- Only team members, Scrum Master, & Product Owners should talk.
|
||||
- Should help to avoid additional unnecessary meetings.
|
||||
- Commitment in front of peers to complete tasks.
|
||||
- ^^Answer 3 questions:^^
|
||||
- ^^What did you do yesterday?^^
|
||||
- ^^What will you do today?^^
|
||||
- ^^Is anything in your way?^^
|
||||
- The Daily SCRUM is **not** a problem-solving session and is **not** a way to collect information about who is behind the schedule.
|
||||
- It is a meeting in which members make commitments to each other and to the SCRUM Master.
|
||||
- It is a good way for a SCRUM Master to track the progress of the team.
|
||||
-
|
||||
@ -0,0 +1,316 @@
|
||||
- #[[CT255 - Next Generation Technologies II]]
|
||||
- **Previous Topic:** [[GDPR]]
|
||||
- **Next Topic:** [[Human Security & Passwords]]
|
||||
- **Relevant Slides:** 
|
||||
id:: 63265db7-1d41-44f7-b4cf-0bab377a7c1c
|
||||
-
|
||||
- ## SQL Injections
|
||||
- What is an **SQL Injection**? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-09T18:33:16.312Z
|
||||
card-last-reviewed:: 2022-11-11T11:33:16.312Z
|
||||
card-last-score:: 5
|
||||
- An **SQL Injection** is a ***code injection technique*** used to attack data-driven applications, in which malicious SQL statements are inserted for execution.
|
||||
- It is a way of exploiting user input & SQL statements to compromise the database & retrieve sensitive data.
|
||||
-
|
||||
- ## Basic Terminology
|
||||
- What is **Cryptography**? #card
|
||||
card-last-interval:: 108
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 3
|
||||
card-next-schedule:: 2023-03-06T18:36:41.369Z
|
||||
card-last-reviewed:: 2022-11-18T18:36:41.370Z
|
||||
card-last-score:: 5
|
||||
- **Cryptography** is the art of encompassing the principles & methods of transforming an intelligible message into one that is unintelligible, and then retransforming that message back into its original form.
|
||||
- What is **Plaintext**?
|
||||
card-last-score:: 5
|
||||
card-repeats:: 3
|
||||
card-next-schedule:: 2022-10-17T21:24:55.999Z
|
||||
card-last-interval:: 11.2
|
||||
card-ease-factor:: 2.8
|
||||
card-last-reviewed:: 2022-10-06T17:24:55.999Z
|
||||
- **Plaintext** is the ^^original, intelligible message.^^
|
||||
- What is **Ciphertext**?
|
||||
card-last-interval:: 11.2
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-10-18T14:39:00.206Z
|
||||
card-last-reviewed:: 2022-10-07T10:39:00.207Z
|
||||
card-last-score:: 5
|
||||
- **Ciphertext** is the encrypted messsage.
|
||||
- What is a **Cipher**? #card
|
||||
card-last-interval:: 11
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-11-25T16:46:20.520Z
|
||||
card-last-reviewed:: 2022-11-14T16:46:20.520Z
|
||||
card-last-score:: 5
|
||||
- A **Cipher** is an algorithm for transforming an intelligible message into one that is unintelligible.
|
||||
- What is a **Key**? #card
|
||||
card-last-interval:: 9.68
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-11-24T08:37:27.630Z
|
||||
card-last-reviewed:: 2022-11-14T16:37:27.630Z
|
||||
card-last-score:: 5
|
||||
- A **Key** is some critical information used by the cipher, known only to the sender & receiver, selected from a **keyspace** (the set of all possible keys).
|
||||
- What does **Encipher** mean?
|
||||
card-last-score:: 5
|
||||
card-repeats:: 3
|
||||
card-next-schedule:: 2022-10-17T21:14:43.789Z
|
||||
card-last-interval:: 11.2
|
||||
card-ease-factor:: 2.8
|
||||
card-last-reviewed:: 2022-10-06T17:14:43.790Z
|
||||
- **Enciphering** is the process of converting plaintext into ciphertext using a cipher & a key.
|
||||
- What does **Decipher** mean?
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-10-04T12:09:14.829Z
|
||||
card-last-reviewed:: 2022-09-30T12:09:14.829Z
|
||||
card-last-score:: 5
|
||||
- **Deciphering** is the process of converting ciphertext back into plaintext using a cipher & a key.
|
||||
- What is **Encryption**? #card
|
||||
card-last-score:: 5
|
||||
card-repeats:: 4
|
||||
card-next-schedule:: 2022-12-08T06:02:35.168Z
|
||||
card-last-interval:: 23.43
|
||||
card-ease-factor:: 2.42
|
||||
card-last-reviewed:: 2022-11-14T20:02:35.168Z
|
||||
- **Encryption** is some mathematical function $E_K()$ mapping plaintext $P$ to ciphertext $C$ using the specified key $K$.
|
||||
- $$E_K(P) = C$$
|
||||
- What is **Decryption**? #card
|
||||
card-last-interval:: 9.68
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-11-24T08:49:17.364Z
|
||||
card-last-reviewed:: 2022-11-14T16:49:17.365Z
|
||||
card-last-score:: 5
|
||||
- **Decryption** is some mathematical function ${E_K}^{-1}()$ mapping the ciphertext $C$ to plaintext $P$ using the specified key $K$.
|
||||
- $$P={E_K}^{-1}(C)$$
|
||||
- What is **Cryptanalysis**? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-11-16T15:43:11.780Z
|
||||
card-last-reviewed:: 2022-10-19T08:43:11.781Z
|
||||
card-last-score:: 3
|
||||
- **Cryptanalysis** is the study of principles & methods of transforming an unintelligible message into an intelligible message without knowledge of the key.
|
||||
- What is **Cryptology**?
|
||||
card-last-interval:: 9.28
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-10-16T16:40:03.776Z
|
||||
card-last-reviewed:: 2022-10-07T10:40:03.777Z
|
||||
card-last-score:: 5
|
||||
- **Cryptology** is the field encompassing both cryptography & cryptanalysis.
|
||||
-
|
||||
-
|
||||
- ## Model of Conventional Cryptosystem
|
||||
- {:height 304, :width 610}
|
||||
- ## Cryptanalysis via Letter Frequency Distribution
|
||||
- Human languages are **redundant** - letters are not equally commonly used.
|
||||
- In the **English** language:
|
||||
- **E** is by far the most common letter followed by T, R, N, I, O, A, and S.
|
||||
- Other letters like Z, J, K, Q, and X are fairly rare.
|
||||
- Certain letter combinations like **TH** are quite common.
|
||||
- 
|
||||
-
|
||||
- ### C Program for Frequency Analysis of single Characters
|
||||
- ```c
|
||||
#include <stdio.h>
|
||||
#include <string.h>
|
||||
#include <ctype.h>
|
||||
|
||||
int main(int argc, char* argv[]) {
|
||||
FILE* fp;
|
||||
int data[26];
|
||||
char c;
|
||||
|
||||
memset(data, 0, siezof(data));
|
||||
|
||||
if (argc != 2) {
|
||||
return(-1);
|
||||
}
|
||||
if (fp = fopen(argv[1], "r" == NULL)) {
|
||||
return(-2);
|
||||
}
|
||||
|
||||
while(!feof(fp)) {
|
||||
c = toupper(fgetc(fp));
|
||||
|
||||
if ((c >= 'A') && (c <= 'Z')) {
|
||||
data[c-65]++;
|
||||
}
|
||||
}
|
||||
|
||||
for (int i = 0; i < 26; i++) {
|
||||
printf("%c:%i\n", i+65, data[i]);
|
||||
}
|
||||
|
||||
fclose(fp);
|
||||
return(0);
|
||||
}
|
||||
```
|
||||
- ## Known Plaintext Attacks (KPA)
|
||||
- What is a **Known Plaintext Attack (KPA)**? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T03:02:00.417Z
|
||||
card-last-reviewed:: 2022-11-14T20:02:00.417Z
|
||||
card-last-score:: 5
|
||||
- The **Known Plaintext Attack (KPA)** is an attack model for cryptanalysis where the attacker has access to both:
|
||||
- some of, or all of, the plaintext (called a **crib**)
|
||||
- the ciphertext
|
||||
-
|
||||
-
|
||||
- ## Caesar Cipher
|
||||
- What is a **Caesar Cipher**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T11:04:27.582Z
|
||||
card-last-reviewed:: 2022-11-14T20:04:27.582Z
|
||||
card-last-score:: 5
|
||||
- A **Caesar Cipher** involves using an offset alphabet to encrypt a message.
|
||||
- We can use any shift from 1 to 25 to replace each plaintext letter with a letter a fixed distance away.
|
||||
- The **key letter** represents the start of this offset alphabet.
|
||||
- For example, a key letter of F means that A -> F, B -> G, and so on.
|
||||
- ## Playfair Cipher
|
||||
- Not even the large number of keys in a monoalphabetic cipher provides security.
|
||||
- What is a **monoalphabetic cipher**? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T03:02:37.487Z
|
||||
card-last-reviewed:: 2022-11-14T20:02:37.488Z
|
||||
card-last-score:: 5
|
||||
- A **monoalphabetic cipher** is any cipher in which the letters of the plaintext are mapped to ciphertext letters based on a single alphabetic key.
|
||||
- One approach to improving security over monoalphabetic ciphers is to to encrypt ^^multiple letters.^^
|
||||
- The **Playfair Cipher** is one example of such an approach.
|
||||
- The algorithm was invented by Charles Wheatstone in 1854, but named after his friend Baron Playfair.
|
||||
- ### How does the Playfair Cipher work?
|
||||
card-last-score:: 5
|
||||
card-repeats:: 2
|
||||
card-next-schedule:: 2022-10-08T00:33:19.557Z
|
||||
card-last-interval:: 3.51
|
||||
card-ease-factor:: 2.6
|
||||
card-last-reviewed:: 2022-10-04T12:33:19.558Z
|
||||
- 
|
||||
- 1. Create a 5x5 grid of letters; insert the keyword as shown, with each letter only considered once; fill the grid with the remaining letters in alphabetic order.
|
||||
- 2. The letters are then encrypted in pairs.
|
||||
- 3. Repeats have an "X" inserted.
|
||||
- BALLOON -> BA LX LO ON
|
||||
- 4. Letters that fall in the same row are replaced with the letter on the right.
|
||||
- OK -> GM
|
||||
- 5. Letters in the same column are replaced with the letter below.
|
||||
- FO -> OU
|
||||
- 6. Otherwise, each letter gets replaced by the letter in its row but in the other letters column.
|
||||
- QM -> TH
|
||||
- ### Security of the Playfair Cipher
|
||||
- The security is much improved over simple monoalphabetic ciphers, as the Playfair Cipher has $26^2 = 676$ combinations.
|
||||
- This requires a 676 entry frequency table to analyse (as compared to a 26 entry frequency table for a monoalphabetic cipher) and correspondingly, more ciphertext.
|
||||
- However, the Playfair Cipher *can* be cracked through frequency analysis of letter pairs, given a few hundred letters.
|
||||
-
|
||||
- ## Vigenère Cipher
|
||||
- [Blaise de Vigenère](https://en.wikipedia.org/wiki/Blaise_de_Vigen%C3%A8re) is generally credited as the inventor of the **Polyalphabetic Substitution Cipher**.
|
||||
- What is a **Polyalphabetic Substitution Cipher**? #card
|
||||
card-last-interval:: 11.2
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-11-25T20:35:52.727Z
|
||||
card-last-reviewed:: 2022-11-14T16:35:52.727Z
|
||||
card-last-score:: 5
|
||||
- A **Polyalphabetic Substitution Cipher** uses multiple substitution alphabets, as opposed to a monoalphabetic cipher which uses a single alphabetic key.
|
||||
- The Vigenère Cipher improves security by using many monoalphabetic substitution alphabets, so each letter can be replaced by many others.
|
||||
- You use a **key** to select which alphabet is used for each letter of the message.
|
||||
- The $i^{th}$ letter of the key specifies the $i^{th}$ alphabet to use.
|
||||
- Use each alphabet in turn.
|
||||
- Repeat from the start after the end of the key is reached.
|
||||
-
|
||||
- ### Vigenère Steps
|
||||
- 
|
||||
- 1. Write the plaintext out, and write the keyword underneath it, repeated, for the length of the plaintext.
|
||||
- 2. Use each key letter in turn as a Caesar cipher key.
|
||||
- 3. Encrypt the corresponding plaintext letter.
|
||||
- In this example, we use the keyword "CIPHER". Hence, we have the following translation alphabets:
|
||||
- 
|
||||
- ### How to crack the Vigenère Cipher
|
||||
- 1. Search the ciphertext for repeated strings of letters - the longer the string, the better.
|
||||
- 2. For each occurrence of a repeated string, count how many letters are between the first letters in the string, and add one.
|
||||
- 3. Factorise that number.
|
||||
- 4. Repeat this process with each repeated string you find and make a table of common factors. The most common factor, $n$ is most likely the length of the keyword used to encipher the ciphertext.
|
||||
- 5. Do a frequency count on the ciphertext, on every $n^{th}$ letter. You should end up with $n$ different frequency counts.
|
||||
- 6. Compare these counts to standard frequency tables to figure out how much each letter was shifted by.
|
||||
- 7. Undo the shifts and read the message.
|
||||
- ## Enigma (Rotor Ciphers)
|
||||
- ### Rotor Ciphers
|
||||
- The mechanisation / automation of encryption.
|
||||
- An $\text{N}$-stage polyalphabetic algorithm modulo 26.
|
||||
- $26^N$ steps before a repetition, where $N$ is the number of cylinders.
|
||||
- The Enigma machine had 5 cylinders, so:
|
||||
- $$26^{N=5}=11,881,376 \text{ steps}$$
|
||||
-
|
||||
- ### Breaking Enigma using **Cribs**
|
||||
- The starting point for breaking Enigma was based on the following:
|
||||
- Plaintext messages were likely to contain certain phrases.
|
||||
- Weather reports contained the term "WETTER VORHERSAGE".
|
||||
- Military units often sent messages containing "KEINE BESONDEREN EREIGNISSE" ("nothing to report").
|
||||
- A plaintext letter was never mapped onto the same ciphertext letter.
|
||||
- While the cryptanalysts in Bletchely Park did not know exactly where these cribs were placed in an intercepted message, they could exclude certain positions.
|
||||
- 
|
||||
- From here, possible rotor start positions & rotor wiring would be systematically examined using the "bombe" - an electromechanical device designed by Turing that replicated the action of several Enigma machines wired together.
|
||||
-
|
||||
- ## Transposition Ciphers
|
||||
- What are **Transposition Ciphers**? #card
|
||||
card-last-interval:: 21.53
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-12-06T08:01:53.099Z
|
||||
card-last-reviewed:: 2022-11-14T20:01:53.100Z
|
||||
card-last-score:: 5
|
||||
- **Transposition** or **Permutation Ciphers** hide the message by rearranging the letter order ^^without altering the actual letters used.^^
|
||||
- This can be recognised since the ciphertext has the same frequency distribution as the original text.
|
||||
- ### Rail Fence Cipher
|
||||
id:: 6344093b-2f4f-4c58-95e4-39a8b30d16c3
|
||||
- Write plaintext letters out diagonally over a number of rows, then read off the cipher row by row.
|
||||
- 
|
||||
- ### Row Transposition Cipher
|
||||
- What are **Row Transposition Ciphers**? #card
|
||||
card-last-interval:: 86.42
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2023-02-09T06:21:27.811Z
|
||||
card-last-reviewed:: 2022-11-14T20:21:27.811Z
|
||||
card-last-score:: 5
|
||||
- **Row Transposition Ciphers** are a more complex kind of transposition cipher than ((6344093b-2f4f-4c58-95e4-39a8b30d16c3))s.
|
||||
- Plaintext letters are written out in rows over a specified number of columns.
|
||||
- The columns are then re-ordered according to some key before reading off the columns
|
||||
- 
|
||||
-
|
||||
- ## Product Ciphers
|
||||
- Ciphers using just substitutions or transpositions are not secure because of language characteristics.
|
||||
- Consider using several ciphers in succession to make it harder to crack:
|
||||
- Two substitutions make a more complex substitution.
|
||||
- Two transpositions make a more complex transposition.
|
||||
- However, a substitution followed by a transposition makes a much harder cipher.
|
||||
-
|
||||
-
|
||||
- # Steganography
|
||||
- What is **Steganography**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-21T10:35:36.194Z
|
||||
card-last-reviewed:: 2022-11-17T19:35:36.195Z
|
||||
card-last-score:: 5
|
||||
- **Steganography** is an alternative to encryption that hides the existence of the message.
|
||||
- For example:
|
||||
- Using only a subset of letters / words in a message marked in some way.
|
||||
- Using invisible ink.
|
||||
- Hiding in LSB in graphic image or sound file.
|
||||
- The drawback of steganography is that it's not very economical in terms of overheads to hide a message.
|
||||
-
|
||||
@ -0,0 +1,15 @@
|
||||
- #[[CT255 - Next Generation Technologies II]]
|
||||
- Relevant lecture slides: 
|
||||
- No previous topic.
|
||||
-
|
||||
- What is Cybersecurity?
|
||||
card-last-score:: 5
|
||||
card-repeats:: 3
|
||||
card-next-schedule:: 2022-10-13T19:28:22.568Z
|
||||
card-last-interval:: 10.24
|
||||
card-ease-factor:: 2.56
|
||||
card-last-reviewed:: 2022-10-03T14:28:22.568Z
|
||||
- **Cybersecurity** is the practice of protecting systems, networks, and programs from digital attacks.
|
||||
- These cyberattacks are usually aimed at accessing, changing, or destroying sensitive information; extorting money from users; or interrupting normal business processes.
|
||||
- **Next topic:** [[GDPR]]
|
||||
-
|
||||
@ -0,0 +1,24 @@
|
||||
- #[[CT216 - Software Engineering I]]
|
||||
- **Previous Topic:** [[Firebase Functions]]
|
||||
- **Next Topic:**
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Firestore
|
||||
- What is **Firestore**? #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-20T14:34:59.639Z
|
||||
card-last-reviewed:: 2022-11-17T19:34:59.640Z
|
||||
card-last-score:: 5
|
||||
- **Firestore** is a Document Driven Database.
|
||||
- Documents follow a `property:value` format - JSON.
|
||||
- Scalable, highly performant, and document oriented.
|
||||
- The databases tend to scale more easily horizontally.
|
||||
- ## Concepts
|
||||
- Records in Firestore are known as "Documents".
|
||||
- These documents are just JSON data.
|
||||
- Documents are grouped into "Collections" which are equivalent to tables in relational databases.
|
||||
- Queries are still queries, however there is no SQL.
|
||||
- {:height 343, :width 489}
|
||||
-
|
||||
@ -0,0 +1,121 @@
|
||||
- #[[MA284 - Discrete Mathematics]]
|
||||
- **Previous Topic:** [[Advanced PIE, Derangements, & Counting Functions]]
|
||||
- **Next Topic:** [[Definitions & Planar Graphs]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Introduction to Graph Theory
|
||||
- What is a **graph**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-18T20:20:08.384Z
|
||||
card-last-reviewed:: 2022-11-14T20:20:08.384Z
|
||||
card-last-score:: 5
|
||||
- A **graph** is a collection of:
|
||||
- **vertices** (or "nodes"), which are the "dots" in the belong diagram.
|
||||
- **edges** joining a pair of vertices.
|
||||
- 
|
||||
- If the graph is called $G$, we often define it in terms of its **edge set** $E$, and **vertex set** $V$ as
|
||||
- $$G = (V,E)$$
|
||||
- What are **adjacent** vertices? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-18T20:19:56.959Z
|
||||
card-last-reviewed:: 2022-11-14T20:19:56.959Z
|
||||
card-last-score:: 5
|
||||
- If two vertices are connected by an edge, we say that they are **adjacent**.
|
||||
- ## Example
|
||||
- **Aoife, Brian, Conor, David, * Edel are students in an *Indescrete Mathematics* module.**
|
||||
- **Aoife & Conor worked together on the assignment.**
|
||||
- **Brian & David also worked together on their assignment.**
|
||||
- **Edel helped everyone with their assignments.**
|
||||
- **Represent this situation with a graph.**
|
||||
- Let the students be vertices $A$, $B$, $C$, $D$, $E$. An edge represents collaboration between students.
|
||||
- $$V = \{A,B,C,D,E\}$$
|
||||
- $$ E = \{\{A,C\}, \{B,D\}, \{E,A\}, \{E,B\}, \{E,C\}, \{E,D\}\}$$
|
||||
- <img src="https://mermaid.ink/img/ICBmbG93Y2hhcnQgUkwKQSgoQSkpIC0tLSBDKChDKSkKQigoQikpIC0tLSBEKChEKSkKRSgoRSkpIC0tLSBBCkUgLS0tIEIKRSAtLS0gQwpFIC0tLSBECg" />
|
||||
{{renderer :mermaid_fzjdzhfgs}}
|
||||
- ```mermaid
|
||||
flowchart RL
|
||||
A((A)) --- C((C))
|
||||
B((B)) --- D((D))
|
||||
E((E)) --- A
|
||||
E --- B
|
||||
E --- C
|
||||
E --- D
|
||||
```
|
||||
-
|
||||
- # Graph Theory - The Basics
|
||||
- What is the **order** of a graph? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-18T20:20:23.073Z
|
||||
card-last-reviewed:: 2022-11-14T20:20:23.074Z
|
||||
card-last-score:: 5
|
||||
- The **order** of a graph $G = (V,E)$ is the size of its vertex set, $|V|$.
|
||||
- ## Equality & Isomorphism
|
||||
- What makes two graphs **equal**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-18T20:20:18.088Z
|
||||
card-last-reviewed:: 2022-11-14T20:20:18.088Z
|
||||
card-last-score:: 5
|
||||
- Two graphs are **equal** if they have exactly the same Edge & Vertex sets.
|
||||
- That is, ^^it is not important how we draw them^^.
|
||||
- What is an **Isomorphism**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-18T20:17:59.530Z
|
||||
card-last-reviewed:: 2022-11-14T20:17:59.530Z
|
||||
card-last-score:: 3
|
||||
- An **isomorphism** between two graphs, $G_1 = (V_1, E_1)$ & $G_2 = (V_2, E_2)$, is a **bijection** $f: V_1 \rightarrow V_2$ between the vertices in the graph such that, if $\{a, b\}$ is an edge in $G_1$, then $\{f(a), f(b)\}$ is an edge in $G_2$
|
||||
- Two graphs are **isomorphic** if there is an isomorphism between them.
|
||||
- In that case, we write:
|
||||
- $$G_1 \cong G_2$$
|
||||
- ### Example
|
||||
- **Show that the graphs**
|
||||
- $$G_1 = \{V_1, E_1\}, \text{ where } V_1 = \{a,b,c\} \text{, and } E_1 = \{\{a,n\}, \{a,c\}, \{b,c\}\};$$
|
||||
- $$G_2 = \{V_2, E_2\}, \text{ where } V_2 = \{u,v,w\} \text{, and } E_2 = \{\{u,v\}, \{u,w\}, \{v,w\}\};$$
|
||||
- **are not *equal* but are *isomorphic*. **
|
||||
- $V_1 \neq V_2$ so graphs are not equal.
|
||||
- <img src="https://mermaid.ink/img/ICBmbG93Y2hhcnQgVEIKCnN1YmdyYXBoIEcyCnUoKHUpKSAtLS0gdigodikpIC0tLSB3KCh3KSkKZW5kCnN1YmdyYXBoIEcxCmEoKGEpKSAtLS0gYigoYikpIC0tLSBjKChjKSkKZW5kCgo" />
|
||||
{{renderer :mermaid_sewggjymkp}}
|
||||
- ```mermaid
|
||||
flowchart TB
|
||||
|
||||
subgraph G2
|
||||
u((u)) --- v((v)) --- w((w))
|
||||
end
|
||||
subgraph G1
|
||||
a((a)) --- b((b)) --- c((c))
|
||||
end
|
||||
|
||||
```
|
||||
- $f: V_1 \rightarrow V_2$ given by $f(a) = u$, $f(b) = v$, $f(c) = w$ is an isomorphism.
|
||||
- e.g., $\{a,c\} \in E_1$, and $\{f(a), f(c)\} = \{u, w\} \in E_2$.
|
||||
-
|
||||
- What is a **simple graph**? #card
|
||||
card-last-interval:: 2.97
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T19:16:42.421Z
|
||||
card-last-reviewed:: 2022-11-14T20:16:42.421Z
|
||||
card-last-score:: 5
|
||||
- A **simple graph** is one that:
|
||||
- 1. has no **loops** (i.e., no edge from a vertex to itself).
|
||||
2. have no repeated edges (i.e., there is at most one edge between each pair of vertices).
|
||||
- Because simple graphs are so common, usually when we say "graph" we mean "simple graph", unless otherwise stated.
|
||||
- What is a **multigraph**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:14:08.619Z
|
||||
card-last-score:: 1
|
||||
- A **multigraph** is a graph that does have repeated edges.
|
||||
- In a **multirgraph**, the list of edges is not a set, as some elements are repeated. It is a **multiset**.
|
||||
-
|
||||
@ -0,0 +1,142 @@
|
||||
- #[[CT2106 - Object-Oriented Programming]]
|
||||
- **Previous Topic:** [[OOP Modelling]]
|
||||
- **Next Topic:** [[Coding Up Inheritance]]
|
||||
- **Relevant Slides:**  
|
||||
-
|
||||
- # Object Equality #card
|
||||
card-last-interval:: 11.2
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-11-26T00:11:36.263Z
|
||||
card-last-reviewed:: 2022-11-14T20:11:36.264Z
|
||||
card-last-score:: 5
|
||||
- When you use `==` with reference variables, you are checking if the variables **point** to the same object.
|
||||
- So, using `==` on strings will only return true if the Strings are references to the same object. It will return to false even if the strings contain the same data.
|
||||
- The value of a string variable is the **memory location** where its String object is stored.
|
||||
- When checking for equality between objects, you must use the `equals` method.
|
||||
- The `equals` method is an instance method that ^^all objects of built-in classes have.^^
|
||||
- However, for any class that you define, you will have to write your own equals method.
|
||||
- All equals methods must have the following method signature:
|
||||
- ```java
|
||||
public boolean equals(Object object)
|
||||
```
|
||||
- Its specific purpose is to define equality between objects.
|
||||
- It returns a **boolean** value.
|
||||
- It is **commutative**.
|
||||
- `str1.equals(str4)` returns the same value as `str4.equals(str1)`.
|
||||
- Example:
|
||||
- ```java
|
||||
String str1 = "Java";
|
||||
String str2 = "Ja";
|
||||
String str3 = "va";
|
||||
String str4 = str2 + str3;
|
||||
|
||||
str1.equals(str4) ? System.out.println("true") : System.out.println("false");
|
||||
|
||||
```
|
||||
- # `instanceof` #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:42:22.854Z
|
||||
card-last-score:: 1
|
||||
- `instanceof` is an operator that is used to determine if a variable is pointing to an object with a particular type.
|
||||
- ```java
|
||||
System.out.println(bike2 instanceof Bicycle ? "true" : "false");
|
||||
```
|
||||
- # Object
|
||||
collapsed:: true
|
||||
- What is the type of `Object obj`? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-18T16:42:30.590Z
|
||||
card-last-reviewed:: 2022-11-14T16:42:30.590Z
|
||||
card-last-score:: 5
|
||||
- `obj` is a variable whose type is `java.lang.Object`.
|
||||
- What is `java.lang.Object`? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-18T16:42:35.503Z
|
||||
card-last-reviewed:: 2022-11-14T16:42:35.504Z
|
||||
card-last-score:: 5
|
||||
- `java.lang.Object` is a class that provides the ^^most generic definition^^ of an object in Java.
|
||||
- It is the **parent class** of every class in Java.
|
||||
- For example. A `Bicycle` object is a `Bicycle` object **and** a `java.lang.Object` object.
|
||||
-
|
||||
- # Casting
|
||||
- ```java
|
||||
Bicycle bike1 = (Bicycle) myObject;
|
||||
String str1 = (String) obj;
|
||||
```
|
||||
- Here, we can **cast** (convert) a variable from a higher type (`Object`), to a lower type (`Bicycle`).
|
||||
- This is allowed, as `anObject` point to a Bicycle object - we can check this using `instanceof`.
|
||||
- `obj` points to a String object - we can check this using `instanceof`.
|
||||
- Note that the variable type being converted is ^^not the object.^^
|
||||
- # Class Hierarchy
|
||||
- ## Is-a Relationships
|
||||
- Java organises all its classes in a class hierarchy.
|
||||
- For example, a car is a type of vehicle, which is a type of object.
|
||||
- These relationships can be described as "is-a" relationships.
|
||||
- A car **is-a** vehicle; a vehicle **is-a**(n) object.
|
||||
- We refer the higher-up types as **parents** and the lower types as **children**.
|
||||
- Car *is-a child* of Vehicle.
|
||||
- Vehicle *is-a parent* of Car.
|
||||
- Object *is the parent* of Vehicle & Car.
|
||||
- ## Key Ideas in Class Hierarchy
|
||||
- The top of the hierarchy represents the ^^most **generic** attributes & behaviours.^^
|
||||
- The bottom (sometimes referred to as "leaves") represent the ^^most **specific** attributes & behaviours.^^
|
||||
- Each level inherits and customises the attributes & behaviours from the level above it.
|
||||
- `java.lang.Object` is *the* **superclass**, the parent of all classes in Java.
|
||||
- Every class in Java has the `java.lang.Object` as its superclass (parent).
|
||||
- 
|
||||
- All the classes shown above **inherit** (receive) methods from the superclass `java.lang.Object`.
|
||||
- What is **OOP Inheritance**? #card
|
||||
card-last-interval:: 5.52
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-20T04:38:03.406Z
|
||||
card-last-reviewed:: 2022-11-14T16:38:03.406Z
|
||||
card-last-score:: 5
|
||||
- **Inheritance** is the means by which objects automatically receive features (fields) & behaviours (methods) from their **superclass**.
|
||||
- The methods of this superclass are available to all objects of this Class, even though these methods may not be shown in the Class code.
|
||||
- For example: `.equals()`.
|
||||
- ### Generic Methods
|
||||
- All the methods provided by the `java.lang.Object` are *generic*.
|
||||
- They only relate to `java.lang.Object` classes, not the subclasses.
|
||||
- When a subclass inherits these methods, it needs to customise them.
|
||||
- This is why we had to override `.equals()` with our own version for the example Bicycle class.
|
||||
- ### Overriding
|
||||
- What is **overriding**? #card
|
||||
card-last-interval:: 29.99
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-12-14T19:04:47.436Z
|
||||
card-last-reviewed:: 2022-11-14T20:04:47.437Z
|
||||
card-last-score:: 5
|
||||
- **Overriding** is when you write your own version of a method that you have inherited from a superclass.
|
||||
- It is creating a specific version of a method inherited from a parent (superclass) class.
|
||||
- When overriding a method, you must keep every part of the method signature the same - You can only change the code in the method body.
|
||||
- Its name, its parameter types & order, its access level (e.g., public, protected), and its return type.
|
||||
- #### Annotation
|
||||
- It is good practice to **annotate** your overridden methods using `@Override`.
|
||||
- You code will compile & run without it, but it is considered good practice to annotate the methods that are overridden inherited from the superclass.
|
||||
- ```java
|
||||
@Override
|
||||
public boolean equals(Object obj)
|
||||
{
|
||||
obj == null ? return false;
|
||||
|
||||
if (obj instanceof Bicycle)
|
||||
{
|
||||
Bicycle bike = (Bicycle) obj;
|
||||
if (this.speed == bike.getSpeed() && this.gear == bike.getGear())
|
||||
{
|
||||
return true;
|
||||
}
|
||||
}
|
||||
return false;
|
||||
}
|
||||
```
|
||||
66
year2/semester1/logseq-stuff/pages/Introduction to Java.md
Normal file
66
year2/semester1/logseq-stuff/pages/Introduction to Java.md
Normal file
@ -0,0 +1,66 @@
|
||||
- #[[CT2106 - Object-Oriented Programming]]
|
||||
- **Previous Topic:** [[Introduction to Object-Oriented Programming]]
|
||||
- **Next topic:** [[First Java Code]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- ## High-Level Language
|
||||
- Both Java and C are **high-level languages** and Assembly is a **low-level language**.
|
||||
- "**High-Level**" is a *relative* term.
|
||||
- A **High-Level Language** is the level of abstraction above a **Low-Level Language**.
|
||||
- A **Low-Level Language** has little or no abstraction over the machine code of a particular processor.
|
||||
- ### Advantages of High-Level Programming Languages
|
||||
- Easier to program.
|
||||
- Syntax can be understood by people.
|
||||
- Programs take less time to write, are shorter, & easier to read, so they are more likely to be correct.
|
||||
- Portable - they can be run on different kinds of computers.
|
||||
-
|
||||
-
|
||||
- ## Translating Your Code
|
||||
- Unless you are writing Machine Code, your code has to be translated into machine code to be run on your computer.
|
||||
- There are two types of translation:
|
||||
- 1. **Compilation**.
|
||||
2. **Interpretation**
|
||||
-
|
||||
- ### Compilation
|
||||
- What is a **Compiler**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:44:08.310Z
|
||||
card-last-reviewed:: 2022-11-14T16:44:08.310Z
|
||||
card-last-score:: 5
|
||||
- A **compiler** is a program that takes human-readable source code and translates it in one go into Machine Code.
|
||||
- With compilation, "translation" occurs ^^before the program is run.^^
|
||||
- Machine Code generated by compilation is **not portable**.
|
||||
- However, the generated Machine Code typically executes **very efficiently**.
|
||||
- For big projects, the compile time can be slow.
|
||||
- ### Interpretation
|
||||
- Code is "translated"" on-the-fly at runtime into commands that can be executed on the machine.
|
||||
- Code is read & executed by the **interpreter** when the program is run.
|
||||
- Interpreted code is **portable** (as long as there is an interpreter).
|
||||
- Typically, interpreted code is ^^slower to run^^ as each statement has to be interpreted into machine code **on-the-fly**.
|
||||
- Greater chance of run-time errors.
|
||||
-
|
||||
- ^^Java is typically both *compiled* **and** *interpreted*.^^
|
||||
- ^^Java is **compiled** to *Byte Code* - an *intermediate language* which is portable.^^
|
||||
- ^^This Byte Code is then **read** and **executed** by a Java **interpreter**.^^
|
||||
-
|
||||
-
|
||||
- ## Java Virtual Machine (JVM)
|
||||
- What is the **JVM**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:38:43.908Z
|
||||
card-last-reviewed:: 2022-11-14T16:38:43.909Z
|
||||
card-last-score:: 5
|
||||
- The **Java Virtual Machine (JVM)** is a piece of software - a *virtual computer* upon which **Java byte code** is executed.
|
||||
- What is the **JRE**? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-12T23:43:23.817Z
|
||||
card-last-reviewed:: 2022-11-14T16:43:23.818Z
|
||||
card-last-score:: 3
|
||||
- The **Java Runtime Environment (JRE)** contains the JVM and all the libraries required to run the Java progam.
|
||||
-
|
||||
23
year2/semester1/logseq-stuff/pages/Introduction to NodeJS.md
Normal file
23
year2/semester1/logseq-stuff/pages/Introduction to NodeJS.md
Normal file
@ -0,0 +1,23 @@
|
||||
- #[[CT216 - Software Engineering I]]
|
||||
- **Previous Topic:** [[JavaScript Functions & Events]]
|
||||
- **Next Topic:** [[Firebase Functions]]
|
||||
- **Relevant Slides:**  
|
||||
-
|
||||
- # Background
|
||||
- **V8** is an open-source JavaScript engine developed by Google, written in C++ and used in the Google Chrome browser.
|
||||
- **Node.js** runs on the V8 engine, written in JavaScript & C++.
|
||||
- It's not a programming lanuage - it's a runtime environment.
|
||||
- In simple terms, Node.js is "server-side JS".
|
||||
- It is a high-performance network applications application that is well-optimised for high concurrent environments.
|
||||
- # Rest APIs
|
||||
- What is an **API**? #card
|
||||
card-last-interval:: 0.98
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T15:24:31.946Z
|
||||
card-last-reviewed:: 2022-11-14T16:24:31.946Z
|
||||
card-last-score:: 3
|
||||
- An **Application Programming Interface (API)** expresses a software component in terms of its operations, inputs, outputs, & underlying types.
|
||||
- ## Adding Firebase Functions
|
||||
- We are using Firebase functions to host our REST APIs.
|
||||
-
|
||||
@ -0,0 +1,40 @@
|
||||
- #[[CT2106 - Object-Oriented Programming]]
|
||||
- No previous topic
|
||||
- **Next Topic:** [[Introduction to Java]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- ## Definitions
|
||||
- What is a **class**? #card
|
||||
card-last-interval:: 23.43
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-12-02T22:44:35.056Z
|
||||
card-last-reviewed:: 2022-11-09T12:44:35.056Z
|
||||
card-last-score:: 3
|
||||
- A **class** is a type of *blueprint* or *template* from which you make objects.
|
||||
- What is an **object**? #card
|
||||
card-last-interval:: 27.13
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-12-11T23:00:56.373Z
|
||||
card-last-reviewed:: 2022-11-14T20:00:56.374Z
|
||||
card-last-score:: 5
|
||||
- A (Java) **object** is a self-contained component which consists of *methods* and *properties*.
|
||||
- It is a piece of code that has a **state** and has **behaviour**.
|
||||
- Often, they represent a "real-life" object.
|
||||
- An object is created by *instantiating* a **class**.
|
||||
- What is **bytecode**? #card
|
||||
card-last-interval:: 29.26
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T22:39:29.786Z
|
||||
card-last-reviewed:: 2022-11-14T16:39:29.787Z
|
||||
card-last-score:: 5
|
||||
- Unlike other high-level programming languages, Java code is **not** compiled into machine-specific code that can be executed by a microprocessor.
|
||||
- Instead, Java programs are compiled into **bytecode**. The bytecode is input into a **Java Virtual Machine (JVM)**, which interprets & executes the code. The JVM is usually a program itself.
|
||||
- Bytecode is **platform independent**.
|
||||
- The JVM is specific for each platform, but the bytecode for the program remains the same across different platforms.
|
||||
- The main trade-off is the effect it has on the execution speed.
|
||||
-
|
||||
-
|
||||
-
|
||||
364
year2/semester1/logseq-stuff/pages/Introduction to SQL & DDL.md
Normal file
364
year2/semester1/logseq-stuff/pages/Introduction to SQL & DDL.md
Normal file
@ -0,0 +1,364 @@
|
||||
- #[[CT230 - Database Systems I]]
|
||||
- **Previous Topic:** [[The Relational Model]]
|
||||
- **Next Topic:** [[SQL DML Statement]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # SQL
|
||||
- What is **SQL**? #card
|
||||
card-last-interval:: 31.36
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-12-18T17:47:35.469Z
|
||||
card-last-reviewed:: 2022-11-17T09:47:35.470Z
|
||||
card-last-score:: 5
|
||||
- **Structured Query Language (SQL)** is a special-purpose **programming language** for relational database systems.
|
||||
- ### Features of SQL
|
||||
- SQL is based on *relational algebra*.
|
||||
- All relational, set, and hybrid operators are supported.
|
||||
- SQL also has additional operators to allow easier query development.
|
||||
- SQL has been *standardised* since 1987.
|
||||
- The American National Standards Institute (ANSI) and International Organization for Standardization (ISO) form SQL standard committees. Many vendors also take part.
|
||||
- Recent standards include XML-related features in addition to many others, including JSON data types.
|
||||
- ### ANSI/ISO SQL
|
||||
- Despite standards, there can be a lack of portability between database systems due to:
|
||||
- Complexity & size of standards (not all vendors will implement all of the standard).
|
||||
- The vendor may want to keep the syntax consistent with their other software products / OS or develop features to support their user base.
|
||||
- The vendor may want to maintain backward compatibility.
|
||||
- The vendor may want to maintain "Vendor lock-in".
|
||||
- What is the **standardised SQL syntax** comprised of? #card
|
||||
card-last-interval:: 10.6
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-25T06:29:02.836Z
|
||||
card-last-reviewed:: 2022-11-14T16:29:02.836Z
|
||||
card-last-score:: 5
|
||||
- The **standardised SQL syntax** comprises 3 components:
|
||||
- **DDL -** Data Definition Language
|
||||
- **DCL -** Data Control Language
|
||||
- **DML -** Data Manipulation Language
|
||||
- ### DCL: Data Control Language
|
||||
- What is **DCL** used for? #card
|
||||
card-last-interval:: 31.36
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-12-16T04:21:50.434Z
|
||||
card-last-reviewed:: 2022-11-14T20:21:50.434Z
|
||||
card-last-score:: 5
|
||||
- **Data Control Language** is used to control access to the database & to database relations.
|
||||
- It is the role of the **database administrator**.
|
||||
- Very important in multi-user systems.
|
||||
- What are the typical **DCL** commands? #card
|
||||
card-last-interval:: 41.44
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-26T06:18:39.799Z
|
||||
card-last-reviewed:: 2022-11-14T20:18:39.800Z
|
||||
card-last-score:: 5
|
||||
- ```sql
|
||||
GRANT
|
||||
REVOKE
|
||||
```
|
||||
- These can be used to:
|
||||
- grant / revoke access to the database.
|
||||
- grant / revoke access to individual relations.
|
||||
-
|
||||
- ### DDL: Data Definition Language
|
||||
- What is **DDL**? #card
|
||||
card-last-interval:: 86.42
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2023-02-09T06:22:06.927Z
|
||||
card-last-reviewed:: 2022-11-14T20:22:06.927Z
|
||||
card-last-score:: 5
|
||||
- **Data Definition Language** is a standardised language to ^^define the schema of a database.^^
|
||||
- It's the back-end of "design" options on the Interface (e.g., Create options).
|
||||
- What are the typical **DDL** commands? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:36:00.957Z
|
||||
card-last-score:: 1
|
||||
- The typical DDL tasks include creating, altering, and removing **database objects** such as tables & indexes.
|
||||
- Common DDL keywords include:
|
||||
- ```sql
|
||||
CREATE
|
||||
ALTER
|
||||
DROP
|
||||
ADD
|
||||
CONSTRAINT
|
||||
```
|
||||
- #### Create a table, its indexes, & constraints
|
||||
- Steps:
|
||||
- 1. Specify **table** (relation) name.
|
||||
2. For each attribute in the table, specify **Attribute Name**, **Data Type**, and any **constraints**.
|
||||
3. Specify the **Primary Key** of the table: choose one or more attributes.
|
||||
4. Specify **Foreign Keys** *if they exist* and assuming that the attributes & table you are referencing exist (you may have to return to this step).
|
||||
- Steps 1-3 ^^must be completed for all tables.^^
|
||||
- #### Data Types
|
||||
- The main data types are **strings**, **numeric**, and **date/time**.
|
||||
-
|
||||
- **Strings**
|
||||
- What can **strings** contain? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:37:34.017Z
|
||||
card-last-reviewed:: 2022-11-14T16:37:34.018Z
|
||||
card-last-score:: 5
|
||||
- **Strings** can contain ^^letters, numbers, & special characters.^^
|
||||
- Types of string: #card
|
||||
card-last-interval:: 23.43
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-12-08T06:03:14.822Z
|
||||
card-last-reviewed:: 2022-11-14T20:03:14.822Z
|
||||
card-last-score:: 3
|
||||
- `CHAR(size)` is a string of **fixed length**. `size` can be from 0 to 255 - the default is 1.
|
||||
- `VARCHAR(size)` is a string of **variable length**. `size` can be from 0 to 65,535.
|
||||
- if `size` is not specified, it is unlimited
|
||||
- `TEXT` is the same thing as `VARCHAR` except it is unlimited by default, and takes no argument `size`.
|
||||
-
|
||||
- **Date/Time**
|
||||
- Types of date/time: #card
|
||||
card-last-interval:: 47.41
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.28
|
||||
card-next-schedule:: 2023-01-01T05:18:44.919Z
|
||||
card-last-reviewed:: 2022-11-14T20:18:44.919Z
|
||||
card-last-score:: 3
|
||||
- `DATE` Format: YYYY-MM_DD
|
||||
- `TIME` Format: hh:mm:ss
|
||||
- `DATETIME` Format: YYYY-MM-DD hh:mm:ss
|
||||
- `YEAR` A year in four-digit format
|
||||
-
|
||||
- **Numeric**
|
||||
- The maximum `size` value is 255.
|
||||
- MySQL supports **unsigned** numeric types but not all DBMS do.
|
||||
- Types of numerics: #card
|
||||
card-last-interval:: 19.01
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-03T16:48:07.382Z
|
||||
card-last-reviewed:: 2022-11-14T16:48:07.383Z
|
||||
card-last-score:: 3
|
||||
- `INTEGERS` - *See next block*.
|
||||
- `BOOL / BOOLEAN` - 0 is False; non-zero is True.
|
||||
- `FLOAT` - A floating-point number. 4 bytes, single precision.
|
||||
- `DOUBLE` - A floating-point number. 8 bytes, double precision.
|
||||
- `DECIMAL(size, d) / DEC(size,d)` - An exact, fixed-point number.
|
||||
- `size` = total number of digits (max 65, default 10)
|
||||
- `d` = number of digits after the decimal point (max 30, default 0)
|
||||
-
|
||||
- **Integers**
|
||||
- Types of integers:
|
||||
- | **Type** | **Bytes** | **Range** |
|
||||
| `TINYINT` | 1 | -128 to 127 |
|
||||
| `SMALLINT` | 2 | -32,768 to 32,767 |
|
||||
| `MEDIUMINT` | 3 | -8,388,608 to 8,388,607 |
|
||||
| `INT` | 4| -2,147,483,648 to 2,147,483,647 |
|
||||
| `BIGINT` | 8 | -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807 |
|
||||
- ^^Note:^^ the number in brackets next to integers only refers to the number of digits to display, not size.
|
||||
-
|
||||
- **Others**
|
||||
- Unicode char/string
|
||||
- Binary
|
||||
- Blob, Json, etc.
|
||||
- ### DML: Data Manipulation Language
|
||||
- What is **DML**? #card
|
||||
card-last-interval:: 25.4
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.52
|
||||
card-next-schedule:: 2022-12-12T18:47:31.780Z
|
||||
card-last-reviewed:: 2022-11-17T09:47:31.780Z
|
||||
card-last-score:: 5
|
||||
- **Data Manipulation Language** is a standardised language used for ^^adding, deleting, & modifying data in a database.^^
|
||||
- What are the typical **DML** commands? #card
|
||||
card-last-interval:: 15.05
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 1.94
|
||||
card-next-schedule:: 2022-11-29T17:40:29.100Z
|
||||
card-last-reviewed:: 2022-11-14T16:40:29.100Z
|
||||
card-last-score:: 3
|
||||
- ```sql
|
||||
INSERT -- insert data
|
||||
SELECT -- query (select) data
|
||||
UPDATE -- update data
|
||||
DELETE -- delete data
|
||||
```
|
||||
-
|
||||
- # Autonumber
|
||||
- What does `AUTO_INCREMENT` do in MySQL? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T03:03:50.803Z
|
||||
card-last-reviewed:: 2022-11-14T20:03:50.803Z
|
||||
card-last-score:: 5
|
||||
- Specifying an attribute to `AUTO_INCREMENT` tells the DBMS to ^^generate a number automatically when a new tuple is inserted into a table.^^
|
||||
- Often, this is used for an "artificial" **primary key** value which is needed to ensure that we have a primary key, but has no meaning for the data being stored.
|
||||
- Using `AUTO_INCREMENT` means that the DBMS takes care of inserting a unique value automatically every time a new tuple is inserted.
|
||||
- By default, `AUTO_INCREMENT` is **1**, and is incremented by 1 for each new tuple inserted.
|
||||
-
|
||||
- # Constraints
|
||||
- ## Types of Constraints
|
||||
- ### Foreign Keys
|
||||
- What is the syntax for specifying **Foreign Keys**? #card
|
||||
card-last-interval:: 41.44
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-26T06:21:18.467Z
|
||||
card-last-reviewed:: 2022-11-14T20:21:18.468Z
|
||||
card-last-score:: 3
|
||||
- ```sql
|
||||
FOREIGN KEY (attributename) REFERENCES tablename(attributename)
|
||||
```
|
||||
- You need to specify:
|
||||
- The keyword `FOREIGN KEY` to indicate that it is a foreign key constraint.
|
||||
- The attribute name(s) that will identify the foreign keys in the current table.
|
||||
- If there is more than one attribute, they should be separated by commas.
|
||||
- Attribute names should be enclosed in brackets.
|
||||
- The keyword `REFERENCES` to specify the attribute that the foreign key references.
|
||||
- The table name and the attribute name of the attribute being referenced by the foreign key.
|
||||
- Again, the attribute name(s)should be in brackets.
|
||||
- The table name should be **outside** the brackets.
|
||||
- ^^You cannot create a foreign key link unless the attribute that it is referencing exists.^^
|
||||
- ### Using `ALTER` to Modify Design
|
||||
- **Remember:** You cannot create a foreign key link *unless* the attribute it's referencing already exists.
|
||||
- If you want to create everything but the foreign keys initially, you can add a foreign key later using the `ALTER TABLE` command
|
||||
-
|
||||
- #### Syntax for `ALTER` Command
|
||||
- To add a constraint:
|
||||
- ```SQL
|
||||
ALTER TABLE tablename
|
||||
ADD CONSTRAINT constraintname FOREIGN KEY (attributename) REFERENCES tablename(attribute name);
|
||||
```
|
||||
- To add an attribute (column) constraint:
|
||||
- ```SQL
|
||||
ALTER TABLE tablename
|
||||
ADD attributename DATATYPE;
|
||||
```
|
||||
- ### Domain Constraints
|
||||
id:: 6321ba81-0b92-447e-9c6f-1953528d51a8
|
||||
- What is the **Domain Constraint**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:38:56.391Z
|
||||
card-last-score:: 1
|
||||
- The value of each attribute A must be an **atomic** value from the **domain** dom(A).
|
||||
- Essentially: ^^the data types & formats must match to that specified.^^
|
||||
- ### Entity Integrity Constraints (Primary Key Constraints)
|
||||
id:: 6321bafc-6bfc-42da-96a9-f05bcfdff9ba
|
||||
- What is the **Primary Key / Entity Integrity Constraint**? #card
|
||||
card-last-interval:: 31.36
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-12-16T00:47:09.544Z
|
||||
card-last-reviewed:: 2022-11-14T16:47:09.544Z
|
||||
card-last-score:: 5
|
||||
- The **primary key** should uniquely identify each tuple in a relation.
|
||||
- This means:
|
||||
- No duplicate values allowed for the primary key
|
||||
- No `NULL`values allowed for the primary key
|
||||
- **Note:** `NULL` values may possibly also not be permitted for other attributes.
|
||||
- We often see this constraint when filling out forms online ("*required") and the constraint is often necessary for non-key attributes.
|
||||
- However, we should be careful to only add `NOT NULL` constraints in the databases when they are really necessary.
|
||||
-
|
||||
- ### Referential Integrity Constraints
|
||||
- What are **Referential Integrity Constraints**? #card
|
||||
card-last-score:: 1
|
||||
card-repeats:: 1
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-interval:: -1
|
||||
card-ease-factor:: 2.56
|
||||
card-last-reviewed:: 2022-11-14T20:19:00.925Z
|
||||
- **Referential Integrity Constraints** are specified between two relations and require the concept of a **foreign key**. The constraint ensures that ^^the database must **not** contain any unmatched foreign keys.^^
|
||||
- Therefore, a relationship involving foreign keys **must** be between attributes of the ^^same type & size.^^
|
||||
- In addition, a value for a foreign key attribute **must** exist already as a candidate key value.
|
||||
- Essentially: "no unmatched foreign keys".
|
||||
-
|
||||
- ### Semantic Integrity Constraints
|
||||
- What are **Semantic Integrity Constraints**? #card
|
||||
card-last-interval:: 56.69
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2023-01-07T03:37:12.551Z
|
||||
card-last-reviewed:: 2022-11-11T11:37:12.551Z
|
||||
card-last-score:: 5
|
||||
- **Semantic Integrity Constraints** ensure that the data entered into a row reflects an allowable value for that row. The value must be within the *domain*, or allowable set of values, for that column.
|
||||
- How are **Semantic Integrity Constraints** specified? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:42:45.174Z
|
||||
card-last-score:: 1
|
||||
- **Semantic Integrity Constraints** are specified & enforced using a *constraint specification language*.
|
||||
- What are the two types of **Semantic Integrity Constraints**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-11-25T13:05:15.346Z
|
||||
card-last-reviewed:: 2022-11-21T13:05:15.347Z
|
||||
card-last-score:: 3
|
||||
- **State Constraints:** Constrain an entity to being in certain states.
|
||||
- **Transition Constraints:** Constrain an entity to only being updated in certain ways.
|
||||
- ## Setting Constraints
|
||||
- **Domain Constraints** are set automatically once the data type is chosen.
|
||||
- **Entity Constraints** are also set automatically once a primary key has been chosen.
|
||||
- Usually default constraints are set for foreign keys, but these can be changed.
|
||||
-
|
||||
- ## Update Operations & Constraint Violations
|
||||
- The DBMS must check that the constraints are not violated whenever **update operations** are applied.
|
||||
-
|
||||
- ### Insert Operation
|
||||
- What does the **Insert Operation** do? #card
|
||||
card-last-interval:: 31.36
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-12-16T00:47:14.600Z
|
||||
card-last-reviewed:: 2022-11-14T16:47:14.600Z
|
||||
card-last-score:: 5
|
||||
- The **Insert Operation** provides a list of attribute values for a new tuple $t$ that is to be inserted into a relation $R$.
|
||||
- This can happen directly via the interface or via the query.
|
||||
- If a constraint is violated, the DBMS will reject the insertion - usually with an explanation.
|
||||
- ### Delete Operation
|
||||
- How can a **Delete Operation** violate constraints? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T03:03:33.858Z
|
||||
card-last-reviewed:: 2022-11-14T20:03:33.859Z
|
||||
card-last-score:: 5
|
||||
- A **delete operation** can only violate **integrity constraints**, i.e., if the tuple being deleted is referenced by the foreign key from other tuples.
|
||||
- The DBMS can:
|
||||
- reject deletion, usually within an explanation.
|
||||
- attempt to *cascade* deletion.
|
||||
- modify referencing attribute.
|
||||
- #### Update Operation
|
||||
card-last-score:: 1
|
||||
card-repeats:: 1
|
||||
card-next-schedule:: 2022-10-07T23:00:00.000Z
|
||||
card-last-interval:: -1
|
||||
card-ease-factor:: 2.5
|
||||
card-last-reviewed:: 2022-10-07T10:32:05.858Z
|
||||
- What is an **Update** Operation? #card
|
||||
card-last-interval:: 8.88
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-20T08:30:42.712Z
|
||||
card-last-reviewed:: 2022-11-11T11:30:42.713Z
|
||||
card-last-score:: 3
|
||||
- An **update** operation is used to change the values of one or more attributes in a tuple of a table.
|
||||
- Issues already discussed with insert & delete could arise with this operation, specifically:
|
||||
- If a primary key is modified, that's essentially the same as deleting one tuple and inserting another tuple in its place.
|
||||
- If a foreign key is modified, the DBMS must ensure that the new value refers to an existing tuple in the reference relation.
|
||||
- ### Cascade Update & Delete
|
||||
- Whenever tuples in the **referenced** (master) table are deleted or updated, the respective tuples of the **referencing** (child) table with a matching foreign key column will be deleted or updated as well.
|
||||
- Note that if cascading `DELETE` is turned on, there could be many deletions performed with a single query such as:
|
||||
- ```sql
|
||||
DELETE FROM employee
|
||||
WHERE ssn = 12345678;
|
||||
```
|
||||
@ -0,0 +1,51 @@
|
||||
- #[[CT216 - Software Engineering I]]
|
||||
- **Previous Topic:** [[Bootstrap CSS]]
|
||||
- **Next Topic:** [[Introduction to NodeJS]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Functions
|
||||
collapsed:: true
|
||||
- A function can be named or it can be anonymous.
|
||||
- ## ES6 Arrow Functions
|
||||
- Arrow functions are more concise - a developer can achieve the same functionality with fewer lines of code.
|
||||
- ```javascript
|
||||
// ES6 Arrow Function
|
||||
(param1, param2) =>
|
||||
{
|
||||
return param1 * param2;
|
||||
}
|
||||
|
||||
// ES5 Traditional Function
|
||||
function(param1, param2)
|
||||
{
|
||||
return param1 * param2;
|
||||
}
|
||||
```
|
||||
- ## Assigning a Function to a Variable
|
||||
- ```javascript
|
||||
let multiply = (param1, param2) => {
|
||||
return param1 * param2;
|
||||
}
|
||||
multiply(2,3)
|
||||
```
|
||||
- # Events
|
||||
- An **event** is an action that can be responded to by JavaScript.
|
||||
- Every element on a page has certain events which can trigger some code.
|
||||
- We can identify when a user clicks a button with the `onClick` event.
|
||||
- ## Event Examples
|
||||
- ### Mouse Events
|
||||
- `onClick`: Triggered when the mouse clicks on an element.
|
||||
- `onMouseDown`: Triggered when the mouse button is pressed.
|
||||
- `onMouseUp`: Triggered when the mouse button is released.
|
||||
- `onMouseOver`: Triggered for an element when the mouse cursor is moved over that element.
|
||||
- `onMouseOut`: Triggered for an element when the mouse cursor is moved away from that element.
|
||||
- ### Selecting & De-Selecting Elements
|
||||
- `onFocus`: Triggered when an element gets focus.
|
||||
- `onBlur`: Triggered when an element loses focus.
|
||||
- `onChange`: Triggered when the content of an element changes.
|
||||
- ### Keyboard Events
|
||||
- `onKeyDown`: Triggered when a keyboard key is pressed.
|
||||
- `onKeyUp`: Triggered when a keyboard key is released.
|
||||
- `onKeyPress`: Triggered when a keyboard key is pressed or held.
|
||||
- `onSelect`: Triggered when text is selected.
|
||||
-
|
||||
180
year2/semester1/logseq-stuff/pages/Joins & Union Queries.md
Normal file
180
year2/semester1/logseq-stuff/pages/Joins & Union Queries.md
Normal file
@ -0,0 +1,180 @@
|
||||
- #[[CT230 - Database Systems I]]
|
||||
- **Previous Topic:** [[Entity Relationship Models]]
|
||||
- **Next Topic:** [[Normalisation]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Joins
|
||||
- What are **Joins**? #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-20T04:49:32.456Z
|
||||
card-last-reviewed:: 2022-11-17T09:49:32.458Z
|
||||
card-last-score:: 5
|
||||
- ^^**Joins** combine multiple tables into one table.^^
|
||||
- This new (temporary) table is then queried to return results so that we can return values from any of the table that were joined.
|
||||
- Tables are joined by specifying links (**joins**) across attributes in the tables.
|
||||
- Joins are carried out on 2 tables at a time, but many tables can be joined in one.
|
||||
- For example, a third table could be joined to a table that results from joining two tables.
|
||||
- ## Specifying Joins #card
|
||||
card-last-interval:: 0.88
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-18T06:49:54.055Z
|
||||
card-last-reviewed:: 2022-11-17T09:49:54.056Z
|
||||
card-last-score:: 3
|
||||
- [1]. In SQL, we must specify *all the tables* that are part of the join in the `FROM` clause.
|
||||
- [2]. We must then specify the **join condition** - for an inner join, the condition is `foreign_key = primary_key / candidate_key`.
|
||||
- [3]. The join condition can be specified in the `FROM` or `WHERE` clause.
|
||||
- ## Different Types of Joins
|
||||
- **Inner Join** is the default when using an **implicit join**.
|
||||
- For **explicit joins**, we must explicitly state the join used.
|
||||
- 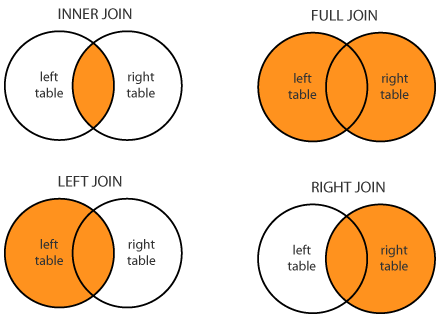
|
||||
- ### Inner Joins #card
|
||||
card-last-interval:: 0.88
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-18T06:49:01.559Z
|
||||
card-last-reviewed:: 2022-11-17T09:49:01.559Z
|
||||
card-last-score:: 3
|
||||
- An `INNER JOIN` includes the tuples from the first (left) of the two tables ^^only when they satisfy the join condition^^ and tuples from the second (right) table ^^only when they also satisfy the join condition.^^
|
||||
- Example:
|
||||
- ```sql
|
||||
SELECT *
|
||||
FROM employee INNER JOIN dependent
|
||||
ON ssn = essn;
|
||||
```
|
||||
- ### Left Joins #card
|
||||
card-last-interval:: 0.98
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T19:06:39.454Z
|
||||
card-last-reviewed:: 2022-11-14T20:06:39.455Z
|
||||
card-last-score:: 3
|
||||
- **Left (outer) joins** include all of the tuples from the first (left) of two tables, regardless of whether or not they satisfy the join condition or if there are matching values in the second (right) table.
|
||||
- Tuples from the second (right) table are only included when they satisfy the join condition.
|
||||
- [Essentially the same as right joins.]
|
||||
- Example:
|
||||
- ```sql
|
||||
SELECT *
|
||||
FROM employee LEFT JOIN department ON
|
||||
employee.ssn = department.mgrssn;
|
||||
```
|
||||
- ### Right Joins #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-20T04:49:38.317Z
|
||||
card-last-reviewed:: 2022-11-17T09:49:38.317Z
|
||||
card-last-score:: 5
|
||||
- **Right (outer) joins** include all of the tuples from the second (right) table, regardless of whether or not they satisfy the join condition or if there are matching values in the first (left) table.
|
||||
- Tuples from the first (left) table are include only if the satisfy the join condition.
|
||||
- [Essentially the same as left joins.]
|
||||
- Example:
|
||||
- ```sql
|
||||
SELECT *
|
||||
FROM employee RIGHT JOIN department ON
|
||||
employee.ssn = department.mgrssn;
|
||||
```
|
||||
- ## Inner Joining Tables #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:05:20.530Z
|
||||
card-last-score:: 1
|
||||
- The results of an inner join operation between two tables $R(A_1, A_2, \dots, A_n)$ and $S(B_1, B_2, \dots, B_m)$ is a table $Q(A_1, A_2, \dots, A_n, B_1, B_2, \dots, B_m)$.
|
||||
- $Q$ has one tuple for each combination of tuples (one from $R$ & one from $S$) ^^whenever the combination satisfies the join condition^^ - the join will retrieve **all** attributes in each table.
|
||||
- ### Example: Inner Join Condition for the `employee` & `dependent` Tables
|
||||
- **Join Condition:** `ssn = essn`.
|
||||
- Full query retrieving all employees & their dependents (*dependants* in non-American English), when they have dependents:
|
||||
- ```SQL
|
||||
SELECT *
|
||||
FROM employee INNER JOIN dependent
|
||||
ON ssn = essn;
|
||||
```
|
||||
- #### Note
|
||||
- When attributes with the same name from different tables are used in a join query, you need to specify the table name to avoid ambiguity.
|
||||
- For example:
|
||||
- `bdate` in `employee` & `dependent`.
|
||||
- We can refer to these unambiguously as `employee.bdate` & `dependent.bdate`.
|
||||
-
|
||||
- ## Implicit & Explicit Joins
|
||||
- The **join condition** can be specified *implicitly* or *explicitly*.
|
||||
- What is an **explicit join**? #card
|
||||
card-last-interval:: 3.05
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T21:24:32.854Z
|
||||
card-last-reviewed:: 2022-11-14T20:24:32.854Z
|
||||
card-last-score:: 5
|
||||
- An **explicit join** is specified in the `FROM` clause where the tables to be joined are listed.
|
||||
- The keyword `INNER JOIN` is used for inner joins, and the **join condition** is listed using the keyword `ON`.
|
||||
- Syntax:
|
||||
- ```SQL
|
||||
SELECT [DISTINCT] <attribute list>
|
||||
FROM <table>
|
||||
[INNER / LEFT / RIGHT] JOIN <table>
|
||||
ON <join condition>
|
||||
WHERE <condition>
|
||||
```
|
||||
- What is an **implicit join**? #card
|
||||
id:: 6346a49e-2951-4bdb-ab74-6920aa664c41
|
||||
card-last-interval:: 0.98
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T19:05:12.117Z
|
||||
card-last-reviewed:: 2022-11-14T20:05:12.118Z
|
||||
card-last-score:: 3
|
||||
- An **implicit join** is specified on the `WHERE` clause without using the keyword `ON`.
|
||||
- It is referred to as a **join condition**.
|
||||
- All the tables must be listed in the `FROM` clause, separated by commas.
|
||||
- The **join condition** is contained in the `WHERE` clause.
|
||||
- If there are other conditions, the join condition is appended on with `AND`.
|
||||
- Other conditions can be specified in the `WHERE` clause as well as the join condition.
|
||||
- All implicit joins are **inner joins** - all rows from both tables will be returned whenever there is a match between the attributes in the join table.
|
||||
- Syntax:
|
||||
- ```sql
|
||||
SELECT [DISTINCT] <attribute list>
|
||||
FROM <table>, <table>
|
||||
WHERE <join condition> AND
|
||||
<condition>
|
||||
```
|
||||
- ## Self-Joins & Aliases
|
||||
- What is a **self-join**? #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T15:08:05.288Z
|
||||
card-last-reviewed:: 2022-11-14T20:08:05.289Z
|
||||
card-last-score:: 5
|
||||
- A **self-join** is a normal SQL join that joins a table to itself.
|
||||
- This is accomplished by using **aliases** to give each "instance" of the table a separate name using the keyword `AS`.
|
||||
- # Sub-Queries VS Joins
|
||||
- Can sub-queries & joins be used interchangeably? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-21T19:35:33.146Z
|
||||
card-last-reviewed:: 2022-11-17T19:35:33.147Z
|
||||
card-last-score:: 3
|
||||
- In some cases, you can replace a join with a sub-query.
|
||||
- But recall:
|
||||
- Joins are needed when values across multiple tables must be displayed.
|
||||
- Sub-queries are needed when an existing value from a table needs to be retrieved & used as part of the query solution.
|
||||
- Sub-queries are needed when an aggregate function needs to be performed & used as part of a query solution.
|
||||
- # Union Queries
|
||||
- The keyword `UNION` is used to combine the results of two or more queries or tables.
|
||||
- MySQL does not support minus or intersection (intersect) operators, but the same functionality can be built using join.
|
||||
- For union queries, tables must be **union compatible**.
|
||||
- What does it mean to be **union compatible**? #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T15:08:42.023Z
|
||||
card-last-reviewed:: 2022-11-14T20:08:42.023Z
|
||||
card-last-score:: 5
|
||||
- Two relations are **union compatible** if the schemas of two relations match.
|
||||
- i.e., there are the same number of attributes in each relation, and each pair of corresponding attributes have the same **domain**.
|
||||
-
|
||||
-
|
||||
39
year2/semester1/logseq-stuff/pages/MA284%3A Homework.md
Normal file
39
year2/semester1/logseq-stuff/pages/MA284%3A Homework.md
Normal file
@ -0,0 +1,39 @@
|
||||
- #[[MA284 - Discrete Mathematics]]
|
||||
-
|
||||
- # Assignment 1 2022-09-15
|
||||
- ### Problem 6
|
||||
- A survey of 1,000 employees in a company revealed that 289 like rock music, 325 like pop music, 136 like jazz, 135 like pop and rock music, 58 like jazz and rock, 39 like pop and jazz, and 20 employees like all three.
|
||||
- How many employees **do not like** jazz, pop, or rock music?
|
||||
- $$ |P \cup R \cup J| = |P| + |R| + |J| - |P \cap R| - |P \cap J| - |R \cap J| + |P \cap R \cap J| \newline= 289 + 325 + 136 - 135 - 58 - 39 + 20 = 538$$
|
||||
- $$|(P \cup R \cup J)^C| = |U| - |P \cup R \cup J| = 1,000 - 538 = 462$$
|
||||
- 1
|
||||
- How many employees like **pop but not jazz**?
|
||||
- 325 employees like pop, but only 39 like pop **and** jazz, so the number of employees who like pop but not jazz is $325 - 39 = 286$
|
||||
-
|
||||
- ### Problem 7
|
||||
collapsed:: true
|
||||
- How many 3-element subsets containing the letter A can be formed from the set $\{A,B,C,D,E,F,G\}$?
|
||||
- $$|\{A,B,C,D,E,F,G\}| = 7$$
|
||||
- Keyword is **subsets** - ^^order doesn't matter, elements can't be repeated.^^
|
||||
- ~~Must have A, so only have two choices; the first choice has 6 options, as A is gone, the second has 5, as both A and the previous letter are gone.~~
|
||||
- $$6\times 5 \times 1 = 30$$
|
||||
- answer isn't 30, 49
|
||||
-
|
||||
- Possibilities:
|
||||
- First Letter is A:
|
||||
- 1 choice for first letter - A
|
||||
- 6 choices for second letter
|
||||
- 5 choices for third letter
|
||||
- Total = 1 x 6 x 5 = 30
|
||||
- Second Letter is A:
|
||||
- 6 choices for first letter
|
||||
- 1 choice for second letter - A
|
||||
- 5 choices for third letter
|
||||
- Third Letter is A:
|
||||
- 6 choices for first letter
|
||||
- 5 choices for second letter
|
||||
- 1 choice for third letter - A
|
||||
- ### Problem 8
|
||||
- A DNA sequence can be represented as a string of the letters ACTG.
|
||||
- (a) How many DNA sequences are exactly 22 letters long?
|
||||
-
|
||||
42
year2/semester1/logseq-stuff/pages/Matrices.md
Normal file
42
year2/semester1/logseq-stuff/pages/Matrices.md
Normal file
@ -0,0 +1,42 @@
|
||||
- #[[MA284 - Discrete Mathematics]]
|
||||
- **Previous Topic:** [[Trees]]
|
||||
- **Next Topic:**
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- In a practical setting, a graph must be stored in some computer-readable format.
|
||||
- One of the most common is an **adjacency matrix**.
|
||||
-
|
||||
- # Adjacency Matrices
|
||||
- What is an **adjacency matrix**? #card
|
||||
- If the graph has $n$ vertices, labelled $\{1,2,\cdots, n\}$, then the **adjacency matrix** is an $m \times n$ **binary** matrix, $A$, with entries
|
||||
- $$a_{i,j} =
|
||||
\begin{cases}
|
||||
1 & \text{vertex } i \text{ is adjacent to } j\\
|
||||
0 & \text{otherwise.}
|
||||
\end{cases}$$
|
||||
- 
|
||||
- ## Properties of the Adjacency Matrix #card
|
||||
- The adjacency matrix of a graph is **symmetric**.
|
||||
- If $B = A^k$, then $b_{i,j}$ is the number of paths of length $k$ from vertex $i$ to vertex $j$.
|
||||
- We can work out if a graph is connected by looking at the eigenvalues of $A$.
|
||||
- If the graphs $G$ & $H$ are isomorphic, and have adjacency matrices $A_G$ & $A_H$, then there is a permutation matrix $P$, such that $PA_GP^{-1}=A_H$.
|
||||
- The adjacency matrix idea is easily extended to allow for multigraphs and pseudographs (graphs with loops).
|
||||
- For a multigraph, $a_{i,j}$ is the number of edges joining vertices $i$ & $j$.
|
||||
- For a pseudograph, $a_{i,i}$ means that there is an edge from the vertex $i$ to itself.
|
||||
- # Instance Matrices
|
||||
- Graphs can also be represented by an **Incidence Matrix**.
|
||||
- If the graph has $v$ vertices, and $e$ edges, then it is an $v \times e$ binary matrix.
|
||||
- The rows represent vertices.
|
||||
- The columns represent edges.
|
||||
- If the matrix is $B = (b_{i,j})$ then $b_{ik} = 1$ means that the vertex $i$ is incident to edge $j$.
|
||||
-
|
||||
- # Distance Matrices
|
||||
- What is the **eccentricity of a vertex**?
|
||||
- The **eccentricity of a vertex** is the greatest distance between that vertex & any other vertex in the graph.
|
||||
- What is the **radius of a graph**? #card
|
||||
- The **radius of a graph** is the minimum eccentricity of any vertex.
|
||||
- What is the **diameter of a graph**?
|
||||
- The **diameter of a graph** is the maximum eccentricity of any vertex.
|
||||
- This is also the maximum entry in the distance matrix.
|
||||
-
|
||||
-
|
||||
331
year2/semester1/logseq-stuff/pages/Memory Management.md
Normal file
331
year2/semester1/logseq-stuff/pages/Memory Management.md
Normal file
@ -0,0 +1,331 @@
|
||||
- #[[CT213 - Computer Systems & Organisation]]
|
||||
- **Previous Topic:** [[Process Synchronisation]]
|
||||
- **Next Topic:** [[Device Management]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Memory Management
|
||||
- In a multiprogramming system, the user part of memory is subdivided to accommodate multiple processes.
|
||||
- The task of subdivision is carried out by the OS and is known as **memory management**.
|
||||
- Memory needs to be allocated efficiently to pack as many processes into memory as possible.
|
||||
- ## Memory Management Requirements #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:15:43.843Z
|
||||
card-last-score:: 1
|
||||
- **Relocation -** dynamically loading the program into an arbitrary memory space, whose address limits are known only at execution time.
|
||||
- **Protection -** Each process should be protected against unwanted interference from other processes.
|
||||
- **Sharing -** Any protection mechanism should be flexible enough to allow several processes to access the same portion in main memory.
|
||||
- ## Memory Organisation #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:16:25.464Z
|
||||
card-last-score:: 1
|
||||
- ### Logical Organisation #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:16:46.268Z
|
||||
card-last-score:: 1
|
||||
- Most programs are organised in modules.
|
||||
- Some modules are un-modifiable (read only and/or execute only).
|
||||
- Others contain data that can be modified.
|
||||
- The OS must take care of the possibility of sharing modules across processes.
|
||||
- ### Physical Organisation #card
|
||||
card-last-interval:: 0.97
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T19:16:34.722Z
|
||||
card-last-reviewed:: 2022-11-14T20:16:34.722Z
|
||||
card-last-score:: 3
|
||||
- Memory is organised as at least a two-level hierarchy.
|
||||
- The OS should hide this fact and should perform the data movement between the main memory & secondary memory without the programmer's concern.
|
||||
- ## Memory Hierarchy Review
|
||||
- 
|
||||
- Tradeoff between size, speed, & cost.
|
||||
- What is a **register**? #card
|
||||
card-last-interval:: 3.45
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-18T06:17:44.069Z
|
||||
card-last-reviewed:: 2022-11-14T20:17:44.069Z
|
||||
card-last-score:: 5
|
||||
- Fastest memory element, but small storage.
|
||||
- Very expensive.
|
||||
- What is the **cache**? #card
|
||||
card-last-interval:: 0.97
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T19:15:19.026Z
|
||||
card-last-reviewed:: 2022-11-14T20:15:19.026Z
|
||||
card-last-score:: 3
|
||||
- Fast & small compared to main memory.
|
||||
- Acts as a buffer between the CPU & the main memory - it contains the most recent used memory locations (*address* & *contents* are recorded).
|
||||
- What is **main memory**? #card
|
||||
card-last-interval:: 3.32
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-18T03:13:53.945Z
|
||||
card-last-reviewed:: 2022-11-14T20:13:53.945Z
|
||||
card-last-score:: 5
|
||||
- **Main memory** is the RAM of the system.
|
||||
- The disk storage is the HDD or SSD.
|
||||
- ## Caching #card
|
||||
card-last-interval:: 2.97
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T19:15:15.143Z
|
||||
card-last-reviewed:: 2022-11-14T20:15:15.143Z
|
||||
card-last-score:: 5
|
||||
- Reading from the cache is faster than recomputing a result or reading from a slower data store.
|
||||
- Thus, the more requests that can be served from the cache, the faster the system performs.
|
||||
- When reading data from a lower memory, we also store a copy in the cache.
|
||||
- Further requests for that data can be served faster.
|
||||
- A **cache hit** occurs when the requested data can be found in a cache, while a **cache miss** occurs when it does not.
|
||||
- ### Cache Review
|
||||
- Typical computer applications access data with a high degree of locality of reference.
|
||||
- **Temporal Locality:** Data is requested that has been recently requested already.
|
||||
- **Spatial Locality:** Data is requested that is stored physically close to data that has already been requested.
|
||||
- When a system writes data to the cache, it must at some point write that data to the main memory as well as follow the **Write Policies**.
|
||||
- **Write-through:** Write is done synchronously both to the cache & to main memory.
|
||||
- **Write-back:** Initially, writing is done only to the cache. The write to amin memory is postponed until the modified content is about to be replaced by another cache block.
|
||||
-
|
||||
- # Process Address Space
|
||||
collapsed:: true
|
||||
- When accessing memory, a process is said to operate within an **address space**.
|
||||
- Data items are accessible within the range of addresses available to the process.
|
||||
- The number of bits allocated to specify the address is an **architectural decision**.
|
||||
- Now, most computers use 64 bits for addresses.
|
||||
- We say that such a system gives a **virtual address space** of 16 ExaBytes (16 billion gigabytes), although the amount of **physical** memory in such a system is most likely less than this.
|
||||
- ## Address Binding
|
||||
- An address used in an instruction can point **anywhere** in the virtual address space of the process.
|
||||
- It still must be bound to a physical memory address.
|
||||
- Programs are made of modules.
|
||||
- Compilers or assemblers do not know where the module will be loaded in the physical memory.
|
||||
- Virtual addresses must be translated to physical addresses.
|
||||
- Address translation can be **dynamic** or **static**.
|
||||
- ### Static Address Binding #card
|
||||
card-last-interval:: 0.97
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T19:17:04.679Z
|
||||
card-last-reviewed:: 2022-11-14T20:17:04.680Z
|
||||
card-last-score:: 3
|
||||
- The OS is responsible for managing the memory, so it will give the loader a **base address** where it should load the module.
|
||||
- The loader converts each virtual address in the module to absolute physical addresses by adding the base address.
|
||||
- Simple / easy to implement.
|
||||
- But, once loaded, the code or data of the program cannot be moved into another part of memory without a change in the static binding.
|
||||
- All the processes executing in such a system would share the same physical address space.
|
||||
- No protection from one another if addressing errors occur.
|
||||
- Even the OS code is exposed to addressing errors.
|
||||
- ### Dynamic Address Binding
|
||||
card-last-score:: 1
|
||||
card-repeats:: 1
|
||||
card-next-schedule:: 2022-10-26T23:00:00.000Z
|
||||
card-last-interval:: -1
|
||||
card-ease-factor:: 2.5
|
||||
card-last-reviewed:: 2022-10-26T11:42:36.358Z
|
||||
- What is **Dynamic Address Binding**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:13:55.843Z
|
||||
card-last-score:: 1
|
||||
- **Dynamic Address Binding** keeps loaded addresses **relative** to the start of a process.
|
||||
- #### Advantages of Dynamic Address Binding #card
|
||||
card-last-interval:: 0.98
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T14:53:28.457Z
|
||||
card-last-reviewed:: 2022-11-14T15:53:28.457Z
|
||||
card-last-score:: 3
|
||||
- A given program can run anywhere in the physical memory and can be moved around by the operating system.
|
||||
- All of the addresses that a program is using are relative to the program's own virtual address space, so the program is ^^unaware of the physical locations^^ at which it happens to have been placed.
|
||||
- It is possible to protect processes from each other and to protect the OS from application processes by a mechanism which we employ for isolating the addresses seen by the process.
|
||||
- #### Disadvantages of Dynamic Address Binding #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:21:35.955Z
|
||||
card-last-score:: 1
|
||||
- A mechanism is needed to bind the virtual addresses within the loaded instructions to physical addresses when the instructions are executed.
|
||||
- #### Hardware-Assisted Relocation & Protection #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:23:58.260Z
|
||||
card-last-score:: 1
|
||||
- Dynamic binding must be ^^implemented in hardware^^, as it introduces **translation** as part of every memory process.
|
||||
- If the basic requirement for modules is to be held **contiguously** in physical memory and contain addresses relative to their first location, the first location is called the **base** of the process.
|
||||
- Suppose that an instruction is fetched & decoded and contains an **address reference**:
|
||||
background-color:: green
|
||||
- This address reference is relative to the **base** of the process, so the value of the base must be added to it (*base + address reference*) in order to obtain the correct physical address to be sent to the memory controller.
|
||||
- The simplest form of dynamic binding hardware is a **base register** and a Memory Management Unit (MMU) to perform the translation.
|
||||
- The OS must load the base register as part of setting up the state of a process before passing control to it.
|
||||
- However, this approach does not provide any protection between processes - We cannot be sure that a process does not use an address that is not in its address space.
|
||||
- The solution to this problem is to ^^combine the relocation & protection functions in one unit^^ - By adding a second register (the **limit register**) that delimits the upper bound of the program in the physical memory.
|
||||
- 
|
||||
- # Segmentation
|
||||
collapsed:: true
|
||||
- ## Segmented Virtual Memory
|
||||
collapsed:: true
|
||||
- In practice, it is not very useful for a program to occupy a single **contiguous** range of physical addresses.
|
||||
- Such a scheme would prevent two processes from sharing the code, i.e., using this scheme, it is difficult to arrange two executions of the same program (two processes) to access different data while still being able to share code.
|
||||
- However, this can be achieved if the system has ^^**two** base registers^^ and ^^**two** limit registers^^, thus allowing two separate memory ranges or **segments** per process.
|
||||
- Two processes sharing a code segment but having private data segments.
|
||||
- 
|
||||
- The most significant bit of the virtual address is taken as a **segment identifier**, with `0` for a data segment and `1` for a code segment.
|
||||
- 
|
||||
- Within a single program, it is common to have separate areas for **code**, **stack**, & **heap**.
|
||||
- Language systems have conventions on how the virtual address space is arranged:
|
||||
- The code segment will not grow in size.
|
||||
- Heap (may be growing).
|
||||
- Stack at the top of the virtual memory, growing in the opposite direction to the Heap.
|
||||
- In order to realise relocation (& protection), three segments would be preferable.
|
||||
- The segment is the unit of protection & sharing - the more we have, the more flexible.
|
||||
- There are two ways to organise segmented addresses:
|
||||
- 1. Virtual Address Space is split into a **segment number** & a **byte number** within a segment.
|
||||
- The number of bits used for segment addressing is usually fixed by the CPU designer.
|
||||
- 2. The segment number is supplied separated from the offset portion of the address.
|
||||
- This is done in x86 processors.
|
||||
-
|
||||
- ## Segmented Address Translation
|
||||
collapsed:: true
|
||||
- For dynamic address translation in the OS, the hardware must keep a **segment table** for each process in which the location of each segment is recorded.
|
||||
- A process can have many segments, only those currently being used for instruction fetch & operand access need to be in main memory.
|
||||
- Other segments could be held on backing store until they are needed.
|
||||
- If an address is presented for a segment that is not present in main memory, then the address translation hardware generates an **addressing exception**.
|
||||
- This is handled by the OS, causing the segment to be fetched into main memory and the mechanism restarted.
|
||||
- 
|
||||
- ## Segmentation Summary #card
|
||||
card-last-interval:: 0.82
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-22T08:10:34.920Z
|
||||
card-last-reviewed:: 2022-11-21T13:10:34.920Z
|
||||
card-last-score:: 3
|
||||
- A process is divided into a **number of segments** that do not need to be equal in size.
|
||||
- When a process is brought into the main memory, all of its segments are usually brought into the main memory and a **process segment table** is set up.
|
||||
- ### Advantages
|
||||
- The virtual address space of a process is divided into logically distinct units which correspond to constituent parts of a process.
|
||||
- Segments are the natural units of access control.
|
||||
- Processes may have different access rights for different segments and sharing code / data with other processes.
|
||||
- ### Disadvantages
|
||||
- Inconvenient for OS to manage storage allocation for variable-sized segments.
|
||||
- After the system has been running for a while, the free memory available can be fragmented.
|
||||
- **External Fragmentation:** Sometimes, even though the total free memory might be far greater than the size of some segment that must be loaded, there is no single area large enough to load it
|
||||
-
|
||||
- # Paging
|
||||
- What is **paging**? Why use it? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-24T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-23T12:19:09.532Z
|
||||
card-last-score:: 1
|
||||
- The need to keep each loaded segment contiguous in the physical memory poses a significant disadvantage:
|
||||
- It leads to **fragmentation**.
|
||||
- It complicates the physical storage allocation problem.
|
||||
- Solution: **paging**, where blocks of a fixed size are used for memory allocation (so that if there is any free space, it is of the right size).
|
||||
- Memory is divided into page **frames**, and the user program is divided into **pages** of the same size.
|
||||
- ## Paged Virtual Memory #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:54:31.233Z
|
||||
card-last-score:: 1
|
||||
- Typical page size is small (1 to 4kB).
|
||||
- In paged systems, a process would require many pages.
|
||||
- The limited size of physical memory can cause problems. Therefore:
|
||||
- A portion of the disk storage could be used as extension to the main memory (backing store).
|
||||
- The pages of a process may be in the main memory and / or in this backing store.
|
||||
- The OS must manage two levels of storage and the transfer of pages between them.
|
||||
- The OS must keep a **page table** for each process to record information about the pages.
|
||||
- A **present bit** is needed to indicate whether the page is in the main memory or not.
|
||||
- A **modify bit** indicates if the page has been altered since last loaded into main memory.
|
||||
- If not modified, the page does not have to be written to the disk when swapped out.
|
||||
- ### Paged Virtual Memory Address Translation #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:15:43.967Z
|
||||
card-last-score:: 1
|
||||
- Translation of a virtual address (**page** + offset) into a physical address (**frame** + offset) using a page table.
|
||||
- The page table is stored in the main memory.
|
||||
- Each process maintains a pointer in one of its registers, to the page table.
|
||||
- The page number is used to index that table & lookup the corresponding frame number.
|
||||
- Combining the frame number with the offset from the virtual address gives the real physical address.
|
||||
- 
|
||||
- #### Two-Level Scheme to Organise Large Page Tables #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:15:49.987Z
|
||||
card-last-score:: 1
|
||||
- Processes could occupy huge amounts of virtual memory.
|
||||
- E.g., in a 32-bit addressing system with pages of size 4KB:
|
||||
- 12 bits for offset.
|
||||
- 20 bits for number of pages.
|
||||
- This means 2^{20} entries could be in each page table.
|
||||
- If each entry occupies 4 Bytes (32-bit addresses), then each page would take 4MB - this is unacceptable.
|
||||
- The solution is a **two-level scheme** to organise large page tables. #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:53:03.965Z
|
||||
card-last-score:: 1
|
||||
- **Root Page Table** with 2^{10} (1024 entries, 4 Bytes each) entries occupying 4KB of main memory that always remains in the main memory.
|
||||
- **User Page Tables** can reside in either the main memory or in disk.
|
||||
- The first 10 bits of a virtual address are used to find a PTE to the user page table.
|
||||
- The next 10 bits of virtual memory addresses are used to find the PTE for the page that is referenced by the virtual address.
|
||||
- Every virtual memory reference causes two physical memory accesses: one to fetch the appropriate User Page Table entry, the other to fetch the desired page.
|
||||
- To overcome this, most virtual memory schemas make use of a special **high-speed cache** for page entries.
|
||||
- ### Translation Lookaside Buffer #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:16:29.026Z
|
||||
card-last-score:: 1
|
||||
- The **Translation Lookaside Buffer (TLB)** is a kind of cache memory.
|
||||
- It contains the page entries that have been most recently used.
|
||||
- TLB is searched for each address reference.
|
||||
- The TLB is nearly always present in any processor that utilises paged or segmented virtual memory.
|
||||
- The virtual page number is extracted from the virtual address and a lookup is initiated.
|
||||
- If there are multiple processes, then special care must be taken so that a page from one process would not be confused with another's.
|
||||
- If a match is found, (TLB hit), then an access check is made, based on the information stored in the flags.
|
||||
- The physical page base, taken form TLB is appended to the offset from the virtual address to form the complete physical address.
|
||||
- The flags field will indicate the access rights and other information (i.e.m if a write is being attempted to a page that is read only etc.).
|
||||
- If an address reference is made to a page that is in in the main memory but not in the TLB, then the address translation fails (TLB miss) and new entry in the TLB needs to be created for that page.
|
||||
- If an address reference is made to a page that is not in the main memory, the address translation will fail again. No match will be found in the address table and the addressing hardware will raise an exception called **page fault**.
|
||||
- The OS will handle this exception.
|
||||
- ## Paging Summary #card
|
||||
card-last-interval:: 0.98
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T15:25:33.519Z
|
||||
card-last-reviewed:: 2022-11-14T16:25:33.519Z
|
||||
card-last-score:: 3
|
||||
- ### Advantages
|
||||
- By using fixed sized pages in virtual address space & fixed sized pages in physical address space, it addresses some of the problems with segmentation.
|
||||
- **External fragmentation** is no longer a problem (all frames in physical memory are the same size).
|
||||
- Transfers to/from disks can be performed at granularity of individual pages.
|
||||
- ### Disadvantages
|
||||
- The page size is a choice made by the CPU or OS designer.
|
||||
- It may not fit the size of program data structures and lead to internal fragmentation in which storage allocation request be rounded to an integral number of pages.
|
||||
- There may be no correspondence between **page protection settings** & **application data structures**.
|
||||
- If two processes are to share data structures, they may do so at the level of sharing entire pages.
|
||||
- Requiring a page table per process means it's likely that the OS will require **more storage** for its internal data structures.
|
||||
-
|
||||
-
|
||||
21
year2/semester1/logseq-stuff/pages/Message Authentication.md
Normal file
21
year2/semester1/logseq-stuff/pages/Message Authentication.md
Normal file
@ -0,0 +1,21 @@
|
||||
- #[[CT255 - Next Generation Technologies II]]
|
||||
- **Previous Topic:** [[Block Ciphers & Stream Ciphers]]
|
||||
- **Next Topic:**
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- There are four types of attacks in the context of communication across a network, which are addressed by message authentication:
|
||||
- Masquerade (insertion of messages into the network from a fraudulent source).
|
||||
- Content modification.
|
||||
- Sequence modification.
|
||||
- Timing modification (delete or repeat messages).
|
||||
- Message authentication is concerned with:
|
||||
- Protecting the integrity of a message.
|
||||
- Validating the identity of the originator of the message.
|
||||
- Validating sequencing & timeliness.
|
||||
- Non-repudiation of origin (dispute resolution).
|
||||
- # Hash Functions
|
||||
- A hash function is a variation of a MAC, which produces a fixed-size hash code ("fingerprint") based on a variably-sized input message.
|
||||
- A hash function is public and is not keyed, therefore the hash value must be encrypted.
|
||||
- Traditional CRCs are too weak and cannot be used.
|
||||
- 128-512 bit hash values are regarded as suitable.
|
||||
-
|
||||
52
year2/semester1/logseq-stuff/pages/More Java Code.md
Normal file
52
year2/semester1/logseq-stuff/pages/More Java Code.md
Normal file
@ -0,0 +1,52 @@
|
||||
- #[[CT2106 - Object-Oriented Programming]]
|
||||
- **Previous Topic:** [[First Java Code]]
|
||||
- **Next Topic:** [[Variables & Types]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Composition & Inheritance
|
||||
- ## Composition
|
||||
- What is **Composition**? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-09T18:41:43.657Z
|
||||
card-last-reviewed:: 2022-11-11T11:41:43.658Z
|
||||
card-last-score:: 5
|
||||
- **Composition** is a type of "has-a" relationship. One object is **composed** of another and relies upon its services for its own functionality.
|
||||
- It is one of the fundamental relationships between classes in OOP.
|
||||
- For example:
|
||||
- The class `RacingBike` **has-a** `Wheel` - **Composition**.
|
||||
- How do you represent **Composition** in OOP class diagrams? #card
|
||||
card-last-interval:: 31.36
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-12-16T04:00:44.435Z
|
||||
card-last-reviewed:: 2022-11-14T20:00:44.435Z
|
||||
card-last-score:: 5
|
||||
- In OOP class diagrams, a **diamond shape** indicates **composition** or a "has-a" relationship.
|
||||
- 
|
||||
- This class diagram tells us that a `Vehicle` object is composed of a single `Engine` object.
|
||||
- How do you realise **Composition** in Java? #card
|
||||
card-last-interval:: 9.28
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-11-23T22:28:13.350Z
|
||||
card-last-reviewed:: 2022-11-14T16:28:13.350Z
|
||||
card-last-score:: 3
|
||||
- To realise a "has-a" relationship in Java, you must ^^create a link between the **participant classes** using a **reference type variable**.^^
|
||||
- The reference declaration is in the **owner** class.
|
||||
-
|
||||
- # Inheritance
|
||||
- What is **Inheritance**? #card
|
||||
card-last-interval:: 21.53
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-12-06T08:00:59.616Z
|
||||
card-last-reviewed:: 2022-11-14T20:00:59.616Z
|
||||
card-last-score:: 5
|
||||
- **Inheritance** is a type of "is-a" relationship.
|
||||
- It is one of the fundamental relationships between classes in OOP.
|
||||
- For example:
|
||||
- A `RacingBike` **is-a** type of `Bicycle` - **Inheritance**.
|
||||
-
|
||||
-
|
||||
227
year2/semester1/logseq-stuff/pages/Normalisation.md
Normal file
227
year2/semester1/logseq-stuff/pages/Normalisation.md
Normal file
@ -0,0 +1,227 @@
|
||||
- #[[CT230 - Database Systems I]]
|
||||
- **Previous Topic:** [[Joins & Union Queries]]
|
||||
- **Next Topic:** [[Query Processing: Relational Algebra]]
|
||||
- **Relevant Slides:**  
|
||||
-
|
||||
- # Normalisation
|
||||
- What is **normalisation**? #card
|
||||
card-last-interval:: 0.95
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-18T17:36:23.333Z
|
||||
card-last-reviewed:: 2022-11-17T19:36:23.333Z
|
||||
card-last-score:: 3
|
||||
- **Normalisation** takes each table through a series of tests to "verify" whether or not it belongs to a certain **normal form**.
|
||||
- Normal forms to check:
|
||||
- 1^{st}, 2^{nd}, & 3^{rd} normal forms (**NF**).
|
||||
- Boyce-Codd normal form - strong 3NF.
|
||||
- 4^{th} & 5^{th} Normal Forms.
|
||||
- ### Normalisation Provides:
|
||||
- 1. A formal framework for analysing relation schemas based on **keys** & **functional dependencies** among attributes.
|
||||
2. A series of **tests** so that a database can be normalised to any degree (e.g., from 1NF to 5NF).
|
||||
- However, normalisation does not necessarily provide a good design if considered in isolation to everything else.
|
||||
- What are **normalisation rules**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-24T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-23T12:19:46.203Z
|
||||
card-last-score:: 1
|
||||
- **Normalisation** rules gives us a *formal measure* of why one grouping of attributes in a relation schema may be better than the other.
|
||||
- Why normalise? #card
|
||||
card-last-interval:: 0.95
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-22T11:06:25.159Z
|
||||
card-last-reviewed:: 2022-11-21T13:06:25.160Z
|
||||
card-last-score:: 3
|
||||
- 1. Redundancy will be reduced or eliminated, reducing storage space as a result.
|
||||
2. The task of maintaining data integrity is made easier.
|
||||
- However, with normalisation, tables are usually added to the schema and are linked with foreign keys, which causes queries to become more complex as the often require data from multiple tables (requiring joins or subqueries).
|
||||
- ## Normalised & Un-Normalised Databases
|
||||
- Both normalised & un-normalised databases have advantages & disadvantages.
|
||||
- If a data base is **normalised**:
|
||||
- No (or very little) redundancy.
|
||||
- No anomalies when inserting, deleting, or modifying data.
|
||||
- More tables.
|
||||
- More foreign & primary keys to link tables.
|
||||
- More complex queries.
|
||||
- ### Redundancy
|
||||
- What is **redundancy**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-18T20:19:53.452Z
|
||||
card-last-reviewed:: 2022-11-14T20:19:53.453Z
|
||||
card-last-score:: 5
|
||||
- **Redundancy** is the unnecessary duplication of data in a database.
|
||||
- Consequences of redundancy:
|
||||
- Space is wasted.
|
||||
- Data can become inconsistent due to potential problems with update, insert, & delete operations.
|
||||
- What is **duplication**? #card
|
||||
card-last-interval:: 2.97
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T19:17:11.015Z
|
||||
card-last-reviewed:: 2022-11-14T20:17:11.015Z
|
||||
card-last-score:: 5
|
||||
- Duplicated data can naturally be present in a database and is not necessarily redundant.
|
||||
- For example, an attribute can have two identical values.
|
||||
- In the company database `ESSN` in `works_on` may be duplicated across many projects.
|
||||
- Data is **duplicated** rather than **redundant** if information is lost when deleting data
|
||||
-
|
||||
- ## Alternatives to Normalisation #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:19:50.503Z
|
||||
card-last-score:: 1
|
||||
- The alternative to normalisation is to retain redundant data and maintain data integrity by means of code consistency checks.
|
||||
- In some applications, the number of insertions may be very small or non-existent and in such cases, the overhead of normalised tables is generally not required.
|
||||
- ## De-Normalisation
|
||||
- What is **de-normalisation**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-19T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-18T18:34:49.533Z
|
||||
card-last-score:: 1
|
||||
- **De-normalisation** is a process of making compromises to the normalised tables by ^^introducing intentional redundancy^^ for performance reasons (specifically, querying performance).
|
||||
- Typically, de-normalisation will improve query times at the expense of data updates (insert, delete, update).
|
||||
- # Functional Dependencies
|
||||
- What is **Functional Dependency**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-22T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-21T13:06:48.090Z
|
||||
card-last-score:: 1
|
||||
- If $A$ & $B$ are attributes of a relation $R$, then $B$ is **functionally dependent (FD)** on $A$ if each value of $A$ is associated with exactly one value of $B$.
|
||||
- i.e., values in $B$ are uniquely determined by values of $A$.
|
||||
- Functional Dependency is one of the main concepts associated with normalisation.
|
||||
- It describes the ^^relationship between attributes.^^
|
||||
- $A$ -> $B$:
|
||||
- FD from $A$ to $B$.
|
||||
- $B$ is FD on $A$.
|
||||
- 
|
||||
- $A$ -> $B$ does not necessarily imply $B$ -> $A$.
|
||||
- $A$ <-> $B$ denotes $A$ -> $B$ & $B$ -> $A$.
|
||||
- $A$ -> $\{B,C\}$ denotes $A$ -> $B$ & $A$ -> $C$.
|
||||
- $\{A,B\}$ -> $C$ denotes that it is the **combination** of $A$ & $B$ that uniquely determines $C$.
|
||||
- ### Note on FDs
|
||||
- A functional dependency is a property of a relation schema $R$ and cannot be inferred automatically. Instead, it must be defined explicitly by someone who knows the **semantics** of $R$.
|
||||
- You will either be explicitly given all FDs, or given enough information about the attributes & the domain to *reasonably* infer the FDs (perhaps having to make assumptions).
|
||||
- ## Types of FDs #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T20:19:30.192Z
|
||||
card-last-score:: 1
|
||||
- ### Full Functional Dependency
|
||||
- What is a **Full Functional Dependency**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T20:15:37.929Z
|
||||
card-last-score:: 1
|
||||
- A functional dependency $\{X, Y\}$ -> $Z$ is a **full functional dependency** if when some attribute (either $X$ or $Y$) is removed from the left-hand side, the dependency ^^does not hold.^^
|
||||
- There may be any number of attributes on the LHS.
|
||||
- ### Partial Functional Dependency
|
||||
- What is a **Partial Functional Dependency**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:15:25.672Z
|
||||
card-last-score:: 1
|
||||
- A functional dependency $\{X, Y\}$ -> $Z$ is a **partial functional dependency** if some attribute (either $X$ or $Y$) can be removed from the LHS and the dependency ^^still holds.^^
|
||||
- There may be any number of attributes on the LHS.
|
||||
- ### Transitive Functional Dependency
|
||||
- What is a **Transitive Functional Dependency**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-23T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-22T13:40:05.155Z
|
||||
card-last-score:: 1
|
||||
- A functional dependency $X$ -> $Y$ is a **transitive functional dependency** in the relation $R$ if there is a set of attributes $Z$ that is neither a candidate key nor a subset of any key of $R$, and both $X$ -> $Z$ & $Z$ -> $Y$ hold
|
||||
- What is a **Candidate Key (CK)**? #card
|
||||
card-last-interval:: 3.45
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-18T06:20:02.759Z
|
||||
card-last-reviewed:: 2022-11-14T20:20:02.759Z
|
||||
card-last-score:: 3
|
||||
- A **candidate key (CK)** is one or more attribute(s) in a relation with which you can determine all the attributes in the relation.
|
||||
- Every relation has one or more candidate keys.
|
||||
- We pick one such candidate key as the primary key of a relation.
|
||||
- # Inference Rules for FDs
|
||||
- Typically, the main obvious functional dependencies $F$ are specified for a schema.
|
||||
- However, many others can be inferred from $F$.
|
||||
- We call these the **closure** of $F$: $F^+$.
|
||||
- **1. Reflexive:** Trivially, an attribute, or a set of attributes, always determines itself.
|
||||
- **2. Augmentation:** If $X$ - $Y$, we can infer $XZ$ -> $YZ$.
|
||||
- **3. Transitive:** If $X$ -> $Y$ & $Y$ -> $Z$, we can infer $X$ -> $Z$.
|
||||
- **4. Decomposition:** If $X$ -> $YZ$, we can infer $X$ -> $Y$.
|
||||
- **5. Union (additive):** If $X$ -> $Y$ and $X$ -> $Z$, we can infer if $X$ -> $YZ$.
|
||||
- **6. Pseudotransitive:** If $X$ -> $Y$ and $WY$ -> $Z$, we can infer $WX$ -> $Z$.
|
||||
- Note: Rules 1,2, & 3 are collectively called **Armstrong's Axioms**.
|
||||
- # Normal Forms
|
||||
- ## First Normal Form (1NF) #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:12:58.023Z
|
||||
card-last-score:: 1
|
||||
- A table is in in **1NF** if the table ==does not have any repeating groups== (a group of attributes that occur a variable number of times in each record (non-atomic)).
|
||||
- To ensure first normal form, choose an appropriate primary key (if one is not already specified) and if required, split the table into two or more tables to remove repeating groups.
|
||||
- ## Second Normal Form (2NF) #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:15:09.806Z
|
||||
card-last-score:: 1
|
||||
- A relation in **2NF** must be in 1NF and be such that where there is a composite primary key, all non-key attributes must be dependent on the *entire* primary key.
|
||||
- If partial dependencies exist, create new relations to split the attributes such that the partial dependency no longer holds.
|
||||
- ## Third Normal Form (3NF) #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:15:39.277Z
|
||||
card-last-score:: 1
|
||||
- A relation is in **3NF** if it is in 3NF and there are no dependencies between attributes that are not primary keys.
|
||||
- That is, no transitive dependencies exist in the table.
|
||||
- ### Steps to Normalise to 3NF #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:17:36.919Z
|
||||
card-last-score:: 1
|
||||
- 1. Identify an appropriate **Primary Key** if not already given.
|
||||
- This puts the table into **1NF**.
|
||||
- 2. Draw a diagram of **Functional Dependencies** from the primary key.
|
||||
3. Identify if the dependencies are Full, Partial, or Transitive.
|
||||
4. Using the diagram of the functional dependencies from the previous steps:
|
||||
- 5. Normalise to **2NF** by ^^removing **partial dependencies**^^ - creating new tables as a result. <ins>Ensure that all new tables have Primary Keys.</ins>
|
||||
6. Normalise to **3NF** by ^^removing **transitive dependencies**^^ (if they exist), creating new tables as a result. <ins>Ensure that any new tables have Primary Keys and are in 2NF</ins>.
|
||||
7. Check that all resulting tables are themselves in 1NF, 2NF, and 3NF (in particular, make sure that they all have PKs of their own).
|
||||
- ## Boyce-Codd Normal Form (BCNF) #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-24T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-23T12:16:35.097Z
|
||||
card-last-score:: 1
|
||||
- Only in rare cases does a 3NF table not meet the requirements off **BCNF**.
|
||||
- These cases are when a table has more than one candidate key.
|
||||
- Depending on the functional dependencies, a 3NF table with two or more overlapping candidate keys may or may not be in BCNF.
|
||||
- If a table in 3NF **does not** have multiple overlapping candidate keys, then it is guaranteed to be in **BCNF**.
|
||||
-
|
||||
-
|
||||
27
year2/semester1/logseq-stuff/pages/OOP Modelling.md
Normal file
27
year2/semester1/logseq-stuff/pages/OOP Modelling.md
Normal file
@ -0,0 +1,27 @@
|
||||
- #[[CT2106 - Object-Oriented Programming]]
|
||||
- **Previous Topic:** [[Variables & Types]]
|
||||
- **Next Topic:** [[Introduction to Inheritance]]
|
||||
- **Relevant Slides:**   
|
||||
-
|
||||
- # Modelling the Problem
|
||||
- A major part of OOP is modelling the problem.
|
||||
- The goal is to identify the **principle objects** in the problem domain, which we model as classes, the **responsibility** of each of these objects, and the **collaborations** between objects.
|
||||
- The objective of OOP Modelling is to produce a simplified **class diagram**.
|
||||
- **Classes** represent real-world entities.
|
||||
- **Associations** represent collaborations between the entities.
|
||||
- **Attributes** represent the data held about these entities.
|
||||
- **Generalisation** can be used to simplify the structure of the model.
|
||||
- What are **nouns** in OOP?
|
||||
card-last-score:: 5
|
||||
card-repeats:: 4
|
||||
card-next-schedule:: 2022-12-15T02:37:38.303Z
|
||||
card-last-interval:: 33.64
|
||||
card-ease-factor:: 2.9
|
||||
card-last-reviewed:: 2022-11-11T11:37:38.304Z
|
||||
- **Nouns** are candidate objects in OOP.
|
||||
- # OOP Principles
|
||||
- Consider the following principles when assigning responsibilities:
|
||||
- An **Object** is responsible for its own data.
|
||||
- An Object is responsibility for communicating its state.
|
||||
- **Single Responsibility Principle:** Each **Class** should have a ^^single responsibility.^^
|
||||
- All its services should be aligned with that responsibility.
|
||||
@ -0,0 +1,539 @@
|
||||
- #[[CT213 - Computer Systems & Organisation]]
|
||||
- No previous topic.
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- ## Traditional Classes of Computer Systems
|
||||
collapsed:: true
|
||||
- What is a **Personal Computer (PC)**?
|
||||
card-last-score:: 5
|
||||
card-repeats:: 2
|
||||
card-next-schedule:: 2022-09-23T18:28:00.836Z
|
||||
card-last-interval:: 4
|
||||
card-ease-factor:: 2.7
|
||||
card-last-reviewed:: 2022-09-19T18:28:00.836Z
|
||||
- A **Personal Computer** is a computer designed for use by an individual, usually incorporating a graphics display, a keyboard, and a mouse.
|
||||
- What is a **Server**? #card
|
||||
card-last-interval:: 41.44
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-22T21:33:20.708Z
|
||||
card-last-reviewed:: 2022-11-11T11:33:20.709Z
|
||||
card-last-score:: 5
|
||||
- A **server** is a computer used for running larger programs for multiple users, often simultaneously, and typically accessed only via a network.
|
||||
- What is a **Supercomputer**?
|
||||
card-last-interval:: 11.2
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-10-14T15:37:52.646Z
|
||||
card-last-reviewed:: 2022-10-03T11:37:52.647Z
|
||||
card-last-score:: 5
|
||||
- A **supercomputer** is a member of a class of computers with the highest performance (and cost). They are configured as servers and typically cost tens to hundreds of millions of dollars.
|
||||
- What is an **Embedded Computer**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:45:01.338Z
|
||||
card-last-reviewed:: 2022-11-14T16:45:01.338Z
|
||||
card-last-score:: 5
|
||||
- An **embedded computer** is a computer inside another device, used for running one predetermined application or collection of software.
|
||||
- What are **Personal Mobile Devices**?
|
||||
card-last-interval:: 11.2
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-10-12T21:31:08.211Z
|
||||
card-last-reviewed:: 2022-10-01T17:31:08.211Z
|
||||
card-last-score:: 5
|
||||
- **Personal Mobile Devices** are small, wireless devices that connect to the internet.
|
||||
- They rely on batteries for power, and software is installed by downloading apps.
|
||||
- Conventional examples include smartphones and tablets.
|
||||
- What is **Cloud Computing**? #card
|
||||
card-last-interval:: 29.26
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T22:41:13.223Z
|
||||
card-last-reviewed:: 2022-11-14T16:41:13.223Z
|
||||
card-last-score:: 5
|
||||
- **Cloud Computing** refers to large collections of servers that provide services over the internet.
|
||||
- Some providers rent dynamically varying number of servers as a utility.
|
||||
- What is **Software as a Service**? #card
|
||||
card-last-interval:: 29.26
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T22:47:42.790Z
|
||||
card-last-reviewed:: 2022-11-14T16:47:42.790Z
|
||||
card-last-score:: 5
|
||||
- **Software as a Service** delivers software & data as a service over the internet, usually via a thing program, such as a browser.
|
||||
- Examples include web search & email.
|
||||
-
|
||||
- ## Computer Systems
|
||||
- {:height 410, :width 414}
|
||||
- What is **Application Software**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:45:07.567Z
|
||||
card-last-reviewed:: 2022-11-14T16:45:07.567Z
|
||||
card-last-score:: 5
|
||||
- **Application Software** consists of user-installed applications & programs.
|
||||
- Application Software provides services to the user that are commonly useful.
|
||||
- What is the purpose of the **Operating System**? #card
|
||||
card-last-interval:: 49.07
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.28
|
||||
card-next-schedule:: 2023-01-02T21:21:34.885Z
|
||||
card-last-reviewed:: 2022-11-14T20:21:34.886Z
|
||||
card-last-score:: 3
|
||||
- The **Operating System** interfaces between a user's program and the hardware, provides a variety of services, and performs supervisory functions.
|
||||
- What is the purpose of the **Hardware**?
|
||||
- The **Hardware** performs the tasks.
|
||||
-
|
||||
- ## Seven Great Ideas in Computer Organisation
|
||||
- ### 1. Use **Abstraction** to Simplify Design #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T10:59:55.160Z
|
||||
card-last-reviewed:: 2022-11-14T19:59:55.163Z
|
||||
card-last-score:: 5
|
||||
- A major productivity technique for hardware & software is to use **abstractions** to characterise the design at different levels of representation
|
||||
- Lower-level details are hidden to offer a simpler model at higher levels.
|
||||
- ### 2. Make the **Common Case** Fast #card
|
||||
card-last-interval:: 29.26
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T22:41:18.214Z
|
||||
card-last-reviewed:: 2022-11-14T16:41:18.214Z
|
||||
card-last-score:: 5
|
||||
- Making the **common case fast** will tend to enhance performance better than optimising the rare case.
|
||||
- The common case is often simpler than the rare case, and hence is usually easier to enhance.
|
||||
- ### 3. Performance via **Parallelism** #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-11-17T15:35:06.365Z
|
||||
card-last-reviewed:: 2022-10-20T08:35:06.365Z
|
||||
card-last-score:: 5
|
||||
- Involves speeding up performance by using designs that compute operations in **parallel**.
|
||||
- ### 4. Performance via **Pipelining** #card
|
||||
card-last-interval:: 27.13
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-12-11T19:29:57.240Z
|
||||
card-last-reviewed:: 2022-11-14T16:29:57.241Z
|
||||
card-last-score:: 3
|
||||
- **Performance via Pipelining** is a particular pattern of **parallelism** that is so prevalent in computer architecture that it merits its own name.
|
||||
- ### 5. Performance via **Prediction** #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-15T02:32:12.139Z
|
||||
card-last-reviewed:: 2022-11-11T11:32:12.139Z
|
||||
card-last-score:: 5
|
||||
- In some cases, it can be ^^faster on average to guess and start working^^ that to wait until you know for sure (assuming that the mechanism to recover from a misprediction is not too expensive, and your prediction is relatively accurate).
|
||||
- ### 6. Hierarchy of Memories #card
|
||||
card-last-interval:: 29.26
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T22:42:13.815Z
|
||||
card-last-reviewed:: 2022-11-14T16:42:13.816Z
|
||||
card-last-score:: 5
|
||||
- Computer Architects have found that they can address conflicting demands with a **hierarchy of memories**.
|
||||
- The ^^fastest, smallest, & most expensive memory per bit^^ is at the top of the hierarchy.
|
||||
- The ^^slowest, largest, & cheapest per bit^^ is at the bottom of the hierarchy.
|
||||
- ### 7. Dependability via **Redundancy** #card
|
||||
card-last-interval:: 29.26
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T22:42:16.723Z
|
||||
card-last-reviewed:: 2022-11-14T16:42:16.723Z
|
||||
card-last-score:: 5
|
||||
- Since any physical device can fail, we make systems **dependable** by including ^^redundant components^^ that can take over when a failure occurs *and* help detect failures.
|
||||
-
|
||||
- ## Hardware Organisation
|
||||
- What does basic computer organisation look like? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-11-22T23:24:24.522Z
|
||||
card-last-reviewed:: 2022-10-20T08:24:24.523Z
|
||||
card-last-score:: 5
|
||||
- 
|
||||
- What is an **integrated circuit**?
|
||||
card-last-interval:: 31.36
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-11-04T20:17:29.178Z
|
||||
card-last-reviewed:: 2022-10-04T12:17:29.178Z
|
||||
card-last-score:: 5
|
||||
collapsed:: true
|
||||
- An **integrated circuit**, also called a **chip**, is a device combining dozens to millions of transistors.
|
||||
- ### The CPU
|
||||
- What is a **CPU**? #card
|
||||
card-last-interval:: 29.26
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T22:47:19.225Z
|
||||
card-last-reviewed:: 2022-11-14T16:47:19.226Z
|
||||
card-last-score:: 5
|
||||
- The **Central Processing Unit (CPU)**, also called the **processor**, is the ^^active part of the computer^^, which contains the datapath & control, and which adds numbers, tests numbers, signals I/O devices to activate, and so on.
|
||||
- The CPU is ^^responsible for executing programs.^^
|
||||
- What are the steps that the CPU takes to process programs? #card
|
||||
card-last-interval:: 64.01
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.52
|
||||
card-next-schedule:: 2023-01-17T20:21:39.209Z
|
||||
card-last-reviewed:: 2022-11-14T20:21:39.209Z
|
||||
card-last-score:: 5
|
||||
- **1. Fetch:** Retrieve an instruction from ^^program memory.^^
|
||||
- **2. Decode:** Break down the instruction into parts that have significance to specific sections of the CPU.
|
||||
- **3. Execute:** Various portions of the CPU are connected to perform the desired operation.
|
||||
- **4. Write Back:** Simply "writes back" the results of the execute step ^^if necessary.^^
|
||||
- ### CPU Organisation
|
||||
- What does the **organisation** of the CPU look like? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 1.94
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:12:31.318Z
|
||||
card-last-score:: 1
|
||||
- Processors are made up of:
|
||||
- A **Control Unit**
|
||||
- **Execution Unit(s)**
|
||||
- A **Register File**
|
||||
- {:height 339, :width 418}
|
||||
-
|
||||
- #### Control Unit
|
||||
- What does the **Control Unit** do? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:48:27.996Z
|
||||
card-last-score:: 1
|
||||
- The **Control Unit** ^^controls the execution^^ of the instructions stored in main memory.
|
||||
- It ^^retrieves & executes^^ them.
|
||||
- What is the architecture of the control unit? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.08
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:18:27.653Z
|
||||
card-last-score:: 1
|
||||
- The control unit contains a **fetch unit**, a **decode unit**, and an **execute unit**.
|
||||
- It also contains two special registers:
|
||||
- **Program Counter (PC):** keeps the address of the next instruction
|
||||
- **Instruction Register (IR):** keeps the instruction being executed
|
||||
- {:height 266, :width 550}
|
||||
-
|
||||
- ### The Memory Subsystem
|
||||
collapsed:: true
|
||||
- How is the memory divided into storage locations? #card
|
||||
card-last-interval:: 29.26
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T22:41:41.185Z
|
||||
card-last-reviewed:: 2022-11-14T16:41:41.185Z
|
||||
card-last-score:: 5
|
||||
- Memory is divided into a set of storage location which can hold data.
|
||||
- Locations are numbered.
|
||||
- Addresses are used to tell the memory which location the processor wants to access.
|
||||
- What are the two hierarchies of memory? #card
|
||||
card-last-interval:: 10.97
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-25T15:41:01.018Z
|
||||
card-last-reviewed:: 2022-11-14T16:41:01.018Z
|
||||
card-last-score:: 5
|
||||
- **1. Nonvolatile / ROM (Read Only Memory):** Read only memory.
|
||||
- Used to store the BIOS and / or a *bootstrap* or *bootloader* program.
|
||||
- **2. Volatile / RAM (Random Access Memory):** Read / Write memory.
|
||||
- Also called **Primary Memory**.
|
||||
- Used to hold the programs, operating system, and data required by the computer.
|
||||
- #### Primary Memory
|
||||
- How is primary memory connected to the CPU? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-15T02:38:12.876Z
|
||||
card-last-reviewed:: 2022-11-11T11:38:12.876Z
|
||||
card-last-score:: 5
|
||||
- **Primary Memory** is directly connected to the Central Processing Unit of the computer.
|
||||
- It must be present for the CPU to function correctly.
|
||||
- What are the three types of Primary Storage? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.08
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:35:22.469Z
|
||||
card-last-score:: 1
|
||||
- **1. Processor Register:**
|
||||
- Contains information that the CPU needs to carry out the current instruction.
|
||||
- **2. Cache Memory:**
|
||||
- A special type of internal memory used by many CPUs to increase their **throughput**.
|
||||
- **3. Main Memory:**
|
||||
- Contains the programs that are currently being run and the data that the programs are operating on.
|
||||
- What is the **address width**? #card
|
||||
card-last-interval:: 47.41
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.28
|
||||
card-next-schedule:: 2023-01-07T22:09:51.569Z
|
||||
card-last-reviewed:: 2022-11-21T13:09:51.569Z
|
||||
card-last-score:: 3
|
||||
- The **address width** is the number of bits used to represent an address in memory.
|
||||
- The **width** limits the amount of memory that a computer can access.
|
||||
- Most computers use a **64 bit address**, which means that the maximum number of locations is 2^{64} \approx 16 billion gigabytes.
|
||||
- What operations does the memory subsystem support? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-12T23:44:58.031Z
|
||||
card-last-reviewed:: 2022-11-14T16:44:58.031Z
|
||||
card-last-score:: 3
|
||||
- The memory subsystem supports two operations:
|
||||
- **Load** (or read) + the address of the data location to be read.
|
||||
- **Store** (or write) + the address of the location & the data to be written.
|
||||
- How many bytes may the memory system read or write at a time? #card
|
||||
card-last-interval:: 29.26
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T22:41:30.763Z
|
||||
card-last-reviewed:: 2022-11-14T16:41:30.764Z
|
||||
card-last-score:: 5
|
||||
- Read & Write operations ^^operate at the width of the system's data bus^^, usually 32 bit or 64 bit.
|
||||
- How is a section of memory addressed? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:43:58.787Z
|
||||
card-last-score:: 1
|
||||
- The address ^^contains only the address of the lowest byte^^, and a number of bytes to be read is specified, e.g., 4 bytes.
|
||||
- #### Memory Alignment & Words of Data
|
||||
- When the computer's **word size** is 4 bytes, the data to be read should be at a memory address which is ^^some multiple of four.^^
|
||||
- When this is not the case, e.g., the data starts at address 14 instead of 16, then the computer has to read two or more 4 byte chunks and do some calculation before the requested data has been read, or it may generate ^^an alignment fault.^^
|
||||
- Even though the previous data structure end is at, for example, address 13, the next data structure should start at address 16. Two **padding bytes** are inserted between the two data structures at addresses 14 & 15 to align the next data structure at address 16.
|
||||
- ### The I/O Subsystem
|
||||
- What are **input devices**? #card
|
||||
collapsed:: true
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:38:20.415Z
|
||||
card-last-reviewed:: 2022-11-14T16:38:20.415Z
|
||||
card-last-score:: 5
|
||||
- Anything that feeds data into the computer.
|
||||
- What are **output devices**? #card
|
||||
collapsed:: true
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:38:27.684Z
|
||||
card-last-reviewed:: 2022-11-14T16:38:27.684Z
|
||||
card-last-score:: 5
|
||||
- Display / transmit information back to the user.
|
||||
- What does the **I/O Subsystem** contain? #card
|
||||
collapsed:: true
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:38:17.443Z
|
||||
card-last-reviewed:: 2022-11-14T16:38:17.443Z
|
||||
card-last-score:: 5
|
||||
- The **I/O Subsystem** contains the devices that the computer uses to communicate with the outside world and to store data.
|
||||
- How do I/O devices communicate with the processor? #card
|
||||
collapsed:: true
|
||||
card-last-interval:: 10.24
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-11-24T21:49:01.266Z
|
||||
card-last-reviewed:: 2022-11-14T16:49:01.266Z
|
||||
card-last-score:: 3
|
||||
- I/O devices usually communicate with the processor using the **I/O Bus**.
|
||||
- PCs use the **PCI Express (Peripheral Component Interconnect Express)** bus for their I/O bus.
|
||||
- The Operating System needs a **device driver** to access a given I/O device.
|
||||
- What is a **device driver**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:43:53.294Z
|
||||
card-last-reviewed:: 2022-11-14T16:43:53.295Z
|
||||
card-last-score:: 5
|
||||
- A **device driver** is a program that allows the OS to control an I/O device.
|
||||
- #### I/O Read / Write Operations
|
||||
- The I/O read & write operations are similar to the memory read & write operations.
|
||||
- How does the processor address I/O devices? #card
|
||||
card-last-interval:: 12.96
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 1.8
|
||||
card-next-schedule:: 2022-11-27T19:18:57.241Z
|
||||
card-last-reviewed:: 2022-11-14T20:18:57.241Z
|
||||
card-last-score:: 3
|
||||
- A processor may use:
|
||||
- **Memory-Mapped I/O:** when the address of the I/O device is in the **direct memory space**, and the ^^sequences to read/write data in the device are the same as the memory read/write sequences.^^
|
||||
- **Isolated I/O:** similar process to Memory-Mapped I/O, but the processor has a ^^second set of control signals to distinguish between a **memory access** and am **I/O access**.^^
|
||||
- What is **IO/M**? #card
|
||||
card-last-interval:: 19.01
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-03T20:02:23.177Z
|
||||
card-last-reviewed:: 2022-11-14T20:02:23.177Z
|
||||
card-last-score:: 3
|
||||
- **IO/M** is a **status signal** in **Isolated I/O** that denotes whether the read/write operation pertains to the memory or to the I/O subsystem.
|
||||
- When the **signal is low** (IO/M = 0), i.e., IO/M is `true`, it denotes **memory-related operations**.
|
||||
- When the **signal is high**, (IO/M = 1), i.e., IO/M is `false`, it denotes an **I/O operation**.
|
||||
-
|
||||
-
|
||||
-
|
||||
- ## Programs
|
||||
- What are programs? #card
|
||||
card-last-interval:: 23.43
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-12-08T02:39:39.879Z
|
||||
card-last-reviewed:: 2022-11-14T16:39:39.879Z
|
||||
card-last-score:: 3
|
||||
- Programs are ^^sequences of instructions^^ that tell the computer what to do.
|
||||
- To the computer, a program is made out of a ^^sequence of numbers that represent individual operations.^^
|
||||
- These operations are known as **machine instructions** or just **instructions**.
|
||||
- A set of instructions that a processor can execute is known as an **instruction set**.
|
||||
- ### Program Development Tools
|
||||
collapsed:: true
|
||||
- What is a **high-level programming language**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:43:16.217Z
|
||||
card-last-reviewed:: 2022-11-14T16:43:16.218Z
|
||||
card-last-score:: 5
|
||||
- A **high-level programming language** is a ^^portable language^^ such as C that is ^^composed of words & algebraic notation^^ that can be translated by a compiler into **assembly language**.
|
||||
- What is a **compiler**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:38:38.718Z
|
||||
card-last-reviewed:: 2022-11-14T16:38:38.719Z
|
||||
card-last-score:: 5
|
||||
- A **compiler** is a program that translates statements in a given high-level language into assembly language statements.
|
||||
- What is an **assembler**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:43:18.677Z
|
||||
card-last-reviewed:: 2022-11-14T16:43:18.677Z
|
||||
card-last-score:: 5
|
||||
- An **assembler** is a program that translates symbolic, assembly language versions of instructions into the ^^binary version.^^
|
||||
- What is **Assembly Language**? #card
|
||||
card-last-interval:: 108
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 3
|
||||
card-next-schedule:: 2023-03-02T20:22:13.316Z
|
||||
card-last-reviewed:: 2022-11-14T20:22:13.317Z
|
||||
card-last-score:: 5
|
||||
- **Assembly Language** is a ^^symbolic representation^^ of **machine instructions**.
|
||||
- What is **Machine Language**? #card
|
||||
card-last-interval:: 19.01
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-03T20:02:29.114Z
|
||||
card-last-reviewed:: 2022-11-14T20:02:29.114Z
|
||||
card-last-score:: 3
|
||||
- **Machine Language** is a ^^binary representation^^ of **machine instructions**.
|
||||
- What is an **instruction**? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-12T23:49:56.176Z
|
||||
card-last-reviewed:: 2022-11-14T16:49:56.176Z
|
||||
card-last-score:: 3
|
||||
- An **instruction** is a command that the computer hardware understands & obeys.
|
||||
-
|
||||
- ## Operating Systems
|
||||
- What is an **Operating System**? #card
|
||||
card-last-interval:: 9.68
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-11-24T08:36:28.473Z
|
||||
card-last-reviewed:: 2022-11-14T16:36:28.474Z
|
||||
card-last-score:: 5
|
||||
- Possible definition: a program that runs on the computer that ^^knows about all the hardware^^ and usually ^^runs in privileged mode^^, having ^^access to physical resources that user programs can't control^^, and has the ^^ability to start & stop user programs.^^
|
||||
- The OS is responsible for managing the physical resources of complex systems, such as PCs, workstations, mainframe computers, etc.
|
||||
- It is also responsible for ^^loading & executing programs^^ and ^^interfacing with the users.^^
|
||||
- Usually, there is no operating system for **small embedded systems**.
|
||||
- Computers designed for one specific task.
|
||||
-
|
||||
- ### Multiprogramming
|
||||
- What is **Multiprogramming**? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-11-17T15:33:42.952Z
|
||||
card-last-reviewed:: 2022-10-20T08:33:42.952Z
|
||||
card-last-score:: 5
|
||||
- **Multiprogramming** is a technique that allows the system to ^^present the illusion that multiple programs are running on the computer simultaneously.^^
|
||||
- Many multiprogrammed computers are **multiuser**.
|
||||
- They allow multiple users to be logged in at a time.
|
||||
- How is multiprogramming achieved? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-12T23:46:17.294Z
|
||||
card-last-reviewed:: 2022-11-14T16:46:17.294Z
|
||||
card-last-score:: 3
|
||||
- Multiprogramming is achieved by ^^switching rapidly between programs.^^
|
||||
- How does the processor decide which process to execute next? #card
|
||||
card-last-interval:: 23.43
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-12-08T02:44:23.286Z
|
||||
card-last-reviewed:: 2022-11-14T16:44:23.287Z
|
||||
card-last-score:: 5
|
||||
- **FCFS - First Come, First Served:** processes are moved to the CPU in the order in which they arrive.
|
||||
- **SJN - Shortest Job Next:** looks at all processes in the **ready state** and dispatches the one with the smallest service time.
|
||||
- **Round Robin:** distributes the processing time equitably among all ready processes.
|
||||
- ### Context Switching
|
||||
- What is a **Context Switch**? #card
|
||||
card-last-interval:: 64.01
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.52
|
||||
card-next-schedule:: 2023-01-24T13:09:58.962Z
|
||||
card-last-reviewed:: 2022-11-21T13:09:58.962Z
|
||||
card-last-score:: 5
|
||||
- When a program timeslice ends, the OS stops it, removes it, and gives another program control over the processor.
|
||||
- This is a **context switch**.
|
||||
- How does the OS go about a Context Switch? #card
|
||||
card-last-interval:: 15.05
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 1.94
|
||||
card-next-schedule:: 2022-11-29T17:40:02.859Z
|
||||
card-last-reviewed:: 2022-11-14T16:40:02.859Z
|
||||
card-last-score:: 3
|
||||
- copies the current program register file into memory
|
||||
- restores the contents of the next program's register file into the processor
|
||||
- starts executing the next program
|
||||
- From the program point of view, ^^no program can tell that a context switch has been performed.^^
|
||||
- ### Protection
|
||||
- Three rules of Protection in multiprogrammed computers: #card
|
||||
card-last-interval:: 29.21
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 1.94
|
||||
card-next-schedule:: 2022-12-17T00:35:54.999Z
|
||||
card-last-reviewed:: 2022-11-17T19:35:55.000Z
|
||||
card-last-score:: 3
|
||||
- 1. The result of any program running on the multiprogram computer ^^must be the same as if the program was the only program running on the computer.^^
|
||||
- 2. Programs ^^must not be able to access other programs' data^^ and must be confident that their data will not be modified by other programs (for security and privacy).
|
||||
- 3. Programs ^^must not interfere with other programs' use of I/O devices.^^
|
||||
- How is protection achieved? #card
|
||||
card-last-interval:: 15.05
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 1.94
|
||||
card-next-schedule:: 2022-11-29T21:01:17.902Z
|
||||
card-last-reviewed:: 2022-11-14T20:01:17.902Z
|
||||
card-last-score:: 3
|
||||
- Protection is achieved by the ^^operating system having full control over the resources of the system (processor, memory, and I/O devices)^^ through:
|
||||
- **Privileged Mode:** the operating system is the only one that can control the physical resources it executes in privileged mode.
|
||||
- User programs execute in **user mode**.
|
||||
- **Virtual Memory:** each program operates as if it were the only program on the computer, occupying a full set of the address space in its virtual space.
|
||||
- The OS is *translating* memory addresses that the program references into physical addresses used by the memory system.
|
||||
-
|
||||
-
|
||||
- **Next Topic:** [[Programming Models]]
|
||||
@ -0,0 +1,71 @@
|
||||
- #[[MA284 - Discrete Mathematics]]
|
||||
- **Previous Topic:** [[Counting]]
|
||||
- **Next Topic:** [[Binomial Coefficients]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- (Aside) **Notation for Complement:** $A^C$ for some set $A$.
|
||||
-
|
||||
- ## Counting with Sets
|
||||
- ### Additive Principle for Sets
|
||||
- #### Additive Principle in terms of "events"
|
||||
- If Event $A$ can occur $m$ ways, and Event $B$ can occur $n$ (disjoint / independent) ways, then event "$A$ *or* $B$" can occur in $m+n$ ways.
|
||||
- But, an "event" can just be expressed as ^^selecting an element of a set.^^
|
||||
- Saying "Event $A$ can occur $m$ ways" is ^^the same^^ as saying "$|A|=m$".
|
||||
- Saying "Event $B$ can occur $n$ ways is the same as saying "$|B|=n$".
|
||||
- If events $A$ and $B$ are **disjoint** / independent, that means that $|A \cap B| = 0$, or, equivalently , $A \cap B = \emptyset$.
|
||||
-
|
||||
- What is the **Additive Principle for Sets**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:02:08.655Z
|
||||
card-last-score:: 1
|
||||
- Given two sets $A$ and $B$ with $|A \cap B| = 0$, then:
|
||||
- $$|A \cup B| = |A| + |B|$$
|
||||
- ### Multiplicative Principle for Sets
|
||||
- What is the **Cartesian Product** of two sets? #card
|
||||
card-last-interval:: 11.04
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.76
|
||||
card-next-schedule:: 2022-11-25T16:36:56.463Z
|
||||
card-last-reviewed:: 2022-11-14T16:36:56.463Z
|
||||
card-last-score:: 5
|
||||
- The **Cartesian Product** of two sets, $A$ and $B$ is:
|
||||
- $$A \times B = \{(x,y) : x \in A \text{ and } y \in B \}$$
|
||||
- This is the set of pairs where the first term in each pair comes from $A$, **and** the second term in each pair comes from $B$.
|
||||
- #### Multiplicative Principle in terms of "events"
|
||||
- If event $A$ can occur $m$ ways, and each possibility allows for $B$ to occur in $n$ (disjoint) ways, then event "$A$ **and** $B$" can occur in $m \times n$ ways.
|
||||
- What is the **Multiplicative Principle for Sets**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T11:00:28.884Z
|
||||
card-last-reviewed:: 2022-11-14T20:00:28.884Z
|
||||
card-last-score:: 5
|
||||
- Given two sets, $A$ and $B$:
|
||||
- $$|A \times B| = |A| \cdot |B|$$
|
||||
- This extends to 3 or more sets in the obvious way.
|
||||
- ## The Principle of Inclusion & Exclusion (PIE)
|
||||
- What is the **Principle of Inclusion & Exclusion**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T11:01:03.942Z
|
||||
card-last-reviewed:: 2022-11-14T20:01:03.942Z
|
||||
card-last-score:: 5
|
||||
- For any two finite sets $A$ and $B$:
|
||||
- $$|A \cup B| = |A| + |B| - |A \cap B|$$
|
||||
- This also extends to larger numbers of sets, for example:
|
||||
- For any 3 finite sets $A$, $B$, and $C$:
|
||||
- $$|A \cup B \cup C| = |A| + |B| + |C| - |A \cap B| - |A \cap C| - |B \cap C| + |A \cap B \cap C |$$
|
||||
- ## Subsets & Power Sets
|
||||
- What is a **power set**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-11-27T12:19:42.366Z
|
||||
card-last-reviewed:: 2022-11-23T12:19:42.366Z
|
||||
card-last-score:: 5
|
||||
- The **power set** of a set $A$, denoted by $P(A)$, is the ^^set of all subsets^^ of $A$, ^^including the empty set^^ ($\emptyset$).
|
||||
-
|
||||
155
year2/semester1/logseq-stuff/pages/Probability.md
Normal file
155
year2/semester1/logseq-stuff/pages/Probability.md
Normal file
@ -0,0 +1,155 @@
|
||||
- #[[ST2001 - Statistics in Data Science I]]
|
||||
- **Previous Topic:** [[Sampling]]
|
||||
- **Next Topic:** [[Random Variables]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- Probability provides the *framework* for the study & application of statistics.
|
||||
- # What are Probabilities?
|
||||
- Take, for example, a 6-sided die about to be tossed for the first time.
|
||||
- **Classical:** 6 possible outcomes, by symmetry, each equally likely to occur,
|
||||
- **Frequentist:** Empirical evidence shows that similar dice thrown in the past have landed on each side about equally often.
|
||||
- **Subjective:** The degree of individual belief in occurrence of an event can be influenced by classical or frequentist arguments.
|
||||
- Subjective probabilities are also influenced by other reasons when symmetry arguments don't apply & repeated trials are not possible.
|
||||
-
|
||||
- # Probability
|
||||
- The probability of an event $A$ is the number of (equally likely & disjoint) outcomes in the event divided by the total number of (equally likely & disjoint) possible outcomes.
|
||||
- $$P(A) = \frac{\text{\# of outcomes in A}}{\text{\# of possible outcomes}}$$
|
||||
- $$(0 \leq P(A) \leq 1)$$
|
||||
- ## Sample Spaces
|
||||
- What is a **sample space**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:42:50.065Z
|
||||
card-last-score:: 1
|
||||
- The set of all possible outcomes of a random experiment is called the **sample space**, $S$.
|
||||
- $S$ is **discrete** if it consists of a finite or countably infinite set of outcomes.
|
||||
- $S$ is **continuous** if it contains an interval of real numbers.
|
||||
- $$P(S) = 1$$
|
||||
- ## Events
|
||||
- What is an **event**? #card
|
||||
card-last-interval:: 4.14
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-21T23:15:48.008Z
|
||||
card-last-reviewed:: 2022-11-17T20:15:48.008Z
|
||||
card-last-score:: 5
|
||||
- An **event** is a specific collection of sample points / possible outcomes.
|
||||
- An event is denoted by $E$ or by capital letters, $A$, $B$, etc.
|
||||
- What is a **SImple Event**? #card
|
||||
card-last-interval:: 3.57
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-22T07:34:13.841Z
|
||||
card-last-reviewed:: 2022-11-18T18:34:13.841Z
|
||||
card-last-score:: 5
|
||||
- A **Simple Event** is a collection of only **one** sample point / possible outcomes.
|
||||
- What is a **Compound Event**? #card
|
||||
card-last-interval:: 4.14
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-21T23:15:54.761Z
|
||||
card-last-reviewed:: 2022-11-17T20:15:54.762Z
|
||||
card-last-score:: 5
|
||||
- A **Compound Event** is a collection of **more than one** sample point / possible outcomes.
|
||||
- ## Permuatations
|
||||
- A **permutation** is an arrangement of objects.
|
||||
- It can also be an arrangement of $r$ objects chosen from $n$ distinct objects where replacement in the selection is not allowed.
|
||||
- The symbol, $P^n_r$ represents the number of permutations of $r$ objects selected from $n$ objects.
|
||||
- The calculation is given by the formula:
|
||||
- $$P^n_r = \frac{n!}{(n-r)!}$$
|
||||
- ## Joint Events (and / or)
|
||||
- Probabilities of **joint events** can often be determined from the probabilities of the individual events that comprise them.
|
||||
- Joint events are generated by applying basic set operations to individual events, specifically:
|
||||
- **Complement** of event $A$ is $\bar{A} =$ all outcomes *not* in $A$.
|
||||
- **Union** of events $A \cup B$; $A$ **or** $B$ or both.
|
||||
- **Intersection** of events $A$ **and** $B$ -> $A \cap B$.
|
||||
- **Disjoint** events cannot occur together -> $A \cap B = \empty$.
|
||||
-
|
||||
- ## Probability of a Union ($A$ **or** $B$) #card
|
||||
card-last-interval:: 21.53
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-12-06T08:01:39.281Z
|
||||
card-last-reviewed:: 2022-11-14T20:01:39.281Z
|
||||
card-last-score:: 3
|
||||
- For any two events $A$ and $B$, the probability of union is given by:
|
||||
- $$P(A \cup B) = P(A) + P(B) - P(A \cap B)$$
|
||||
- For two **disjoint** (also called **mutually exclusive**) events $A$ and $B$, the probability that one *or* the other occurs is the sum of the probabilities of the two events (provided that $A$ and $B$ are disjoint).
|
||||
- $$P(A \cup B) = P(A) + P(B)$$
|
||||
- If $P(A \cup B)$ is greater than 1, then you know you have made a mistake and that the events were not mutually exclusive -> there is an intersection.
|
||||
- ## Intersections ($A$ **and** $B$)
|
||||
card-last-interval:: 3.51
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-10-08T00:26:58.336Z
|
||||
card-last-reviewed:: 2022-10-04T12:26:58.337Z
|
||||
card-last-score:: 5
|
||||
- #### Multiplication Rule for Independent Events #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T11:07:08.232Z
|
||||
card-last-reviewed:: 2022-11-14T20:07:08.232Z
|
||||
card-last-score:: 5
|
||||
- For two **independent** events $A$ and $B$, the probability that *both* $A$ **and** $B$ occur is the product of the probabilities of the two events.
|
||||
- $$P(A \cap B) = P(A) \times P(B)$$
|
||||
- If two events are **independent**, that means that one event has no impact on the probability of occurrence of the other event.
|
||||
- ## Conditional Probability
|
||||
card-last-score:: 1
|
||||
card-repeats:: 1
|
||||
card-next-schedule:: 2022-10-04T23:00:00.000Z
|
||||
card-last-interval:: -1
|
||||
card-ease-factor:: 2.5
|
||||
card-last-reviewed:: 2022-10-04T12:31:44.517Z
|
||||
- What is **conditional probability**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:30:38.038Z
|
||||
card-last-score:: 1
|
||||
- $P(B | A)$ is the probability of event $B$ occurring, given that event $A$ has already occurred.
|
||||
- The **conditional probability** of $B$ given $A$, denoted by $P(B | A)$, is defined by: #card
|
||||
card-last-interval:: 0.98
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T19:08:28.312Z
|
||||
card-last-reviewed:: 2022-11-14T20:08:28.312Z
|
||||
card-last-score:: 3
|
||||
- $$P(B|A) = \frac{P(A \cap B)}{P(A)} \text{, provided } P(A) > 0$$
|
||||
- **Note:** $P(A)$ cannot equal 0, since we know that $A$ *has* occurred.
|
||||
- ### General Multiplication Rule for Dependent Events #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:33:46.273Z
|
||||
card-last-score:: 1
|
||||
- The conditional probability can be rewritten to further generalise the multiplication rule:
|
||||
- $$P(A \cap B) = P(A) \cdot P(B|A)$$
|
||||
- $$P(B \cap A) = P(B)B \cdot P(B|A)$$
|
||||
- $$\text{As } P(A \cap B) = P(B \cap A) \text{ implies}$$
|
||||
- $$P(A) \cdot P(B | A) = P(B) \cdot P(A |B)$$
|
||||
- These results mean that $P(A |B)$ can be calculated once we know $P(A)$, $P(B)$, and $P(B | A)$.
|
||||
- #### Bayes' Theorem #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-22T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-21T13:07:04.337Z
|
||||
card-last-score:: 1
|
||||
- **Bayes' Theorem** states that:
|
||||
- $$P(A | B) = \frac{P(B | A) \cdot P(A)}{P(B)} \text{ for } P(B)>0$$
|
||||
- ## Independence
|
||||
- Two events, $A$ and $B$ are independent, if and only if:
|
||||
- $$P(A \cap B) = P(A)\cdot P(B)$$
|
||||
- Therefore, to obtain the probability that two independent events will occur, we simply find the product of their individual probabilities.
|
||||
- Two events $A$ and $B$ are independent, if and only if:
|
||||
- $$P(B | A) = P(B) \text{ or } P(A|B) = P(A)$$
|
||||
- assuming the existence of the conditional probabilities.
|
||||
- Otherwise, $A$ and $B$ are **dependent**.
|
||||
- If in an experiment, the events $A$ and $B$ can both occur, then:
|
||||
- $$P(A \cap B) = P(A)P(B|A) \text{, provided } P(A) > 0$$
|
||||
-
|
||||
407
year2/semester1/logseq-stuff/pages/Process Management.md
Normal file
407
year2/semester1/logseq-stuff/pages/Process Management.md
Normal file
@ -0,0 +1,407 @@
|
||||
- #[[CT213 - Computer Systems & Organisation]]
|
||||
- **Previous Topic:** [[System Software & Operating Systems]]
|
||||
- **Next Topic:** [[CPU Management - Scheduling]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Programs & Processes
|
||||
- What is a **Program**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-11-26T13:37:45.329Z
|
||||
card-last-reviewed:: 2022-11-22T13:37:45.329Z
|
||||
card-last-score:: 3
|
||||
- A **Program** is a static entity made up of source program language statements that define process behaviour when executed on a set of data.
|
||||
- What is a **Process**? #card
|
||||
collapsed:: true
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:39:13.229Z
|
||||
card-last-score:: 1
|
||||
- A **Process** is a dynamic entity that executes a program on a particular set of data using resources allocated by the system.
|
||||
- Two or more processes could execute the same program, each using its own data & resources.
|
||||
- It is a ^^program in execution.^^
|
||||
- It is composed of:
|
||||
- Program.
|
||||
- Data.
|
||||
- **Process Control Block (PCB)**: contains the state of the process in execution.
|
||||
- ## Process Execution #card
|
||||
collapsed:: true
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:14:34.752Z
|
||||
card-last-score:: 1
|
||||
- In order to execute, a process needs an **Abstract Machine Environment** to manage its use of resources.
|
||||
- The **Process Control Block (PCB)** is required to map the environment state onto the physical machine state.
|
||||
- The OS keeps a **process descriptor** for each process.
|
||||
- 
|
||||
- ## Program Execution #card
|
||||
collapsed:: true
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-22T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-21T13:09:10.088Z
|
||||
card-last-score:: 1
|
||||
- Each execution of a program generates a process that is executed.
|
||||
- Inter-process relationships:
|
||||
- **Competition:** Processes are trying to get access to the same resources of the system, therefore a protection between processes is necessary.
|
||||
- **Cooperation:** Sometimes the processes need to communicate between themselves and exchange information - synchronisation is needed.
|
||||
- ## Process Manager #card
|
||||
card-last-score:: 1
|
||||
card-repeats:: 1
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-interval:: -1
|
||||
card-ease-factor:: 2.5
|
||||
card-last-reviewed:: 2022-11-17T20:18:15.885Z
|
||||
- What does the **Process Manager** do? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:13:51.555Z
|
||||
card-last-score:: 1
|
||||
- The **Process Manager** implements:
|
||||
- **CPU Sharing** (called *scheduling*): Allocate resources to processes in conformance with certain policies.
|
||||
- **Process Synchronisation** & **Inter-Process Communication**: Deadlock strategies & protection mechanisms.
|
||||
- 
|
||||
- ## Process - User Perspective
|
||||
- When processes are executed in a quasi-parallel fashion, the processes need to synchronise to each other for correct functionality - this is done with directives `wait`/`signal`.
|
||||
- `wait`- wait for a signal from a specific process.
|
||||
- `signal` - send a signal to a specific process.
|
||||
- ## Process - OS Perspective #card
|
||||
collapsed:: true
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-24T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-23T12:20:00.645Z
|
||||
card-last-score:: 1
|
||||
- The processor's principle function is to execute machine instruction residing in main memory.
|
||||
- These instructions are provided in the form of *programs*.
|
||||
- A processor may interleave the execution of a number of programs over time.
|
||||
- ### Program View
|
||||
- Its execution involves a sequence of instructions within that progam.
|
||||
- The behaviour of individual processes can be characterised by a sequence of instructions called the ***trace*** of the process.
|
||||
- ### Processor View
|
||||
- The processor executes instructions from main memory, as dictated by changing values in the Program Counter (PC) register.
|
||||
- The behaviour of the processor can be characterised by showing how the traces of various processes are **interleaved**.
|
||||
- ## State Process Models
|
||||
- ### Two-State Process Model #card
|
||||
card-last-interval:: 15.48
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.08
|
||||
card-next-schedule:: 2022-11-30T07:19:45.198Z
|
||||
card-last-reviewed:: 2022-11-14T20:19:45.199Z
|
||||
card-last-score:: 3
|
||||
- The process can be in one of two states: *running* or not *running*.
|
||||
- When the OS creates a new process, it enters into the *not running* state; after that, the process exists - it is known to the OS and waits for the opportunity to run.
|
||||
- From time to time, the currently running process will be interrupted and the dispatcher process will select a new process to run.
|
||||
- The new process will be moved to the *running* state and the former one to the *not running* state.
|
||||
- #### Two-State Model Queuing Discipline #card
|
||||
card-last-interval:: 1.01
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T20:13:25.916Z
|
||||
card-last-reviewed:: 2022-11-14T20:13:25.916Z
|
||||
card-last-score:: 3
|
||||
- Each process needs to be represented.
|
||||
- Information relating to each process, including current state & location in memory.
|
||||
- Waiting processes should be kept in some kind of queue.
|
||||
- List of pointers to processes blocks.
|
||||
- Linked list of data blocks, each block representing a process.
|
||||
- Dispatcher behaviour:
|
||||
- An interrupted process is transferred to the *waiting queue*.
|
||||
- If the process is completed or aborted, it is discarded.
|
||||
- The dispatcher selects a process from the queue to execute.
|
||||
- ### Five-State Process Model #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-18T16:27:46.160Z
|
||||
card-last-reviewed:: 2022-11-14T16:27:46.161Z
|
||||
card-last-score:: 3
|
||||
- **Running:** The process is currently being executed.
|
||||
- For single-processor systems, one single process can be in this state at a time.
|
||||
- **Ready:** The process is prepared to execute when given the turn.
|
||||
- **Blocked:** The process cannot execute until some event occurs.
|
||||
- Such as the completion of an I/O operation.
|
||||
- **New:** The process has been created, but has not yet been accepted in the pool of executable processes by the OS.
|
||||
- Typically, a new process has not yet been loaded into main memory.
|
||||
- **Exit:** The process has been released from the pool of executable processes by the OS.
|
||||
- Completed or due to some errors.
|
||||
- #### Five-State Model Process Transition Diagram
|
||||
- 
|
||||
- #### Five-State Model Queuing Discipline #card
|
||||
collapsed:: true
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T20:18:38.089Z
|
||||
card-last-score:: 1
|
||||
- There are two types of queues: the **ready queue** & the **blocked queue**.
|
||||
- When a process is admitted into the system, it is placed in the **ready** queue.
|
||||
- When a process is removed from the processor, it is either placed in the **ready** queue or the **blocked** queue, depending on the circumstances.
|
||||
- When an event occurs, all the processes waiting on that event are moved from the **blocked** queue into the **ready** queue.
|
||||
- 
|
||||
- There are multiple **blocked** queues - one per event.
|
||||
- When the event occurs, the entire list of processes is moved to the **ready** queue.
|
||||
- 
|
||||
- #### Suspended Processes #card
|
||||
card-last-interval:: 0.79
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T10:27:13.430Z
|
||||
card-last-reviewed:: 2022-11-14T16:27:13.430Z
|
||||
card-last-score:: 3
|
||||
- The processor is faster than I/O so all the processes could be waiting for I/O.
|
||||
- You can swap these processes to the disk to free up some memory.
|
||||
- The *blocked* state becomes the *suspended* state when swapped to the disk.
|
||||
- 
|
||||
- ## Process Creation #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-19T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-18T18:35:10.727Z
|
||||
card-last-score:: 1
|
||||
- Creation of new processes:
|
||||
- The OS builds the data structures that are used to manage the process.
|
||||
- The OS allocates space in main memory to the process.
|
||||
- Reasons for process creation:
|
||||
- New batch job.
|
||||
- Interactive logon.
|
||||
- Created by OS to provide a service.
|
||||
- i.e., process to control printing.
|
||||
- Spawned by existing process.
|
||||
- i.e., to exploit parallelism.
|
||||
- ## Process Termination
|
||||
card-last-score:: 1
|
||||
card-repeats:: 1
|
||||
card-next-schedule:: 2022-10-08T23:00:00.000Z
|
||||
card-last-interval:: -1
|
||||
card-ease-factor:: 2.6
|
||||
card-last-reviewed:: 2022-10-08T15:27:20.789Z
|
||||
- Reasons for **Process Termination**: #card
|
||||
card-last-interval:: 8.88
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-23T13:37:45.614Z
|
||||
card-last-reviewed:: 2022-11-14T16:37:45.615Z
|
||||
card-last-score:: 3
|
||||
- Process finished its execution (**natural completion**).
|
||||
- Total time limit exceeded.
|
||||
- Errors (memory unavailable, arithmetic error, protection error, invalid instruction, privileged instruction, I/O failure, etc.).
|
||||
- ## Process Management Services #card
|
||||
collapsed:: true
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:43:04.324Z
|
||||
card-last-score:: 1
|
||||
- `create(&process_id, attributes)`
|
||||
- Creates a new process with implicit or specified attributes.
|
||||
- `delete(process_id)`
|
||||
- Sometimes known as `destroy`, `terminate`, or `exit`.
|
||||
- Ends the process specified by `process_id`.
|
||||
- Whenever the process is terminated, all the files are closed, and all the allocated resources are released.
|
||||
- `abort(process_id)`
|
||||
- The same as `delete` but for *abnormal termination*.
|
||||
- Usually generates a "**post-mortem dump**" which contains the state of the process before the abnormal termination.
|
||||
- `suspend(process_id)`
|
||||
- Puts the specified process into a **suspended** state.
|
||||
- `resume(process_id)`
|
||||
- Moves the specified process from the *suspended* state to the *ready* state.
|
||||
- `delay(process_id, time)`
|
||||
- Suspends the specified process for a specified period of time.
|
||||
- After the delay time elapses, the process is moved to the ready state.
|
||||
- `get_attribtutes(process_id, &buffer_attributes)`
|
||||
- Used to find out the attributes for the given process.
|
||||
- `set_attributes(process_id, buffer_attributes)`
|
||||
- Used to set the attributes of the specified process.
|
||||
-
|
||||
- ## Process Description
|
||||
- ### OS Control Structures #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:26:10.635Z
|
||||
card-last-score:: 1
|
||||
- #### Memory Tables #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:26:25.598Z
|
||||
card-last-score:: 1
|
||||
collapsed:: true
|
||||
- **Memory Tables** are used to keep track of both main (real) and secondary (virtual) memory.
|
||||
collapsed:: true
|
||||
- Some of the main memory is reserved for use by the OS, the remainder is available to the processes.
|
||||
- Memory Tables contain:
|
||||
- The allocation of main memory to processes.
|
||||
- The allocation of secondary memory to processes.
|
||||
- Any *protection* attributes of blocks of main or virtual memory (such as which processes can access certain shared memory regions).
|
||||
- Any information needed to manage virtual memory.
|
||||
- #### I/O Tables #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-19T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-18T18:35:16.384Z
|
||||
card-last-score:: 1
|
||||
collapsed:: true
|
||||
- **I/O Tables** are used by the OS to manage the I/O devices.
|
||||
- At any given time, an I/O device may be available or assigned to a particular process.
|
||||
- If an I/O operation is in progress, the OS needs to know the status of the I/O operation and the location in main memory being used as the source or destination of the I/O transfer.
|
||||
- #### File Tables #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T19:40:13.935Z
|
||||
card-last-score:: 1
|
||||
collapsed:: true
|
||||
- **File Tables** provide information about:
|
||||
- The existence of files.
|
||||
- Their location in secondary memory.
|
||||
- Their current status.
|
||||
- Other attributes.
|
||||
- Much of this information is maintained & managed by the **File Manager**, in which case the process manager has little or no knowledge of files.
|
||||
- ### Process Tables
|
||||
card-last-score:: 1
|
||||
card-repeats:: 1
|
||||
card-next-schedule:: 2022-10-07T23:00:00.000Z
|
||||
card-last-interval:: -1
|
||||
card-ease-factor:: 2.5
|
||||
card-last-reviewed:: 2022-10-07T10:23:42.819Z
|
||||
collapsed:: true
|
||||
- What is the **Primary Process Table**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:26:29.312Z
|
||||
card-last-score:: 1
|
||||
- The **Primary Process Table** keeps one entry per each process in the operating system.
|
||||
- Each entry contains at least one pointer to a **process image**.
|
||||
- ### Process Image #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:26:31.530Z
|
||||
card-last-score:: 1
|
||||
collapsed:: true
|
||||
- The **Process Image** contains:
|
||||
- **Stack**
|
||||
collapsed:: true
|
||||
- Each process has one or more stack(s) associated with it.
|
||||
- A **stack** is used to store parameters & calling addresses for procedure & system calls.
|
||||
- **User Data**
|
||||
collapsed:: true
|
||||
- Program data that can be modified, etc.
|
||||
- **Process Control Block** #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-23T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-22T13:37:47.650Z
|
||||
card-last-score:: 1
|
||||
collapsed:: true
|
||||
- Data needed by the OS to control the process (attributes & information about the process).
|
||||
- Contains:
|
||||
- **Process Identification:** The data always includes a unique identifier for the process.
|
||||
- Numeric identifiers that may be stored with the **Process Control Block** include the **identifier of this process**, the **identifier of the process that created this process** (parent process), and the **User Identifier**.
|
||||
- **Processor State Information:** Defines the status of a process when it is suspended.
|
||||
- **User-Visible Registers**
|
||||
card-last-score:: 1
|
||||
card-repeats:: 1
|
||||
card-next-schedule:: 2022-10-08T23:00:00.000Z
|
||||
card-last-interval:: -1
|
||||
card-ease-factor:: 2.5
|
||||
card-last-reviewed:: 2022-10-08T15:22:36.520Z
|
||||
- What is a **User-Visible Register**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T09:49:41.863Z
|
||||
card-last-score:: 1
|
||||
- A **user-visible register** is one that may be referenced by means of the machine language that the processor executes.
|
||||
- **Control & Status Registers** #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-22T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-21T13:08:22.338Z
|
||||
card-last-score:: 1
|
||||
- These are a variety of processor registers that are employed to control the operation of the processor. These include:
|
||||
- **Program Counter:** Contains the address of the next instruction to be fetched.
|
||||
- **Condition Codes:** Result of the most recent arithmetic or logical operation.
|
||||
- **Status Information:** Includes interrupt enabled/disabled flags, execution mode.
|
||||
- **Stack Pointers**
|
||||
- Each process has one or more LIFO system stacks associated with it. A stack is used to store parameters & calling addresses for procedure & system calls.
|
||||
- The stack pointer points to the top of the stack.
|
||||
- **Processor Control Information:** Used by the OS to manage the process.
|
||||
- **Scheduling & State Information** #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:26:18.371Z
|
||||
card-last-score:: 1
|
||||
- This is information that is needed by the operating system to perform its scheduling function. Typical items of information include:
|
||||
- **Process State:** Defines the readiness of the process to be scheduled for execution (e.g., running, ready, waiting, halted).
|
||||
- **Priority:** One or more fields may be used to describe the scheduling priority of the process. In some systems, several values are required (e.g., default, current, highest-allowable).
|
||||
- **Scheduling-Related Information:** This will depend on the scheduling algorithm used. Examples are the amount of time that the process has been waiting an the amount of time that the process executed the last time it was running.
|
||||
- **Event:** Identity of the even the process is awaiting before it can be resumed.
|
||||
- **Data Structuring:** A process may be linked to another process in a queue or other structure.
|
||||
- **Inter-Process Communication:** Various flags, signals, & messages may be associated with communication between two independent processes.
|
||||
- **Process Privileges:** Processes are granted privileges in terms of the memory that may be accessed and the types of instruction that may be executed. In addition, privileges may apply to the use of system utilities & services.
|
||||
- **Memory Management:** This section may include pointers to segment and/or page tables that describe the virtual memory assigned to this process.
|
||||
- **Resource Ownership & Utilisation:** resources controlled by the processes may be indicated, such as opened files. A history of utilisation of the processor or other resources may also be included.
|
||||
- This information may be needed by the scheduler.
|
||||
-
|
||||
- ## Threads & Processes
|
||||
- A **process** is sometimes defined as a *heavyweight process*.
|
||||
- A **thread** is defined as a *lightweight process*.
|
||||
- Separate two ideas:
|
||||
- **Process:** Ownership of memory, files, other resources.
|
||||
- Execution of applications.
|
||||
- **Thread:** Unit of execution we use to dispatch.
|
||||
- Share the same address space hence we can read from and write to the same data structures.
|
||||
- What is **multithreading**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T20:15:51.123Z
|
||||
card-last-score:: 1
|
||||
- **Multithreading** allows multiple threads per process.
|
||||
- What is a **thread**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:35:09.592Z
|
||||
card-last-score:: 1
|
||||
- A **thread** is a unit of computation associated with a particular heavyweight process, using many of the associated process's resources.
|
||||
- It has a minimum of internal state & a minimum of allocated resources.
|
||||
- A group of threads are share the same resources.
|
||||
- e.g., files, memory space, etc.
|
||||
- The **process** is the execution environment for a family of threads.
|
||||
- A process with one thread is a **classic process**.
|
||||
- Each thread has an individual execution state.
|
||||
- Each thread has a control block, with a state (Running / Blocked / etc.), saved registers, an instruction pointer.
|
||||
- There is a separate stack & hardware state (PC, registers, PSW, etc.) per thread.
|
||||
- Shares memory & files with other threads that are in that process.
|
||||
- Faster to create a thread than a process.
|
||||
- 
|
||||
552
year2/semester1/logseq-stuff/pages/Process Synchronisation.md
Normal file
552
year2/semester1/logseq-stuff/pages/Process Synchronisation.md
Normal file
@ -0,0 +1,552 @@
|
||||
- #[[CT213 - Computer Systems & Organisation]]
|
||||
- **Previous Topic:** [[CPU Management - Scheduling]]
|
||||
- **Next Topic:** [[Memory Management]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Concurrent Programming
|
||||
collapsed:: true
|
||||
- What are **Concurrent Programs**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-21T09:47:57.127Z
|
||||
card-last-reviewed:: 2022-11-17T09:47:57.127Z
|
||||
card-last-score:: 3
|
||||
- **Concurrent Programs** are interleaving sets of sequential atomic instructions.
|
||||
- i.e., interacting sequential processes that run at the same time, on the same or different processors.
|
||||
- Processes are **interleaved** - at any time, each processor runs an instruction of the sequential processes.
|
||||
- ## Correctness
|
||||
- Generalisation: A program will be correct if its preconditions hold, as then its post conditions will also hold.
|
||||
- A concurrent program must be correct under ^^all possible **interleavings**.^^
|
||||
- If all the maths is done in registers, then the results will depend on **interleaving** (indeterminate calculation).
|
||||
- This dependency on unforeseen circumstances is known as a **Race Condition**.
|
||||
- What is a **Race Condition**? #card
|
||||
card-last-interval:: 0.88
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-18T06:49:18.142Z
|
||||
card-last-reviewed:: 2022-11-17T09:49:18.143Z
|
||||
card-last-score:: 3
|
||||
- A **Race Condition** occurs when a program output is dependent on the sequence or timing of code execution.
|
||||
- If multiple processes of execution enter a **critical section** at about the same time, both will attempt to update the shared data structure.
|
||||
- This will lead to surprising & undesirable results.
|
||||
- You must work to avoid this with concurrent code.
|
||||
- If we get different results every time we run some code, the result is **indeterminate**.
|
||||
- What is a **Critical Section**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T09:47:41.294Z
|
||||
card-last-score:: 1
|
||||
- A **critical section** is a part of a program where a shared resource is accessed.
|
||||
- A critical section must be protected in ways that avoid concurrent access.
|
||||
- What are **Deterministic Computations**? #card
|
||||
card-last-interval:: 0.98
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T19:07:48.411Z
|
||||
card-last-reviewed:: 2022-11-14T20:07:48.412Z
|
||||
card-last-score:: 3
|
||||
- **Deterministic Computations** have the same result each time.
|
||||
- We want deterministic concurrent code.
|
||||
- We can use synchronisation mechanisms.
|
||||
- ### Handling Race Conditions
|
||||
- We need a mechanism to control access to shared resources in concurrent code - **Synchronisation** is necessary for any shared data structure.
|
||||
- The idea is to focus on the critical sections of the code, i.e., sections that access shared resources.
|
||||
- We want critical sections to run with **mutual exclusion** - only one process should be able to execute that code at the same time.
|
||||
- #### Critical Section Properties #card
|
||||
card-last-interval:: 0.98
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-24T11:17:06.949Z
|
||||
card-last-reviewed:: 2022-11-23T12:17:06.950Z
|
||||
card-last-score:: 3
|
||||
- **Mutual Exclusion:** Only one process can access the critical section at a time.
|
||||
- **Guarantee of Progress:** Processes outside the critical section cannot stop another from entering it.
|
||||
- **Bounded Waiting:** A process waiting to enter the critical section will eventually enter.
|
||||
- Processes in the critical section will eventually leave.
|
||||
- **Performance:** The overhead of entering / exiting should be small.
|
||||
- **Fair:** Don't make certain processes wait much longer than others.
|
||||
- #### Atomicity #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T09:48:51.808Z
|
||||
card-last-score:: 1
|
||||
- Basic atomicity is provided by the hardware.
|
||||
- E.g., References & Assignments (i.e., read & write operations) are atomic in all CPUs.
|
||||
- However, higher-level constructs (i.e., any sequence of two or more CPU instructions) are not atomic in general.
|
||||
- Some languages (e.g., Java) have mechanisms to specify multiple instructions as atomic.
|
||||
- #### Conditional Synchronisation
|
||||
- Strategy: Person $A$ writes a rough draft and then Person $B$ edits it.
|
||||
- $A$ & $B$ cannot write at the same time (as they are working on different versions of the paper).
|
||||
- We must ensure that $B$ cannot start until $A$ is finished.
|
||||
- 
|
||||
-
|
||||
- # Mutual Exclusion Solutions
|
||||
collapsed:: true
|
||||
- ## Locks
|
||||
collapsed:: true
|
||||
- What is a **lock**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-16T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-15T18:42:37.491Z
|
||||
card-last-score:: 1
|
||||
- A **lock** is a token that you need to enter a critical section of code.
|
||||
- If a process wants to execute a critical section, it must have the lock.
|
||||
- Need to ask for lock.
|
||||
- Need to release lock.
|
||||
- There are no restrictions on executing other code.
|
||||
- 
|
||||
- ### Lock States & Operation #card
|
||||
card-last-interval:: 0.95
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-22T11:06:37.168Z
|
||||
card-last-reviewed:: 2022-11-21T13:06:37.168Z
|
||||
card-last-score:: 3
|
||||
- Locks have 2 states:
|
||||
- **Held:** Some process is in the critical section.
|
||||
- **Not Held:** No process is in the critical section.
|
||||
- Locks have 2 operations:
|
||||
- **Acquire:** Mark lock as held or wait until released. If not **held**, this is executed immediately.
|
||||
- If many processes call acquire, only one process can get the lock.
|
||||
- **Release:** Mark lock as **not held**.
|
||||
- ### Using Locks #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T15:07:42.144Z
|
||||
card-last-reviewed:: 2022-11-14T20:07:42.144Z
|
||||
card-last-score:: 5
|
||||
- Locks are declared like variables.
|
||||
- `Lock myLock;`
|
||||
- A program can use multiple locks.
|
||||
- To use a lock, surround the critical section as follows:
|
||||
- Call `acquire()` at the start of the critical section.
|
||||
id:: 63442116-a2c1-4c25-9309-e880471bb359
|
||||
- Call `release()` at the end of the critical section.
|
||||
- 
|
||||
- ### Lock Benefits #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T19:36:01.540Z
|
||||
card-last-score:: 1
|
||||
- Only one process can execute the critical section code at a time.
|
||||
- When a process is finished (& calls `release()`), another process can enter the critical section.
|
||||
- Achieves the requirements of **mutual exclusion** & **progress** for concurrent systems.
|
||||
- ### Lock Limitations #card
|
||||
card-last-interval:: 0.98
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T19:09:12.011Z
|
||||
card-last-reviewed:: 2022-11-14T20:09:12.011Z
|
||||
card-last-score:: 3
|
||||
- Acquiring a lock only blocks processes trying to acquire the *same* lock.
|
||||
- Process may acquire other locks.
|
||||
- ^^You must use the same lock for all critical sections accessing the same data (or resource).^^
|
||||
- ### Hardware-Based Lock
|
||||
- Processor has a special instruction called "test & set".
|
||||
- Allows atomic read **and** update.
|
||||
- ```c
|
||||
//c code for test and set behaviour
|
||||
bool test_and_set (bool *flag) {
|
||||
bool old = *flag;
|
||||
*flag = true;
|
||||
return old;
|
||||
}
|
||||
```
|
||||
- #### Hardware-Based Spinlock
|
||||
- ```c
|
||||
struct lock {
|
||||
bool held; //initially FALSE
|
||||
}
|
||||
void acquire(lock) {
|
||||
while(test_and_set(&lock->held))
|
||||
; //just wait
|
||||
return;
|
||||
}
|
||||
void release(lock) {
|
||||
lock->held = FALSE;
|
||||
}
|
||||
```
|
||||
- #### Drawbacks of Spinlocks #card
|
||||
card-last-interval:: 3.45
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-18T06:09:40.073Z
|
||||
card-last-reviewed:: 2022-11-14T20:09:40.073Z
|
||||
card-last-score:: 3
|
||||
- Spinlocks are a form of **busy waiting** -> they burn CPU time.
|
||||
- Once acquired, they are held until explicitly released.
|
||||
- Inefficient if the lock is held for long periods.
|
||||
- OS overhead of context switching.
|
||||
- If the Process Scheduler makes processes sleep while the lock is held, all other processes use their CPU time to spin while the process with the lock make no progress.
|
||||
- ### Do locks give us sufficient safety? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:24:13.793Z
|
||||
card-last-score:: 1
|
||||
- If you can demonstrate *any* cases in which the following properties do not hold, then the system is **not correct**.
|
||||
- 1. **Check Safety Properties:** These must *always* be true.
|
||||
- **Mutual Exclusion:** Two processes must not interleave certain sequences of instructions.
|
||||
- **Absence of Deadlock:** **Deadlock** is when a non-terminating system cannot respond to any signal.
|
||||
- 2. **Check Liveness Properties:** These must *eventually* be true.
|
||||
- **Absence of Starvation:** Information that is sent is delivered.
|
||||
- **Fairness:** Any contention must be resolved.
|
||||
- ### Lock Deadlock Scenario
|
||||
- 
|
||||
- ### Protocols to Avoid Deadlock #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:09:06.660Z
|
||||
card-last-score:: 1
|
||||
- Add a timer to the `lock.request()` method.
|
||||
- Cancel the job & attempt it another time if it takes too long.
|
||||
- Add a new `lock.check()` method to see if a lock is already held before requesting it.
|
||||
- You can do something else and come back & check again.
|
||||
- Avoid hold & wait protocol.
|
||||
- Never hold onto one resource when you need two.
|
||||
- ### Livelock by trying to avoid deadlock
|
||||
- 
|
||||
- ### Starvation
|
||||
- What is **Starvation**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:08:54.153Z
|
||||
card-last-score:: 1
|
||||
- **Starvation** is a more general case of livelock.
|
||||
- One or more processes do not get run as another process is locking the resource.
|
||||
- ### Locks / Critical Sections & Reliability
|
||||
- What if a process is interrupted, suspended, or crashes inside its critical section? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:17:34.955Z
|
||||
card-last-score:: 1
|
||||
- In the middle of the critical section, the system may be in an inconsistent state. The process is holding a lock, and if it dies, no other process waiting on that lock can proceed.
|
||||
- Developers must ensure that critical regions are very short and always terminate.
|
||||
- ### Beyond Locks
|
||||
- Locks only provide **mutual exclusion**.
|
||||
- They ensure that only one process is in the critical section at a time.
|
||||
- Locks are good for protecting our shared resource to prevent race conditions & avoid non-deterministic execution.
|
||||
- What about fairness, avoiding starvation, & livelock?
|
||||
- We need to be able to place an ordering on the scheduling of a process.
|
||||
-
|
||||
- ## Semaphores
|
||||
collapsed:: true
|
||||
- Example: We want to place an order on when processes execute.
|
||||
background-color:: green
|
||||
- Producer-Consumer:
|
||||
- Producer: Creates a resource (data).
|
||||
- Consumer: Uses a resource (data).
|
||||
- E.g.: `ps | grep "gcc" | wc`.
|
||||
- Don't want producers & consumers to operate in **lockstep** (i.e., atomicity).
|
||||
- Each command must wait for the previous output.
|
||||
- Implies lots of context switching (i.e., very expensive).
|
||||
- ^^**Solution:** Place a fixed-size buffer between producers & consumers.^^
|
||||
- ^^Synchronise access to buffer.^^
|
||||
- ^^Producer waits if the buffer is full; the consumer waits if the buffer is empty.^^
|
||||
- What is a **semaphore**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:50:12.454Z
|
||||
card-last-score:: 1
|
||||
- A **semaphore** is a higher-level synchronisation primitive.
|
||||
- Semaphores are a kind of **generalised lock**.
|
||||
- They are the main synchronisation primitive used in the original UNIX.
|
||||
- Semaphores are implemented with a **counter** that is manipulated atomically via 2 operations: **signal** & **wait**.
|
||||
- `wait(semaphore)`: AKA `down()` or `P()`.
|
||||
- **Decrement** counter.
|
||||
- If counter is zero, then block until semaphore is **signalled**.
|
||||
- `signal(semaphore)`: AKA `up()` or `V()`.
|
||||
- **Increment** counter.
|
||||
- Wake up one **waiter**, if any.
|
||||
- `sem_init(semaphore, counter)`:
|
||||
- Set initial counter value.
|
||||
- ### Semaphore PseudoCode #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:13:51.708Z
|
||||
card-last-score:: 1
|
||||
- `wait()` & `signal()` are **critical sections**.
|
||||
- Hence, they must be executed **atomically** with respect to each other.
|
||||
- Each semaphore has an associated queue of processes.
|
||||
- When `wait()` is called by a process:
|
||||
- If the semaphore is available -> the process continues.
|
||||
- If the semaphore is unavailable -> the process blocks, waits on queue.
|
||||
- `signal()` opens the semaphore.
|
||||
- If processes are waiting on a queue -> one process is unblocked.
|
||||
- If no processes are on the queue -> the signal is remembered for the next time `wait()` is called.
|
||||
- Note: Blocking processes is **not** spinning - they release the CPU to do other work.
|
||||
- ```pseudocode
|
||||
struct semaphore {
|
||||
int value;
|
||||
queue L[]; // list of processes
|
||||
}
|
||||
- wait (S) {
|
||||
if (s.value > 0) {
|
||||
s.value--;
|
||||
}
|
||||
else {
|
||||
add this process to s.L;
|
||||
block;
|
||||
}
|
||||
}
|
||||
- signal(S) {
|
||||
if (S.L != EMPTY) {
|
||||
remove a process P from S.L;
|
||||
wakeup(P);
|
||||
}
|
||||
else {
|
||||
s.value++;
|
||||
}
|
||||
}
|
||||
```
|
||||
- ### Semaphore Initialisation
|
||||
- If the semaphore is initialised to `1`: #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:52:48.262Z
|
||||
card-last-score:: 1
|
||||
- The first call to `wait` goes through -> The semaphore value goes from `1` to `0`.
|
||||
- The second call to `wait` **blocks** -> The semaphore value stays at `0`, the process goes on the queue.
|
||||
- If the first process calls `signal()` -> The semaphore value stays at `0` and wakes up the second process.
|
||||
- The semaphore acts like a **mutex lock**.
|
||||
- We can use semaphores to implement locks.
|
||||
- This is called a **binary semaphore**.
|
||||
- If the semaphore is initialised to `2`: #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:51:38.462Z
|
||||
card-last-score:: 1
|
||||
- The initial value of the semaphore = the number of processes that can be active at once.
|
||||
- `sem_init(sem, 2)`:
|
||||
- `value = 2, L = []`.
|
||||
- Consider multiple processes:
|
||||
- Process1: `wait(sem)`.
|
||||
- `value = 1, L = []` -> P1 executes.
|
||||
- Process2: `wait(sem)`.
|
||||
- `value = 0, L = []` -> P2 executes.
|
||||
- Process3: `wait(sem)`.
|
||||
- `value = 0, L = [P3]` -> P3 blocks.
|
||||
- ### Counting Semaphores #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:52:26.139Z
|
||||
card-last-score:: 1
|
||||
- Allocating a number of resources.
|
||||
- Shared buffers: each time you want to access a buffer, call `wait()`.
|
||||
- You are queued if there is no buffer available.
|
||||
- Counter is initialised to $N$ = number resources.
|
||||
- This is called a **counting semaphore**.
|
||||
- Useful for **conditional synchronisation**.
|
||||
- i.e., if one process is waiting for another process to finish a price of work before it continues.
|
||||
- ### Semaphores for Mutual Exclusion #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:15:56.292Z
|
||||
card-last-score:: 1
|
||||
- With semaphores, guaranteeing mutual exclusion for $N$ processes is trivial.
|
||||
- ```c
|
||||
semaphore mutex = 1;
|
||||
|
||||
void Process(int i) {
|
||||
while (1) {
|
||||
// Non-Critical Section Bit
|
||||
wait(mutex); // grab the mutual exclusion semaphore
|
||||
// Do the Critical Section Bit
|
||||
signal(mutex);
|
||||
}
|
||||
}
|
||||
|
||||
int main() {
|
||||
cobegin {
|
||||
Process(1); Process(2);
|
||||
}
|
||||
}
|
||||
```
|
||||
- ### Bounded Buffer Problem #card
|
||||
collapsed:: true
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-19T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-18T18:37:38.649Z
|
||||
card-last-score:: 1
|
||||
- Producer-Consumer Problem:
|
||||
- Buffer in memory - finite size of $N$ entries.
|
||||
- A producer process inserts an entry into the buffer.
|
||||
- A consumer process removes an entry from the buffer.
|
||||
- Processes are **concurrent** - we must use a synchronisation mechanism to control access to shared variables describing the buffer state.
|
||||
- #### Producer-Consumer Single Buffer
|
||||
- Simplest case:
|
||||
- Single producer process & single consumer process.
|
||||
- Single shared buffer between the producer & consumer.
|
||||
- Requirements:
|
||||
- Consumer must wait for Producer to fill the buffer.
|
||||
- Producer must wait for the Consumer to empty the buffer (if filled).
|
||||
- 
|
||||
-
|
||||
- ### Semaphores Can Be Hard to Use #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:24:06.193Z
|
||||
card-last-score:: 1
|
||||
- Complex patterns of resource usage.
|
||||
- Cannot capture relationships with semaphores alone.
|
||||
- Need extra state variables to record information.
|
||||
- Produce buggy code that is hard to write.
|
||||
- E.g., if one coder forgets to do `V()`/`signal()` after a critical section, the whole system can deadlock.
|
||||
- ## Monitors
|
||||
collapsed:: true
|
||||
- What are **Monitors**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-24T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-23T12:18:42.748Z
|
||||
card-last-score:: 1
|
||||
- **Monitors** are an extension of the monolithic monitor used in the OS to allocate memory.
|
||||
- A programming language construct that supports controlled access to shared data.
|
||||
- Synchronisation code added by compiler, enforced at runtime -> less work for programmer.
|
||||
- Monitors can keep track of **who** is allowed to access the shared data and **when** they can do it.
|
||||
- Monitors are a higher-level construct than semaphores.
|
||||
- Monitors encapsulate:
|
||||
- Shared data structures.
|
||||
- Procedures that operate on shared data.
|
||||
- Synchronisation between concurrent processes that invoke these procedures.
|
||||
-
|
||||
- # Detection & Protection of Deadlock
|
||||
- ## Requirements for Deadlock #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-19T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-18T18:37:21.446Z
|
||||
card-last-score:: 1
|
||||
- All four conditions must hold for deadlock to occur:
|
||||
- 1. **Mutex:** At least **one** resource must be **non-shareable**.
|
||||
2. **No Pre-Emption:** Resources cannot be **pre-empted** (no way to break priority or take a resource away once allocated).
|
||||
- Locks have this property.
|
||||
- 3. **Hold & Wait:** There is an existing process holding a resource and waiting for another resource.
|
||||
4. **Circular Wait:** There exists a set of process $P_1, P_2, \cdots, P_N$ such that $P_1$ is waiting for $P_2$, $P_2$ is waiting for $P_3$, ..., and $P_N$ is waiting for $P_1$.
|
||||
- If only three conditions hold then you can get **starvation**, but not deadlock.
|
||||
- ## Deadlocks Without Locks #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:13:42.597Z
|
||||
card-last-score:: 1
|
||||
- Deadlocks can occur for any resource or any time a process waits, e.g.:
|
||||
- Messages: waiting to receive a message before sending a message.
|
||||
- i.e., hold & wait.
|
||||
- Allocation: waiting to allocate resources before freeing another resource.
|
||||
- i.e., hold & wait.
|
||||
- ## Dealing with Deadlocks #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-24T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-23T12:16:50.624Z
|
||||
card-last-score:: 1
|
||||
- ### Strategy 1: Ignore #card
|
||||
collapsed:: true
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:14:57.281Z
|
||||
card-last-score:: 1
|
||||
- Ignore the fact that deadlocks may occur.
|
||||
- Write code, put nothing special in.
|
||||
- Sometimes you have to reboot the system.
|
||||
- May work for some unimportant or simple applications where deadlock does not occur often.
|
||||
- Quite a common approach.
|
||||
- ### Strategy 2: Reactive #card
|
||||
collapsed:: true
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-19T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-18T18:37:05.883Z
|
||||
card-last-score:: 1
|
||||
- Periodically check for evidence of a deadlock.
|
||||
- E.g., add timeouts to acquiring a lock, if you timeout, then it implies that deadlock has occurred and you must do something.
|
||||
- Recovery actions:
|
||||
- Blue screen of death & reboot computer.
|
||||
- Pick a process to terminate, e.g., a low-priority one.
|
||||
- Only works with some types of applications.
|
||||
- May corrupt data, so the process needs to do clean-up when terminated.
|
||||
- ### Strategy 3: Proactive #card
|
||||
collapsed:: true
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:18:36.908Z
|
||||
card-last-score:: 1
|
||||
- Prevent one of the four necessary conditions for deadlock.
|
||||
- No single approach is appropriate (or possible) for all circumstances.
|
||||
- Need techniques for each of the four conditions.
|
||||
- #### Solution 1: No Mutual Exclusion
|
||||
- Make resources shareable.
|
||||
- E.g., read-only files - no need for locks.
|
||||
- ### Solution 2: Adding Pre-Emption
|
||||
- Locks cannot be pre-empted but other pre-emptive methods are possible.
|
||||
- Strategy: pre-empt resources.
|
||||
- Example: If process $A$ is waiting for a resource held by process $B$, then take the resource from $B$ and give it to $A$.
|
||||
- Problems:
|
||||
- Only works for some resources
|
||||
- E.g., CPU & Memory (using virtual memory).
|
||||
- Not possible if a resource cannot be saved & restored.
|
||||
- Otherwise, taking away a lock causes issues.
|
||||
- Also, there is an overhead cost for "pre-empt" & "restore".
|
||||
- ### Solution 3: Avoid Hold & Wait
|
||||
- Only request a resource when you have none, i.e., release a resource before requesting another.
|
||||
- Never hold $x$ when want $y$.
|
||||
- Works in many cases, but you cannot maintain a relationship between $x$ & $y$.
|
||||
- Acquire all resources at once, e.g., use a single lock to protect all data.
|
||||
- Having fewer locks is called **lock coarsening**.
|
||||
- Problem: All processes accessing $A$ or $B$ cannot run at the same time, even if they don't access both variables.
|
||||
- #### Solution 4: Eliminate Circular Waits
|
||||
- Strategy: Impose an ordering on resources.
|
||||
- Processes must acquire the highest-ranked resource first.
|
||||
- Locks are always acquired in the same order.
|
||||
- We have eliminated the circular dependency, but we will need to lock a resource for a longer period.
|
||||
- Strategy: Define an ordering of **all** locks in your program.
|
||||
- Always acquire locks in that order.
|
||||
- Problem: Sometimes you do not know the order that the events will be used.
|
||||
- How do we know the global order?
|
||||
- Need extra code to find this out and then acquire them in the right order.
|
||||
- It could get worse.
|
||||
-
|
||||
-
|
||||
401
year2/semester1/logseq-stuff/pages/Programming Models.md
Normal file
401
year2/semester1/logseq-stuff/pages/Programming Models.md
Normal file
@ -0,0 +1,401 @@
|
||||
- #[[CT213 - Computer Systems & Organisation]]
|
||||
- **Previous Topic:** [[Overview of Computer Systems]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- What is a **Processor Programming Model**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:46:41.751Z
|
||||
card-last-score:: 1
|
||||
- A **Processor Programming Model** defines ^^how instructions access their operands and how instructions are described in the processor's assembly language.^^
|
||||
- Processors with different programming models can offer similar sets of operations but may require very different approaches to programming.
|
||||
-
|
||||
- ## Instructions
|
||||
- What is the **Instruction Cycle**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:51:49.011Z
|
||||
card-last-reviewed:: 2022-11-14T16:51:49.012Z
|
||||
card-last-score:: 5
|
||||
- The **Instruction Cycle** is the ^^procedure of processing an instruction^^ by the microprocessor.
|
||||
- **Fetch:** read the instructions from memory
|
||||
- **Decode:** Determine what is to be done
|
||||
- **Execute:** Perform the operation
|
||||
- Each of the functions fetch -> decode -> execute consist of a sequence of one or more operations inside the CPU (and interaction with the subsystems).
|
||||
- ### Types of Instructions
|
||||
- #### Data Transfer Instructions
|
||||
- What are **Data Transfer Instructions**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:51:37.887Z
|
||||
card-last-reviewed:: 2022-11-14T16:51:37.888Z
|
||||
card-last-score:: 5
|
||||
- Operations that ^^move data^^ from one place to another.
|
||||
- These instructions ^^don't modify^^ the data, they just copy it to the destination.
|
||||
- What operations can data transfer instructions do? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:33:36.553Z
|
||||
card-last-score:: 1
|
||||
- card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:40:37.309Z
|
||||
card-last-score:: 1
|
||||
1. **Load data** from memory into the microprocessor. #card
|
||||
- These instructions copy data from memory into microprocessor registers (i.e., LD).
|
||||
- card-last-interval:: 29.26
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T22:48:21.927Z
|
||||
card-last-reviewed:: 2022-11-14T16:48:21.927Z
|
||||
card-last-score:: 5
|
||||
2. **Store data** from the microprocessor into the memory. #card
|
||||
- Similar to load data, except that the data is copied in the opposite direction (i.e., ST).
|
||||
- Data is saved from internal microprocessor registers into the memory
|
||||
- card-last-interval:: 11.2
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-10-14T18:29:32.655Z
|
||||
card-last-reviewed:: 2022-10-03T14:29:32.655Z
|
||||
card-last-score:: 5
|
||||
3. **Move data** within the microprocessor.
|
||||
- These instructions move data from one microprocessor register to another (i.e., MOV)
|
||||
- card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-09-23T17:44:07.730Z
|
||||
card-last-reviewed:: 2022-09-19T17:44:07.731Z
|
||||
card-last-score:: 5
|
||||
4. **Input data** into the microprocessor.
|
||||
- A microprocessor may need to input data from the outside world.
|
||||
- These are the instructions that input data from the input device into the microprocessor.
|
||||
- card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-09-23T17:47:33.165Z
|
||||
card-last-reviewed:: 2022-09-19T17:47:33.165Z
|
||||
card-last-score:: 5
|
||||
5. **Output data** from the microprocessor.
|
||||
- The microprocessor copies data from one of its internal registers to an output device.
|
||||
- Example: the microprocessor may want to show the content of an internal register on a display (the key has been pressed) (i.e., IOWR).
|
||||
- #### Data Operation Instructions #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:47:54.439Z
|
||||
card-last-score:: 1
|
||||
- Instructions that *do* modify their data values.
|
||||
- They typically perform some operation (e.g., +, -, *) using one or two data values (operands) and store the result.
|
||||
- What operations can data operation instructions do? #card
|
||||
card-last-interval:: 30.47
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.76
|
||||
card-next-schedule:: 2022-12-15T07:20:59.244Z
|
||||
card-last-reviewed:: 2022-11-14T20:20:59.245Z
|
||||
card-last-score:: 5
|
||||
- **Arithmetic Instructions** #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-11-27T12:19:15.119Z
|
||||
card-last-reviewed:: 2022-11-23T12:19:15.119Z
|
||||
card-last-score:: 5
|
||||
- add, subtract, multiply, or divide
|
||||
- ADD, SUB, MUL, DIV
|
||||
- Instructions that increment or decrement one from a value
|
||||
- INC, DEC
|
||||
- Floating point instructions that operate on floating point values
|
||||
- FADD, FSUB, FMUL, FDIV
|
||||
- **Logic Instructions**
|
||||
card-last-interval:: 11.2
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-10-14T15:43:49.421Z
|
||||
card-last-reviewed:: 2022-10-03T11:43:49.421Z
|
||||
card-last-score:: 5
|
||||
- AND, OR, XOR, NOT, etc.
|
||||
- **Shift Instructions**
|
||||
card-last-interval:: 10.92
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-10-11T06:45:44.876Z
|
||||
card-last-reviewed:: 2022-09-30T08:45:44.877Z
|
||||
card-last-score:: 5
|
||||
- SR, SL, RR, RL, etc.
|
||||
- #### Program Control Instructions #card
|
||||
card-last-interval:: 31.36
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-12-16T00:29:50.214Z
|
||||
card-last-reviewed:: 2022-11-14T16:29:50.214Z
|
||||
card-last-score:: 5
|
||||
- **Jump** or **branch** instructions are used to ^^go to another part of the program^^; Jumps can be **absolute** or **conditional**.
|
||||
- e.g., if, then, else.
|
||||
- Instructions that can generate **interrupts**.
|
||||
- Software interrupts.
|
||||
- **Jump & branch instructions** (conditional or unconditional)
|
||||
card-last-interval:: 11.2
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-10-14T18:27:30.317Z
|
||||
card-last-reviewed:: 2022-10-03T14:27:30.317Z
|
||||
card-last-score:: 5
|
||||
- **JZ:** Jump if the zero flag is set.
|
||||
- **JNZ:** Jump if the zero flag is **not** set.
|
||||
- **JMP:** Unconditional jump - flags are ignored.
|
||||
- etc.
|
||||
- **Comparison Instructions** #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-09T18:30:16.818Z
|
||||
card-last-reviewed:: 2022-11-11T11:30:16.819Z
|
||||
card-last-score:: 5
|
||||
- TEST: logical BITWISE AND
|
||||
- **Calls & Returns** a / from a routine (conditional or unconditional) #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-11-18T20:24:48.750Z
|
||||
card-last-reviewed:: 2022-11-14T20:24:48.750Z
|
||||
card-last-score:: 5
|
||||
- **Call:** call a subroutine at a certain line.
|
||||
- **RET:** return from a subroutine.
|
||||
- **IRET:** interrupt & return.
|
||||
- **Software Interrupts** #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T10:59:57.740Z
|
||||
card-last-reviewed:: 2022-11-14T19:59:57.740Z
|
||||
card-last-score:: 5
|
||||
- Generated by devices outside of a microprocessor (not part of the instruction set).
|
||||
- INT
|
||||
- **Exceptions & Traps** #card
|
||||
card-last-interval:: 11.2
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-11-26T00:12:13.565Z
|
||||
card-last-reviewed:: 2022-11-14T20:12:13.565Z
|
||||
card-last-score:: 5
|
||||
- Triggered when valid instructions perform invalid operations.
|
||||
- e.g., dividing by zero.
|
||||
- **Halt Instructions** #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:49:58.118Z
|
||||
card-last-reviewed:: 2022-11-14T16:49:58.118Z
|
||||
card-last-score:: 5
|
||||
- Causes the processor to stop executions.
|
||||
- e.g., at the end of the program.
|
||||
- HALT
|
||||
-
|
||||
- ## Stack Architectures
|
||||
- ### The Stack
|
||||
- **Last In First Out (LIFO)** data structure.
|
||||
- Consists of **locations**, each of which can hold a **word of data**.
|
||||
- It can be used to explicitly **save / restore** data.
|
||||
- What operations does the stack support? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T11:00:04.531Z
|
||||
card-last-reviewed:: 2022-11-14T20:00:04.532Z
|
||||
card-last-score:: 5
|
||||
- The stack supports ^^two operations.^^
|
||||
- **PUSH:** takes one argument and places the value of the argument at the top of the stack.
|
||||
- **POP:** removes one element from the stack, saving it into a predefined register of the processor.
|
||||
- The stack is ^^used implicitly by procedure call instructions.^^
|
||||
- (if available in the data set).
|
||||
- When new data is added to the stack, it is placed at the top of the stack, and all of the contents of the stack are pushed down one location.
|
||||
- ### Implementing Stacks
|
||||
- What are the two ways to implement a stack? #card
|
||||
card-last-interval:: 41.44
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-20T22:45:42.001Z
|
||||
card-last-reviewed:: 2022-11-09T12:45:42.002Z
|
||||
card-last-score:: 3
|
||||
- card-last-interval:: 7.76
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 1.94
|
||||
card-next-schedule:: 2022-11-22T10:43:10.114Z
|
||||
card-last-reviewed:: 2022-11-14T16:43:10.114Z
|
||||
card-last-score:: 3
|
||||
1. **Dedicated Hardware Stack** #card
|
||||
- Has a ^^hardware limitation^^ (limited number of locations).
|
||||
- Very fast.
|
||||
- card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-12T23:52:10.829Z
|
||||
card-last-reviewed:: 2022-11-14T16:52:10.829Z
|
||||
card-last-score:: 3
|
||||
2. **Memory Implemented Stack** #card
|
||||
- Limited by the ^^physical memory of the system.^^
|
||||
- Slow compared with hardware stacks, since extra memory addressing has to take place for each stack operation.
|
||||
- {:height 405, :width 638}
|
||||
- Every **push operation** will ^^increment the top of the **stack pointer**^^ with the word size of the machine.
|
||||
- Every **pop operation** will ^^decrement the top of the stack pointer^^ (with the word size of the machine).
|
||||
- **Stack overflows** can occur in both stack implementations
|
||||
- What is a **stack overflow**? #card
|
||||
card-last-interval:: 97.56
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2023-02-20T09:22:00.580Z
|
||||
card-last-reviewed:: 2022-11-14T20:22:00.581Z
|
||||
card-last-score:: 5
|
||||
- A **stack overflow** occurs when the amount of data in the stack exceeds the amount of space allocated to the stack (or the hardware limit of the stack).
|
||||
- ### Instructions in Stack-Based Architecture #card
|
||||
card-last-interval:: 33.96
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.04
|
||||
card-next-schedule:: 2022-12-18T19:21:47.052Z
|
||||
card-last-reviewed:: 2022-11-14T20:21:47.052Z
|
||||
card-last-score:: 5
|
||||
- Instructions in a stack-base architecture get their operands from the stack and write their results to the stack.
|
||||
- The advantage of this is that ^^program code takes little memory - there is no need to specify the address of the operands or registers.^^
|
||||
- PUSH is one exception, because it needs the operand to be specified (either as a constant or as an address).
|
||||
- ### Programs in a Stack-Based Architecture
|
||||
- Writing programs for stack-based architecture is not easy.
|
||||
- Stack-based architectures are better suited for **postfix** notation rather than **infix** notation.
|
||||
- What is **infix notation**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:51:56.638Z
|
||||
card-last-reviewed:: 2022-11-14T16:51:56.639Z
|
||||
card-last-score:: 5
|
||||
- **Infix notation** is the traditional way of representing mathematical expressions, with ^^operations placed **between** the operands.^^
|
||||
- e.g., a + b
|
||||
- What is **postfix notation**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:50:12.717Z
|
||||
card-last-reviewed:: 2022-11-14T16:50:12.718Z
|
||||
card-last-score:: 5
|
||||
- In **postfix notation**, ^^the operation is placed **after** the operands.^^
|
||||
- e.g., a b +
|
||||
- Stack-based architectures are better suited for **postfix notation**.
|
||||
- Once an expression has been converted into postfix notation, implementing it in programs is easy.
|
||||
- ### Using Stacks to Implement Procedure Calls
|
||||
- Programs need a way to **pass inputs to the procedures** that they call and to receive outputs back from them.
|
||||
- Procedures need to be able to **allocate space in memory for local variables** without overriding any data used by their calling program.
|
||||
- It is impossible to determine which registers may be used safely by the procedure (especially if the procedure is located in a library).
|
||||
- So, a mechanism to **save / restore registers** of the calling program has to be in place.
|
||||
- Procedures need a way to figure out where they were called from.
|
||||
- So, the execution can **return to the calling program** where the procedure completes (they need to restore the program counter).
|
||||
- How are procedure calls implemented in Stacks? #card
|
||||
card-last-interval:: 19.01
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-03T20:06:14.181Z
|
||||
card-last-reviewed:: 2022-11-14T20:06:14.181Z
|
||||
card-last-score:: 3
|
||||
- 
|
||||
- When a procedure is called,^^a block of memory in the stack called a **stack frame** is allocated.^^
|
||||
- The top of the **stack pointer** is incremented by the number of locations in the stack frame.
|
||||
- When a procedure finishes, it jumps to the **return address** of the stack and the execution of the calling program resumes.
|
||||
- How are nested procedure calls implemented in the stack? #card
|
||||
card-last-interval:: 47.41
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.28
|
||||
card-next-schedule:: 2023-01-01T05:23:12.594Z
|
||||
card-last-reviewed:: 2022-11-14T20:23:12.594Z
|
||||
card-last-score:: 5
|
||||
- 
|
||||
- main program calls function f(),
|
||||
- function f() calls function g(),
|
||||
- function g() calls function h()
|
||||
- ## General-Purpose Register Architectures
|
||||
- ### General-Purpose Register File
|
||||
- In GPR Architectures, instructions read their operands and write their results to a **random access register file**.
|
||||
- The general-purpose register file allows the ^^access of **any** register in **any** order^^ by specifying the number (register ID) of the register.
|
||||
- What is the main difference between a GPR & a stack? #card
|
||||
card-last-interval:: 23.43
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-12-08T02:44:31.512Z
|
||||
card-last-reviewed:: 2022-11-14T16:44:31.512Z
|
||||
card-last-score:: 5
|
||||
- The main difference between a GPR and a stack is that repeatedly reading a register will produce the same result and **will not** modify the state of the register file.
|
||||
- Popping an item from a LIFO structure (stack) **will** modify the contents of the stack,
|
||||
- Many GPR architectures assign special values to some registers in the register file to make programming easier.
|
||||
- e.g., sometimes, register 0 is hardwired with value 0 to generate this most common constant.
|
||||
- ### Instructions in GPR Architecture
|
||||
- What do GPR instructions need to specify? #card
|
||||
card-last-interval:: 41.44
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-30T04:36:58.493Z
|
||||
card-last-reviewed:: 2022-11-18T18:36:58.494Z
|
||||
card-last-score:: 3
|
||||
- GPR instructions need to specify:
|
||||
- **the register** that holds their **input operands**
|
||||
- the register that will hole the **result**
|
||||
- What is the most common GPR instruction format? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:01:45.936Z
|
||||
card-last-score:: 1
|
||||
- The most common GPR instruction format is the **three operands instruction format**.
|
||||
- e.g., "ADD r1, r2, r3" instructs the processor to read the contents of r2 and r3, add them together, and write the results in r1.
|
||||
- Instructions that only have one or two inputs are also present in GPR architecture.
|
||||
- Which architecture allows **caching**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:38:25.742Z
|
||||
card-last-reviewed:: 2022-11-14T16:38:25.742Z
|
||||
card-last-score:: 5
|
||||
- In GPR Architecture, ^^programs can choose which values should be stored in the register file at any given time^^, allowing them to **cache** the most accessed data.
|
||||
- In stack-based architectures, once the data has been used, it's gone.
|
||||
- From this point of view, ^^GPR architectures have **better performance**^^, at the expense of needing **more storage space** for the program.
|
||||
- larger instructions are needed to encode the addresses of the operands.
|
||||
- #### Simple GPR Instruction Set
|
||||
- 
|
||||
-
|
||||
- ### Programs in a GPR Architecure #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-15T16:48:41.651Z
|
||||
card-last-reviewed:: 2022-11-17T09:48:41.652Z
|
||||
card-last-score:: 5
|
||||
- Programming a GPR architecture processor is **less structured** than programming a stack-based architecture processor.
|
||||
- There are **fewer restrictions on the order** in which operations can be executed.
|
||||
- In stack-based architectures, instructions must execute in the order that would leave the operands for the next instructions on the top of the stack.
|
||||
- In GPR, any order that places the operands for the next instruction in the register file before the instruction executes is valid.
|
||||
- Operations that access different registers can be **reordered** without making the program invalid.
|
||||
-
|
||||
- ## Stack-Bases vs GPR Architectures
|
||||
- Stack-based architectures are still attractive for certain embedded systems.
|
||||
- GPR architectures are used by modern computers.
|
||||
- ## Stack-Based Architectures #card
|
||||
card-last-interval:: 24.2
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-12-11T13:48:46.669Z
|
||||
card-last-reviewed:: 2022-11-17T09:48:46.669Z
|
||||
card-last-score:: 3
|
||||
- Instructions take **fewer bits** to encode.
|
||||
- **Reduced amount of memory** taken up by programs.
|
||||
- Manages the **use of registers automatically** (no need for programmer intervention).
|
||||
- The instruction set **does not change** if the size of the register file has changed.
|
||||
- ## GPR Architectures
|
||||
- With the evolution of technology, the amount of space taken up by a program is less important.
|
||||
- Compilers for GPR architecture achieve **better performance** with a given number of general-purpose registers than those on stack-based architectures with the same number of registers.
|
||||
- The compiler can choose which values to keep (**cache**) in the register file at any time.
|
||||
@ -0,0 +1,232 @@
|
||||
- #[[CT230 - Database Systems I]]
|
||||
- **Previous Topic:** [[Query Processing: Relational Algebra]]
|
||||
- **Next Topic:** [[File Organsiation]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Trees
|
||||
- What is a **tree**? #card
|
||||
card-last-interval:: 14.2
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-12-05T17:09:17.855Z
|
||||
card-last-reviewed:: 2022-11-21T13:09:17.855Z
|
||||
card-last-score:: 5
|
||||
- A **tree** is a collection of data arranged as a finite set of elements called **nodes**, such that the tree is empty or the tree contains a distinguished node, called the **root node**, and all other nodes are arranged in subtrees such that each node has a parent node.
|
||||
- Nodes typically contain *data* and some pointers to other nodes.
|
||||
- Nodes may be: #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:15:58.945Z
|
||||
card-last-score:: 1
|
||||
- **Root:** No node points to it.
|
||||
- **Inner:** Has parent & child nodes.
|
||||
- **Leaves:** Has no child nodes.
|
||||
- What is a **binary tree**? #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T11:23:05.626Z
|
||||
card-last-reviewed:: 2022-11-14T16:23:05.627Z
|
||||
card-last-score:: 5
|
||||
- Tree data structures (a grouping of data) are used frequently in computing allowing data to be stored in a non-linear (non-list) way.
|
||||
- They are often called **binary trees** where each node can have at most two child nodes.
|
||||
- ## SQL -> Relational Algebra
|
||||
- How to translate SQL to Relational Algebra? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-24T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-23T12:19:36.426Z
|
||||
card-last-score:: 1
|
||||
- `SELECT` *attributes* corresponds to $\pi$.
|
||||
- `JOIN`s correspond to relational algebra **joins** $\Join$ with ==any join conditions specified as part of the join.==
|
||||
- Any condition in a `WHERE` clause corresponds to a **sigma** $\sigma$ relational algebra operator with associated conditions.
|
||||
- In addition, we have rules for aggregate functions (`SUM`, `AVG`, `COUNT`, etc.), `GROUP BY` & `HAVING`, and subqueries.
|
||||
- ## Query Tree
|
||||
- What is a **query tree**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:51:22.389Z
|
||||
card-last-score:: 1
|
||||
- A **query tree** is a binary tree that corresponds to a relational algebra expression where:
|
||||
- (**Input**) Tables are the leaf nodes.
|
||||
- Relational algebra operators are at internal nodes.
|
||||
- (**Output / Result**) The root of the tree returns the result (often with one final relational algebra operator).
|
||||
- The sequence of operations is directed from ^^leaves to root^^ and from ^^left to right^^.
|
||||
- i.e., the bottom-most, left-most side of the tree is executed first.
|
||||
- ### Materialisation Evaluation #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:24:42.937Z
|
||||
card-last-score:: 1
|
||||
- One approach to executing a query represented by a query tree is **Materialisation Evaluation**.
|
||||
- Traverse the tree from bottom to top, left to right. At each stage:
|
||||
- 1. Execute internal node operation whenever data for its child nodes are available.
|
||||
2. Replace the internal node operation (and all child nodes) by the table resulting from executing the operation.
|
||||
- **Note:** The results of operations are saved as temporary tables and are used as inputs to other operators.
|
||||
- ### How to Draw a Query Tree #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-19T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-18T18:35:40.054Z
|
||||
card-last-score:: 1
|
||||
- We must remember the order of execution - from bottom to top, completing each level, and then left to right. Therefore:
|
||||
- The first operations - **fetching tables** - should be at the leaves of the tree.
|
||||
- The last operator - often $\pi$ or aggregate functions - should be at the root of the tree.
|
||||
- Joins must be applied to tables (two at a time) and should be at internal nodes.
|
||||
- Any other operators should be at one or more internal nodes.
|
||||
- **Important:** When joining or multiplying more than two tables, operators can only be applied to two operands at a time.
|
||||
- 
|
||||
- ### Annotating Tree
|
||||
- Each relational algebra operation can be evaluated using one of several different algorithms and Seach relational algebra expression can be evaluated in many ways.
|
||||
- What is an **evaluation plan**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:52:56.044Z
|
||||
card-last-score:: 1
|
||||
- An **evaluation plan** is an annotated expression / query tree specifying the execution strategy for a query.
|
||||
- ### Issues to Consider with Query Trees #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-24T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-23T12:19:19.197Z
|
||||
card-last-score:: 1
|
||||
- Size of temporary tables.
|
||||
- Algorithms used for execution plan.
|
||||
- # Optimisation
|
||||
- Different query trees for a given query can have different *costs*.
|
||||
- Different evaluation plans for a given query can have different costs.
|
||||
- **Optimisation techniques** attempt to choose the best among a number of potential query trees.
|
||||
- ## Cost Estimates
|
||||
- How to calculate cost estimates? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-22T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-21T13:05:07.723Z
|
||||
card-last-score:: 1
|
||||
- Cost factors include CPU speed, disk access time, network communication time, etc.
|
||||
- Disk access is typically the predominant cost and can be measured by the number of blocks read / number of blocks written per query.
|
||||
- What is the main cost estimate used? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:52:39.027Z
|
||||
card-last-score:: 1
|
||||
- The main cost estimate used is the number of block transfers where each block contains a number of records.
|
||||
- The number of blocks transferred from disk depends on:
|
||||
- The size of the buffer in main memory - having more memory reduces the need for more disk accesses.
|
||||
- Indexing structures used (primary, secondary, etc.).
|
||||
- Whether or not all blocks of a file must be transferred.
|
||||
- e.g., if a search can be done on the primary key of the index file or on the secondary index, then only retrieve blocks that satisfy the search condition.
|
||||
- As in typical in Computing, often we use **worst case estimates**, knowing that any *actual* cost cannot exceed a worst case estimate.
|
||||
- #### DBMS Catalog #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:24:53.519Z
|
||||
card-last-score:: 1
|
||||
- The **DBMS Catalog** stores ==statistical information about each table== such as table sizes, indexes & their depths, etc.
|
||||
- The statistical information on the tables & attributes used in a query can be found in the DBMS catalog and these are used to calculate estimates also.
|
||||
- In the DBMS catalog, for each table $R$, information is stored on:
|
||||
- The number of tuples / records in $R$.
|
||||
- The number of blocks containing tuples of table $R$.
|
||||
- The size of a record in bytes.
|
||||
- The blocking factor.
|
||||
- Information on the number of distinct values per attribute and the number of values that would satisfy a set of equality operations on that attribute (by having averages, min, max, etc.).
|
||||
- Information on indices (index type, index field values, etc.).
|
||||
- ## Optimisation Approach 1: Compare Cost Estimates Across Different Solutions #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:52:10.705Z
|
||||
card-last-score:: 1
|
||||
- Cost is usually measured as the **total elapsed time** for answering a query.
|
||||
- One approach to optimisation is to calculate cost estimates for each possible query tree.
|
||||
- The query tree with the lowest **cost estimate** should then be chosen.
|
||||
- ### Steps
|
||||
- 1. Generate query trees & evaluation plans (maybe not all).
|
||||
2. For each query tree, get cost estimates using the DBMS catalog.
|
||||
- This results in a set of cost estimates such that the best can be chosen and the query tree with the lowest cost estimate can then be picked as the single best query tree & evaluation plan.
|
||||
- Therefore, to choose among plans, the optimiser has to estimate the cost of each evaluation plan.
|
||||
- There are two aspects to this. For each node of the tree, estimate the cost of performing associated operation, and estimate the size of the result and if it is sorted.
|
||||
- ### Summary
|
||||
- While cost-based optimisation is good, it is expensive.
|
||||
- As query complexity increases, so does the number of different query trees & plans possible, and each query tree requires its own cost estimates.
|
||||
- **NB:** It is important that the amount of time an optimiser spends on calculating the best solution is not longer than the amount of time which would elapse if executing a solution picked at random.
|
||||
- ## Optimisation Approach 2: Heuristic Optimisation #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:24:24.658Z
|
||||
card-last-score:: 1
|
||||
- Optimisers often use **heuristics** to reduce the number of choices that must be made in a cost-based fashion.
|
||||
- Heuristic Optimisation transforms the query tree by ==using a set of rules that typically (but not always) improve execution performance.==
|
||||
- Some cost-based estimation is also performed as part of the heuristic optimisation and to choose between a reduced set of trees and/or evaluation plans.
|
||||
- ### Steps
|
||||
- 1. Create a **canonical query tree**.
|
||||
2. Apply a **set of heuristics** to the tree to create a more efficient query tree.
|
||||
3. If appropriate, create cost estimates of this query tree to ensure the best evaluation plan.
|
||||
- ### Canonical Query Trees
|
||||
- What is a **canonical query tree**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:22:12.535Z
|
||||
card-last-score:: 1
|
||||
- A **canonical query tree** is an *inefficient* query tree representing relational algebra expressions which can be created **directly** from the SQL solution following a sequence of quick & easy steps.
|
||||
- A canonical query tree:
|
||||
- Uses **Cartesian Product** instead of **Joins**.
|
||||
- Keeps all conditions ($\sigma$) together in one internal node.
|
||||
- $\pi$ become the root node.
|
||||
- #### Steps to create a Canonical Query Tree with `SELECT`/`WHERE`/`FROM` clauses and no sub-queries:
|
||||
- 1. All relations in the `FROM` clause become leaves of the tree.
|
||||
- They should be combined with a **Cartesian Product** ($\times$) of the relations.
|
||||
- **Note:** Only two relations can be involved in a Cartesian Product at a time (binary tree).
|
||||
- 2. All conditions in the `WHERE` clause and any `JOIN` conditions in `WHERE` or `FROM` clauses become a sequence of relational algebra in **one** inner node of the tree (with inputs from the previous step).
|
||||
3. All conditions from the `SELECT` clause become a relational algebra expression in the root node.
|
||||
- Heuristic Optimisation **must** transform this canonical query tree into a final query tree that is efficient to execute.
|
||||
- In general, heuristic optimisation tries to ==apply the most restrictive operators as early as possible== in the tree and to ==reduce the size of the temporary tables / results== created that move "up" the tree.
|
||||
- Heuristic Optimisation must include rules for equivalence among relational algebra expressions that can be applied to the initial tree.
|
||||
- ### Heuristic Optimisation Algorithm #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:25:04.590Z
|
||||
card-last-score:: 1
|
||||
- **Input:** A canonical query tree.
|
||||
- **Process:**
|
||||
- 1. Decompose any $\sigma$ with AND conditions into an individual $\sigma$.
|
||||
2. Move each $\sigma$ operator as far down the query tree as possible, thus eliminating unwanted tuples.
|
||||
- Heuristic 1 tries to reduce the size of the tables to be combined as much as possible.
|
||||
- Therefore, if a selection operator ($\sigma$) occurs *after* a Cartesian product or a join, check to see if it could occur *before* these operations.
|
||||
- 3. Rearrange the leaf nodes so that the most restrictive $\sigma$ can be applied first (using information from the DBMS catalog) and so that future JOINS are possible.
|
||||
- **Note:** "Most restrictive" means those operators that result in relations with the fewest tuples or with the smallest absolute size.
|
||||
- These operations should happen first, i.e., on the left-hand side of the lowest level of the tree.
|
||||
- If we don't have any information from the DBMS catalog, we might leave nodes as they are, use the database schema (# of columns) to make a good estimate, or use sample data (# of rows) & database schema (# of columns) to make a good estimate.
|
||||
- 4. Combine Cartesian Product operators with $\sigma$ to form JOIN operators where appropriate (replacing all $\times$).
|
||||
- Must first ensure that the leaf nodes are ordered such that this can occur. If not, re-order the leaf nodes and ensure to keep any select operators with the appropriate leaf node.
|
||||
- 5. Decompose $\pi$ and move each $\pi$ as far down the tree as possible, possibly creating new $\pi$ operators in the process to eliminate unwanted columns.
|
||||
- This heuristic ensure that the size of the tables to be joined are as small as possible.
|
||||
- Therefore, for each $\pi$ check if that $\pi$ can be carried out before the join. For each table, check if additional $\pi$s can be introduced (these may not be stated explicitly in the query).
|
||||
- **Note:** Must ensure that all needed columns further up the tree are retained (even if they are not immediately necessary).
|
||||
- 6. Identify subtrees that represent groups of operations that can be executed by a single algorithm.
|
||||
7. Add an evaluation plan.
|
||||
- **Output:** An efficient query tree.
|
||||
-
|
||||
@ -0,0 +1,225 @@
|
||||
- #[[CT230 - Database Systems I]]
|
||||
- **Previous Topic:** [[Normalisation]]
|
||||
- **Next Topic:** [[Query Processing & Optimisation]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Query Processing
|
||||
- What is **Query Processing**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:16:17.961Z
|
||||
card-last-score:: 1
|
||||
- **Query Processing** transforms SQL (a high-level language) into a correct & efficient low-level language representation of **relational algebra**.
|
||||
- Each relational algebra operator has code associated with it, which, when run, performs the operation on the data specified, allowing the specified data to be output as the result.
|
||||
- ## Steps Involved in Processing an SQL Query #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:52:53.439Z
|
||||
card-last-score:: 1
|
||||
- 1. Process (Parse & Translate) the query and create an internal representation of the query.
|
||||
- This may be an Operator Tree, Query Tree, or Query Graph (for more complicated queries).
|
||||
- 2. Optimise.
|
||||
3. Execute / Evaluate returning results.
|
||||
- What do you need to translate SQL to Relational Algebra? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:21:00.003Z
|
||||
card-last-score:: 1
|
||||
- To translate SQL to Relational Algebra, you must have a meaningful set of relational algebra operators, and a mapping (translation) between SQL code & relational algebra expressions.
|
||||
- # Relational Algebra
|
||||
- Two formal languages exist for the relational model:
|
||||
- **Relational Algebra** (procedural).
|
||||
- **Relational Calculus** (non-procedural).
|
||||
- Both are logically equivalent.
|
||||
- ## Relational Algebra Operations
|
||||
- A basic set of operations exist for the relational model.
|
||||
- These allow for the specification of basic retrieval requests.
|
||||
- A sequence of Relational Algebra (RA) operations forms a **relational algebra expression**.
|
||||
- RA operations are divided into two groups:
|
||||
- Operations based on **mathematical set theory** (e.g., union, product, etc.).
|
||||
- Specific relational database operations.
|
||||
- ## Relational Algebra vs SQL #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:53:39.774Z
|
||||
card-last-score:: 1
|
||||
- The core operations & functions (i.e., programs) in the internal modules of most relational database systems are based on **relational algebra**.
|
||||
- SQL is a **declarative language** - It allows you to specify the results that you require, not the order of the operations to retrieve these results.
|
||||
- Relational Algebra is **procedural** - We must specify exactly *how* to retrieve results when using relational algebra.
|
||||
- ## Relational Algebra Expressions
|
||||
- A valid relational algebra expression is built by connecting tables or expressions with defined **unary & binary operators** & their arguments (if applicable).
|
||||
- Temporary relations resulting from a relational algebra expression can be used as input to a new relational algebra expression.
|
||||
- Expressions in brackets are evaluated first.
|
||||
- Relational Algebra operators are either **unary** or **binary**.
|
||||
- ## Working With the [RelaX Calculator](https://dbis-uibk.github.io/relax/calc/local/uibk/local/0)
|
||||
- There is no standard language for relational algebra like there is for SQL.
|
||||
- One University group have developed a calculator that supports a *fairly* command standard.
|
||||
- Note that it is Case Sensitive.
|
||||
- The RelaX calculator provides a number of datasets with the option of also using your own dataset.
|
||||
- ### Loading a Dataset
|
||||
- 1. Go to the "Group Editor" tab.
|
||||
2. Copy text from the file on Blackboard and add.
|
||||
3. Then choose "Preview".
|
||||
4. Then choose "Use group in Editor".
|
||||
- **Note:** Only stored temporarily.
|
||||
- ### Note on Degrees
|
||||
- The **degree** of the relation resulting from a selection of a table $R$ is the same as the degree of $R$, i.e., they have the same number of attributes (columns).
|
||||
- The operation is **commutative** - i.e., a sequence of selects can be applied in any order.
|
||||
- E.g.:
|
||||
- $$\sigma_{\text{hours < 20 and pno = 10}}\text{works\_on}$$
|
||||
- $$\sigma_{\text{pno = 10 and hours < 20}}\text{works\_on}$$
|
||||
- # Relational Algebra: Unary Operators
|
||||
- Each operation takes one relation or expression as input and gives a new relation as a result.
|
||||
- ## Selection Operator ($\sigma$) #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:16:42.201Z
|
||||
card-last-score:: 1
|
||||
- Used to **select** certain tuples (rows) from a relation $R$.
|
||||
- **Notation:** $\sigma_pR$, where $p$ is the **selection predicate** (i.e., a *condidtion*) and $R$ is a relation / table name.
|
||||
- **Note:** The Selection ($\sigma$) operator in relational algebra is **not** the same as the `SELECT` clause in an SQL query.
|
||||
- An SQL `SELECT` query could be equivalent to a combination of relational algebra operators, ($\sigma$, $\pi$, or `JOIN`).
|
||||
- ### Example (Using Company Schema)
|
||||
- Find the projects with pno = 10 and hours worked < 20.
|
||||
background-color:: green
|
||||
- $$\sigma_{\text{hours < 20 AND pno = 10}}\text{works\_on}$$
|
||||
- Returns the set:
|
||||
- {(333445555, 10, 10.0 ), (999887777, 10, 10.0)}
|
||||
- ## Projection Operator ($\pi$) #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:20:37.894Z
|
||||
card-last-score:: 1
|
||||
- Used to return certain attributes / columns.
|
||||
- **Notation:**
|
||||
- $$\pi_{A_1, A_2, \cdots, A_k}(R)$$
|
||||
- Where $A_1, \cdots, A_k$ are attribute names, $R$ is a relation name.
|
||||
- The result is a relation with the $k$ attributes listed in the same order as they appear in the list.
|
||||
- Duplicate tuples are removed from the result.
|
||||
- **Note:** Commutativity does *not* hold.
|
||||
- ### Example (Using Company Schema)
|
||||
- List all the department numbers where employees work.
|
||||
background-color:: green
|
||||
- $$\pi_\text{dno}\text{employee}$$
|
||||
- Returns: {5,4,1}.
|
||||
- ## Rename Operators ($\rho$ & $\leftarrow$) #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:23:44.470Z
|
||||
card-last-score:: 1
|
||||
- Rename Operation ($\rho$).
|
||||
- **Notation:** $\rho_x(E)$, where the result of the expression $E$ is saved with the name $x$.
|
||||
- ## Order Operator ($\tau$) #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-22T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-21T13:09:00.157Z
|
||||
card-last-score:: 1
|
||||
- Used to **order** by certain columns from a relation $R$.
|
||||
- **Notation:** $\tau_{A_1, A_2, \cdots, A_k}R$ where $A_1, A_2, \cdots, A_k$ are attributes with either ASC or DESC.
|
||||
- ## Group By Operator ($\gamma$)
|
||||
- Used to **group** by certain columns from a relation $R$.
|
||||
- ## Aggregate Functions Supported by RelaX
|
||||
- (Not part of Relation Algebra),
|
||||
- `COUNT(*)`.
|
||||
- `COUNT(column)`.
|
||||
- `MIN(column)`.
|
||||
- `MAX(column)`.
|
||||
- `SUM(column)`.
|
||||
- `AVG(column)`.
|
||||
- # Binary Operators
|
||||
- General syntax: `(child_expression) function argument (child_argument)`.
|
||||
- ## Union Operator ($\cup$) #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:54:46.077Z
|
||||
card-last-score:: 1
|
||||
- **Notation:** $(R) \cup (S)$, where $R$ & $S$ are relations.
|
||||
- Returns all tuples from $R$ and all tuples from $S$.
|
||||
- **Note:** No duplicates will be returned.
|
||||
- ## Intersection Operator ($\cap$) #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:25:05.543Z
|
||||
card-last-score:: 1
|
||||
- **Notation:** $(R) \cap (S)$, where $R$ & $S$ are relations.
|
||||
- Returns all tuples from $R$ that are also in $S$.
|
||||
- ## Set Difference ($-$) #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:26:25.449Z
|
||||
card-last-score:: 1
|
||||
- **Notation:** $(R) - (S)$ where $R$ & $S$ are relations.
|
||||
- Returns tuples that are in relation $R$ but not in $S$.
|
||||
- **Note:** $(R) - (S)$ and $(S) - (R)$ are not the same.
|
||||
- ## Union Compatibility
|
||||
- What is **Union Compatibility**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T15:50:22.644Z
|
||||
card-last-score:: 1
|
||||
- For union, intersection, & minus, relations must be **union compatible**.
|
||||
- That is, schemas of relations must match, i.e., have the same number of attributes and each corresponding attributes have the same domain.
|
||||
- ## Cartesian Product Operator ($\times$) (Cross-Join) #card
|
||||
id:: 636a860b-5170-4227-befa-68876a53c856
|
||||
card-last-interval:: 0.98
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-22T12:05:57.590Z
|
||||
card-last-reviewed:: 2022-11-21T13:05:57.590Z
|
||||
card-last-score:: 3
|
||||
- **Notation:** $(R) \times (S)$ where $R$ & $S$ are relations / tables.
|
||||
- **Returns:** Tuples comprising the concatenation (combination) of *every tuple* in $R$ with *every tuple* in $S$.
|
||||
- **Note:** No condition specified.
|
||||
- ### Cartesian Product vs Join #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:20:31.096Z
|
||||
card-last-score:: 1
|
||||
- The main difference between a Cartesian product operator and a Join operator is that, with a Join, only tuples **satisfying a condition** appear in the result, while in a Cartesian product operator, all combinations of tuples are included in the result.
|
||||
- ## Join Operator ($\Join$) #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:23:36.847Z
|
||||
card-last-score:: 1
|
||||
- The **Join Operator** is a *hybrid* operator - it is a combination of the **Cartesian Product** operator ($\times$) & a **Select** operator ($\sigma$).
|
||||
- Tables are joined together based on the **condition** specified.
|
||||
- ## Equi & Theta Joins #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-19T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-18T18:37:52.403Z
|
||||
card-last-score:: 1
|
||||
- **Notation:** $(R_1) \Join p (R_2)$ where $p$ is the **join condition** and $R_1$ & $R_2$ are relations.
|
||||
- **Result:** The `JOIN` operation returns all combinations of tuples from relation $R_1$ & relation $R_2$ satisfying the join condition $p$.
|
||||
- **Note:** EQUI JOINS use only equality comparisons (`=`) in the join condition $p$.
|
||||
-
|
||||
-
|
||||
122
year2/semester1/logseq-stuff/pages/Random Variables.md
Normal file
122
year2/semester1/logseq-stuff/pages/Random Variables.md
Normal file
@ -0,0 +1,122 @@
|
||||
- #[[ST2001 - Statistics in Data Science I]]
|
||||
- **Previous Topic:** [[Probability]]
|
||||
- **Next Topic:** [[Discrete Probability Distributions: Binomial & Poisson]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Random Variables
|
||||
- What is a **random variable**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-11-21T20:17:50.156Z
|
||||
card-last-reviewed:: 2022-11-17T20:17:50.157Z
|
||||
card-last-score:: 3
|
||||
- A **random variable** is a function that associates a real number with each element in the sample space.
|
||||
- The probability distribution of a random variable $X$ gives the probability for each value of $X$.
|
||||
- A random variable takes a **numeric** value based on the outcome of a random event.
|
||||
- Random variables are denoted by a capital letter - $X$, $Y$, $Z$, etc.
|
||||
- A particular value of a random variable will be denoted with a lower case letter - $x$, $y$, $z$, etc.
|
||||
- What are the two types of random variables? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T03:20:55.056Z
|
||||
card-last-reviewed:: 2022-11-14T20:20:55.056Z
|
||||
card-last-score:: 5
|
||||
- There are two types of random variables:
|
||||
- **Discrete** random variables can take one of a finite number of distinct outcomes.
|
||||
- **Continuous** random variables can take any numeric value within a range of values.
|
||||
-
|
||||
-
|
||||
- # Probability Distributions
|
||||
- ## Discrete Probability Distributions
|
||||
- What is the **probability distribution** of some discrete random variable $X$? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:14:46.764Z
|
||||
card-last-score:: 1
|
||||
- The set of ordered pairs $(x, f(x))$ is a **probability function**, **probability mass function** (pmf), or **probability distribution** of the discrete random variable $X$ if, for each possible outcome $x$:
|
||||
- 1. $f(x) \geq 0$,
|
||||
- 2. $\displaystyle \sum_n f(x) = 1$,
|
||||
- 3. $P(X = x) = f(x)$.
|
||||
- What is the **cumulative distribution function** of a discrete random variable $X$? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T20:19:37.665Z
|
||||
card-last-score:: 1
|
||||
- The **cumulative distribution function** is the probability that a random variable $X$ with a given probability distribution will be ^^found at a value less than or equal to^^ $x$.
|
||||
- The **cumulative distribution function** $F(x)$ of a discrete random variable $X$ with probability distribution $f(x)$ is:
|
||||
- $$F(x) = P(X \leq x) = \sum_{t \leq x} f(t), \text{ for } - \infty < x < \infty$$
|
||||
- ## Continuous Probability Distributions
|
||||
- What is the **probability distribution function** for a continuous random variable? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T20:25:33.722Z
|
||||
card-last-score:: 1
|
||||
- The function $f(x)$ is a **probability distribution function** (pdf) for a continuous random variable $X$, defined over a set of real numbers, if:
|
||||
- 1. $f(x) \geq 0, \text{ for all } x \in R$,
|
||||
- 2. $\int^{\infty}_{- \infty} f(x) dx = 1$,
|
||||
- 3. $P(a < X < b) = \int^{b}_{a} f(x)dx$.
|
||||
- **Note:** $P(X = x) = 0$, i.e., there is no area exactly at $x$.
|
||||
-
|
||||
-
|
||||
- # Expected Value - Location
|
||||
- What is **expected value** for a **discrete** random variable? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-19T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-18T18:33:23.280Z
|
||||
card-last-score:: 1
|
||||
- The average, or **expected value** of a random variable is denoted by $E[X]$ & $\mu$.
|
||||
- It can be found by summing the products of each possible value multiplied by the probability that it occurs:
|
||||
- $$\mu = E[X] = \sum_x xP(X = x)$$
|
||||
- What is the **expected value** for a **continuous** random variable? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T20:18:12.187Z
|
||||
card-last-score:: 1
|
||||
- A useful summary of interest is the average, or **expected value** of a random variable.
|
||||
- The **expected value** is denoted by $E[X]$ & $\mu$.
|
||||
- The **expected value** of a ***continuous*** random variable can be found by:
|
||||
- $$\mu = E(X) = \int_{-\infty}^{\infty} xf(x)dx$$
|
||||
- # Variance, Standard Deviation - Spread
|
||||
- What is the **variance** & hence the **standard deviation** of a discrete random variable? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:18:19.897Z
|
||||
card-last-score:: 1
|
||||
- The **variance** of a **discrete** random variable measures the squared deviation from the mean:
|
||||
- $$\sigma^2 = \text{Var}(X) = E[(X - \mu)^2] = \sum_x (x - \mu)^2 P(X =x)$$
|
||||
- Alternatively, variance can be calculated by:
|
||||
- $$\text{Var}(X) = E(X^2) - E^2(X)$$
|
||||
- Where
|
||||
- $$E(X^2) = \sum x^2P(X = x)$$
|
||||
- Or, more usefully, the **standard deviation** is:
|
||||
- $$\sigma = \text{sd}(X) = \sqrt{\text{Var}(X)}$$
|
||||
- The standard deviation has the advantage of being in the same units as $X$ (& $\mu$).
|
||||
- What is the **variance** of a ***continuous*** random variable? #card
|
||||
card-last-score:: 1
|
||||
card-repeats:: 1
|
||||
card-next-schedule:: 2022-11-19T00:00:00.000Z
|
||||
card-last-interval:: -1
|
||||
card-ease-factor:: 2.5
|
||||
card-last-reviewed:: 2022-11-18T18:35:05.927Z
|
||||
- The **variance** of a **continuous** random variable is:
|
||||
- $$\text{var}(X) = \int_{-\infty}^{\infty} (x - \mu)^2 f(x)dx$$
|
||||
- # Means & Variances
|
||||
- Adding or subtracting a constant from data shifts the mean, but does not change the variance or the standard deviation.
|
||||
- $$E[X +c] = E[X] +c, \ \ \text{Var}(X+c) = \text{Var}(X), \ \ \text{sd}(X + c) = sd(X)$$
|
||||
- $$E[X -c] = E[X] -c,\ \ \text{Var}(X -c) = \text{Var}(X), \ \ \text{sd}(X - c) = \text{sd}(X)$$
|
||||
- Multiplying a random variable by a constant multiplies the mean by that constant, and the variance by the *square* of that constant.
|
||||
- $$E[aX] = aE[X], \ \ \text{Var}(aX) = a^2 \text{Var}(X), \ \ \text{sd}(aX) = |a|\text{sd}(X)$$
|
||||
184
year2/semester1/logseq-stuff/pages/SCRUM Roles & Ceremonies.md
Normal file
184
year2/semester1/logseq-stuff/pages/SCRUM Roles & Ceremonies.md
Normal file
@ -0,0 +1,184 @@
|
||||
- #[[CT216 - Software Engineering I]]
|
||||
- **Previous Topic:** [[Introduction to Agile Methods]]
|
||||
- **Next Topic:** [[Agile Methods - Extreme Programming]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Scrum Framework
|
||||
- ## Roles
|
||||
collapsed:: true
|
||||
- Product Owner
|
||||
- ScrumMaster
|
||||
- Team
|
||||
-
|
||||
- ### Product Owner #card
|
||||
card-last-interval:: 31.36
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-12-16T04:11:05.335Z
|
||||
card-last-reviewed:: 2022-11-14T20:11:05.336Z
|
||||
card-last-score:: 5
|
||||
- Define the features of the product.
|
||||
- Tries to remove conjecture - "I know the customer wants this" as opposed to "I believe this would be a good feature".
|
||||
- Decide on release date and content.
|
||||
- Usually responsible for press release.
|
||||
- Be responsible for the profitability of the product (ROI).
|
||||
- Prioritise features according to market value.
|
||||
- Conduct market research, feasibility studies.
|
||||
- Adjust features & priority every iteration, as needed.
|
||||
- Accept or reject work results.
|
||||
- ### Scrum Master #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:42:56.790Z
|
||||
card-last-score:: 1
|
||||
- Represents management to the project.
|
||||
- Often one of the engineers.
|
||||
- Responsible for enacting Scrum values & practices.
|
||||
- Removes impediments.
|
||||
- Ensure that the team is fully functional & productive.
|
||||
- Enable close cooperation across all roles & functions.
|
||||
- Shield the team from external interfaces.
|
||||
- ### Scrum Team #card
|
||||
card-last-interval:: 9.28
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-11-23T22:36:47.636Z
|
||||
card-last-reviewed:: 2022-11-14T16:36:47.637Z
|
||||
card-last-score:: 5
|
||||
- Typically 5-10 people.
|
||||
- Cross-functional.
|
||||
- QA, Programmers, UI Designers, etc.
|
||||
- Members should be full-time.
|
||||
- May be exceptions (e.g., System Admin, etc.).
|
||||
- Teams are self-organising.
|
||||
- Membership can change only between sprints.
|
||||
-
|
||||
- ## Ceremonies
|
||||
collapsed:: true
|
||||
- Sprints
|
||||
- Sprint Planning
|
||||
- Sprint Review
|
||||
- Sprint Retrospective
|
||||
- Daily Scrum Meeting
|
||||
-
|
||||
- ### Sprints #card
|
||||
card-last-interval:: 23.43
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-12-08T06:05:48.351Z
|
||||
card-last-reviewed:: 2022-11-14T20:05:48.351Z
|
||||
card-last-score:: 5
|
||||
collapsed:: true
|
||||
- Scrum projects make progress in a series of **sprints**.
|
||||
- Target duration is one month.
|
||||
- + / - a week or two (2 - 6 weeks max).
|
||||
- Product is designed, coded, and tested during the sprint.
|
||||
- The output is a built which may or may not be a release.
|
||||
- Move onto the next sprint.
|
||||
-
|
||||
- #### No changes during Sprint
|
||||
- Plan sprint durations around how long you can commit to keeping the change out of the Sprint.
|
||||
- ### Sprint Planning #card
|
||||
card-last-interval:: 11.34
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-26T00:48:37.703Z
|
||||
card-last-reviewed:: 2022-11-14T16:48:37.703Z
|
||||
card-last-score:: 5
|
||||
collapsed:: true
|
||||
- The Team selects items from the **product backlog** that they can commit to completing.
|
||||
- The **Sprint Backlog** is created.
|
||||
- Tasks are identified & the length of each is estimated (1-16 hours).
|
||||
- This is done collaboratively by the team.
|
||||
- 
|
||||
- #### Sprint Backlog
|
||||
- What is the **Product Backlog**? #card
|
||||
card-last-interval:: 31.36
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-12-16T04:11:04.051Z
|
||||
card-last-reviewed:: 2022-11-14T20:11:04.052Z
|
||||
card-last-score:: 5
|
||||
- The **Product Backlog** is a list of desired work on the project (the requirements).
|
||||
- It's usually a combination of:
|
||||
- **story-based work** - "let user search & replace".
|
||||
- **task-based work** - "improve exception handling".
|
||||
- The list is prioritised by the **Product Owner**.
|
||||
- The **Product Owner** is typically a Product Manager, Marketing, Internal Customer, etc.
|
||||
- Priority groupings (high, medium, low, etc.).
|
||||
- Re-prioritised at the start of each sprint.
|
||||
- Spreadsheet (usually).
|
||||
- To create a Sprint Backlog, you must have a Sprint goal.
|
||||
- The Scrum team takes the Sprint Goal and decides what tasks are necessary.
|
||||
- The Team self-organises around how they will meet the Sprint Goal.
|
||||
- Manager does not assign tasks to individuals.
|
||||
- Managers don't make decisions for the team.
|
||||
- A Sprint Backlog is created.
|
||||
- #### Sprint Backlogs during the Sprint
|
||||
- Changes
|
||||
- The Team adds new tasks whenever they need to, in order to meet the Sprint Goal.
|
||||
- The Team can remove unnecessary tasks.
|
||||
- But, the Sprint Backlog can only be updated by the team.
|
||||
- Estimates are updated whenever there's new information.
|
||||
-
|
||||
- ### Sprint Review Meeting #card
|
||||
card-last-interval:: 23.43
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-12-08T06:05:33.096Z
|
||||
card-last-reviewed:: 2022-11-14T20:05:33.096Z
|
||||
card-last-score:: 5
|
||||
- The Team presents what it accomplished during the sprint.
|
||||
- It typically takes the form of a demo of new features or underlying architecture.
|
||||
- Informal.
|
||||
- 2 hour prep time.
|
||||
- No slides.
|
||||
- Participants.
|
||||
- Customers.
|
||||
- Management.
|
||||
- Product Owners.
|
||||
- Engineering Team.
|
||||
- ### Sprint Retrospective Meeting #card
|
||||
card-last-interval:: 29.04
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-12-13T20:03:02.515Z
|
||||
card-last-reviewed:: 2022-11-14T20:03:02.515Z
|
||||
card-last-score:: 5
|
||||
- Typically 15-30 mintues.
|
||||
- Done after every sprint.
|
||||
- Feedback meeting - time to reflect on how things are going...
|
||||
- Many participants.
|
||||
- Scrum Master
|
||||
- Product Owner
|
||||
- Team
|
||||
- Possibly customers & others
|
||||
- The whole team gathers & discusses what they'd like to:
|
||||
- Start doing.
|
||||
- Stop doing.
|
||||
- Continue doing,
|
||||
-
|
||||
-
|
||||
- ## Pros / Cons of Agile Methods #card
|
||||
card-last-interval:: 23.43
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-12-08T06:05:31.402Z
|
||||
card-last-reviewed:: 2022-11-14T20:05:31.402Z
|
||||
card-last-score:: 5
|
||||
- ### Advantages
|
||||
- Completely developed & tested features in short iterations.
|
||||
- Simplicity of the process.
|
||||
- Clearly defined rules.
|
||||
- Increasing productivity.
|
||||
- Self-organising.
|
||||
- Each team member carries a lot of responsibility.
|
||||
- Improved communication.
|
||||
- Combination with Extreme Programming.
|
||||
- ### Disadvantages
|
||||
- "Undisciplined hacking" (no written documentation).
|
||||
- Violation of responsibility.
|
||||
- Current mainly carried by the inventors.
|
||||
- Employee burnout & fatigue.
|
||||
194
year2/semester1/logseq-stuff/pages/SQL DML Statement.md
Normal file
194
year2/semester1/logseq-stuff/pages/SQL DML Statement.md
Normal file
@ -0,0 +1,194 @@
|
||||
- #[[CT230 - Database Systems I]]
|
||||
- **Previous Topic:** [[Introduction to SQL & DDL]]
|
||||
- **Next Topic:** [[SQL DML: SELECT]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Notes on Syntax
|
||||
- While SQL is case insensitive, Linux ^^is not.^^
|
||||
- web1.cs.nuigalway.ie is a ^^linux server^^, so we need to be careful with table names in particular, as `EMPLOYEE` is ^^not the same thing^^ as `employee`.
|
||||
- Attribute names are separated by commas.
|
||||
- Strings are enclosed in quotes.
|
||||
- Numbers are not enclosed in quotes.
|
||||
-
|
||||
- Usually, SQL keywords are capitalised while table & keyword names are mostly kept in lowercase unless using camelCase instead of snake_case.
|
||||
- Code should be organised horizontally & vertically, and not all written on one line.
|
||||
- Code blocks are separated by a semicolon.
|
||||
- Comments can be made using `#`, `--`, & `/* */`.
|
||||
-
|
||||
- # **CRUD** Operations in DML
|
||||
- What are **CRUD** Operations? #card
|
||||
card-last-interval:: 31.36
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-12-16T04:09:37.257Z
|
||||
card-last-reviewed:: 2022-11-14T20:09:37.258Z
|
||||
card-last-score:: 5
|
||||
- **CRUD** operations are the 4 basic functions that we may wish to perform on *persistent* data.
|
||||
- **Create:** insert a new tuple. `INSERT`
|
||||
- **Read:** retrieve some data. `SELECT`
|
||||
- **Update:** modify some data. `Update`
|
||||
- **Delete:** delete some data or a tuple. `DELETE`
|
||||
- ## Read: `SELECT`
|
||||
- The basic syntax for an SQL select query to *read* data consists of 6 clauses. #card
|
||||
collapsed:: true
|
||||
card-last-interval:: 19.01
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-03T20:06:02.473Z
|
||||
card-last-reviewed:: 2022-11-14T20:06:02.473Z
|
||||
card-last-score:: 3
|
||||
- ```sql
|
||||
SELECT [DISTINCT] <attribute list>
|
||||
FROM <table list>
|
||||
WHERE <condition>
|
||||
GROUP BY <group attributes>
|
||||
HAVING <group condition>
|
||||
ORDER BY <attribute list>
|
||||
```
|
||||
- The order of these clauses ^^cannot be changed.^^
|
||||
- `SELECT` & `FROM` are ^^always required^^, other clauses are optional.
|
||||
- ### `SELECT <attribute list> FROM <table list> WHERE <condition>` #card
|
||||
collapsed:: true
|
||||
card-last-interval:: 108
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 3
|
||||
card-next-schedule:: 2023-03-06T18:36:40.152Z
|
||||
card-last-reviewed:: 2022-11-18T18:36:40.153Z
|
||||
card-last-score:: 5
|
||||
- `<attribute list>` is a list of **attribute** (column) names (separated by commas) whose values will be retrieved by the query.
|
||||
- `<table list>` is a list of table names (separated by commas) containing the attributes.
|
||||
- `<condition>` is a **Boolean** expression that identifies the tuples to be retrieved by the query.
|
||||
- For each **tuple** (row) in the table(s) which are part of the query:
|
||||
- the tuple is checked to see if the condition is **true** for this tuple.
|
||||
- If **true**, the tuple **is** part of the output.
|
||||
- If **false**, the tuple is **not** part of the output.
|
||||
- The comparison operators are:
|
||||
- `=` `<=` `<` `>` `>=` `!=`
|
||||
- Conditions can be compounded by use of Boolean `AND`, `OR`, and can be negated with `NOT`.
|
||||
- ^^Note:^^ In some versions of SQL, (e.g., in MS), the `!=` operator is written as `<>`.
|
||||
- ### Calculated or Derived Fields #card
|
||||
collapsed:: true
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-15T16:48:02.726Z
|
||||
card-last-reviewed:: 2022-11-17T09:48:02.727Z
|
||||
card-last-score:: 5
|
||||
- We can specify an SQL expression in the `SELECT` clause which can involve **numerical operations** on **numeric** fields and **counting operations** on **non-numeric** fields.
|
||||
- e.g.,
|
||||
- ```sql
|
||||
SELECT ssn, salary/12 FROM employee;
|
||||
```
|
||||
- ### Tidying Up the Output #card
|
||||
card-last-interval:: 19.01
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-03T20:05:39.227Z
|
||||
card-last-reviewed:: 2022-11-14T20:05:39.227Z
|
||||
card-last-score:: 3
|
||||
- We can use keywords `CAST`, `AS`, & `DECIMAL(x, y)` to specify the total number of digits `x` and the number of digits after the decimal point `y` when we're working with **real numbers**.
|
||||
- ```sql
|
||||
SELECT ssn, CAST(salary/12.0 AS DECIMAL(8,2))
|
||||
FROM employee;
|
||||
```
|
||||
- We can also use the keyword `AS` to rename output.
|
||||
- ```sql
|
||||
SELECT ssn, CAST(salary/12.0 AS DECIMAL(8,2))
|
||||
AS monthlySalary
|
||||
FROM employee;
|
||||
```
|
||||
-
|
||||
- ### Keyword `DISTINCT` #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-21T00:50:04.359Z
|
||||
card-last-reviewed:: 2022-11-17T09:50:04.360Z
|
||||
card-last-score:: 5
|
||||
- The keyword `DISTINCT` automatically removes duplicates from the returned result set.
|
||||
- We should be careful of using with large result sets as it can be an expensive operation to perform (not a problem for our small examples).
|
||||
- ```sql
|
||||
SELECT DISTINCT salary
|
||||
FROM employee;
|
||||
```
|
||||
- ### Selecting All Attribute Values for Selected Tuples #card
|
||||
card-last-interval:: 11.2
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-11-25T20:36:44.458Z
|
||||
card-last-reviewed:: 2022-11-14T16:36:44.458Z
|
||||
card-last-score:: 5
|
||||
- To retrieve all attribute values of selected tuples, you do not have to explicitly list all the attribute names - instead, you can use `SELECT *`.
|
||||
- ### New Operators
|
||||
collapsed:: true
|
||||
- `BETWEEN` #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T11:07:14.075Z
|
||||
card-last-reviewed:: 2022-11-14T20:07:14.075Z
|
||||
card-last-score:: 5
|
||||
- The `BETWEEN` operator selects values within a given range. The values can be numbers, texts, or dates.
|
||||
- ```sql
|
||||
SELECT <column name(s)>
|
||||
FROM <table name>
|
||||
WHERE <column name(s)> BETWEEN <value 1> AND <value 2>;
|
||||
```
|
||||
- `IN` #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T09:48:15.246Z
|
||||
card-last-score:: 1
|
||||
- The `IN` operator tests if a data value matches one of a list of values.
|
||||
- It is a shorthand for multiple `OR` conditions.
|
||||
- ```sql
|
||||
SELECT <column name(s)>
|
||||
FROM <table_name>
|
||||
WHERE <column_name> IN (<value1>, <value2>, ...);
|
||||
|
||||
-- OR --
|
||||
|
||||
SELECT <column_name(s)>
|
||||
FROM <table_name>
|
||||
WHERE <column_name> IN (SELECT <statement>);
|
||||
```
|
||||
- `LIKE` #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-21T00:50:18.687Z
|
||||
card-last-reviewed:: 2022-11-17T09:50:18.687Z
|
||||
card-last-score:: 5
|
||||
- Allows string comparison, when equality is too strict.
|
||||
- There are 2 wildcards, often used in conjunction with the `LIKE` operator:
|
||||
- The percent sign `%` represents zero, one, or multiple characters.
|
||||
- The underscore sign `_` represents one, single character.
|
||||
- ```sql
|
||||
SELECT <column_name(s)>
|
||||
FROM <table_name>
|
||||
WHERE <column_name> LIKE <pattern>;
|
||||
```
|
||||
- `IS NULL` #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:38:30.380Z
|
||||
card-last-reviewed:: 2022-11-14T16:38:30.380Z
|
||||
card-last-score:: 5
|
||||
- Allows an explicit search for `NULL`.
|
||||
-
|
||||
-
|
||||
- ### Set Operators
|
||||
- `UNION`
|
||||
- `INTERSECTION`
|
||||
- `MINUS / DIFFERENCE`
|
||||
-
|
||||
-
|
||||
- ```SQL
|
||||
SELECT full_name, ssn FROM (
|
||||
SELECT ssn, CONCAT(fname, " ", minit, " ", lname)
|
||||
AS full_name from employee) AS dtable
|
||||
WHERE full_name IN ("John B Smith", "James E Borg", "Joyce A English");
|
||||
```
|
||||
192
year2/semester1/logseq-stuff/pages/SQL DML%3A SELECT.md
Normal file
192
year2/semester1/logseq-stuff/pages/SQL DML%3A SELECT.md
Normal file
@ -0,0 +1,192 @@
|
||||
title:: SQL DML: SELECT
|
||||
|
||||
- #[[CT230 - Database Systems I]]
|
||||
- **Previous Topic:** [[SQL DML Statement]]
|
||||
- **Next Topic:** [[SQL SELECT: Working with Strings & Subqueries]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Notes on Syntax
|
||||
- While SQL is case insensitive, Linux ^^is not.^^
|
||||
- web1.cs.nuigalway.ie is a ^^linux server^^, so we need to be careful with table names in particular, as `EMPLOYEE` is ^^not the same thing^^ as `employee`.
|
||||
- Attribute names are separated by commas.
|
||||
- Strings are enclosed in quotes.
|
||||
- Numbers are not enclosed in quotes.
|
||||
-
|
||||
- Usually, SQL keywords are capitalised while table & keyword names are mostly kept in lowercase unless using camelCase instead of snake_case.
|
||||
- Code should be organised horizontally & vertically, and not all written on one line.
|
||||
- Code blocks are separated by a semicolon.
|
||||
- Comments can be made using `#`, `--`, & `/* */`.
|
||||
-
|
||||
- # **CRUD** Operations in DML
|
||||
- What are **CRUD** Operations? #card
|
||||
card-last-interval:: 7.44
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.08
|
||||
card-next-schedule:: 2022-11-22T02:35:29.285Z
|
||||
card-last-reviewed:: 2022-11-14T16:35:29.286Z
|
||||
card-last-score:: 3
|
||||
- **CRUD** operations are the 4 basic functions that we may wish to perform on *persistent* data.
|
||||
- **Create:** insert a new tuple. `INSERT`
|
||||
- **Read:** retrieve some data. `SELECT`
|
||||
- **Update:** modify some data. `Update`
|
||||
- **Delete:** delete some data or a tuple. `DELETE`
|
||||
- ## Read: `SELECT`
|
||||
- The basic syntax for an SQL select query to *read* data consists of 6 clauses. #card
|
||||
card-last-interval:: 19.01
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-03T20:06:00.414Z
|
||||
card-last-reviewed:: 2022-11-14T20:06:00.414Z
|
||||
card-last-score:: 3
|
||||
- ```sql
|
||||
SELECT [DISTINCT] <attribute list>
|
||||
FROM <table list>
|
||||
WHERE <condition>
|
||||
GROUP BY <group attributes>
|
||||
HAVING <group condition>
|
||||
ORDER BY <attribute list>
|
||||
```
|
||||
- The order of these clauses ^^cannot be changed.^^
|
||||
- `SELECT` & `FROM` are ^^always required^^, other clauses are optional.
|
||||
- ### `SELECT <attribute list> FROM <table list> WHERE <condition>` #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-11-26T13:37:49.433Z
|
||||
card-last-reviewed:: 2022-11-22T13:37:49.433Z
|
||||
card-last-score:: 5
|
||||
- `<attribute list>` is a list of **attribute** (column) names (separated by commas) whose values will be retrieved by the query.
|
||||
- `<table list>` is a list of table names (separated by commas) containing the attributes.
|
||||
- `<condition>` is a **Boolean** expression that identifies the tuples to be retrieved by the query.
|
||||
- For each **tuple** (row) in the table(s) which are part of the query:
|
||||
- the tuple is checked to see if the condition is **true** for this tuple.
|
||||
- If **true**, the tuple **is** part of the output.
|
||||
- If **false**, the tuple is **not** part of the output.
|
||||
- The comparison operators are:
|
||||
- `=` `<=` `<` `>` `>=` `!=`
|
||||
- Conditions can be compounded by use of Boolean `AND`, `OR`, and can be negated with `NOT`.
|
||||
- ^^Note:^^ In some versions of SQL, (e.g., in MS), the `!=` operator is written as `<>`.
|
||||
- ### Calculated or Derived Fields #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-15T16:48:00.918Z
|
||||
card-last-reviewed:: 2022-11-17T09:48:00.918Z
|
||||
card-last-score:: 5
|
||||
- We can specify an SQL expression in the `SELECT` clause which can involve **numerical operations** on **numeric** fields and **counting operations** on **non-numeric** fields.
|
||||
- e.g.,
|
||||
- ```sql
|
||||
SELECT ssn, salary/12 FROM employee;
|
||||
```
|
||||
- ### Tidying Up the Output #card
|
||||
card-last-interval:: 19.01
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-03T20:05:40.995Z
|
||||
card-last-reviewed:: 2022-11-14T20:05:40.995Z
|
||||
card-last-score:: 3
|
||||
- We can use keywords `CAST`, `AS`, & `DECIMAL(x, y)` to specify the total number of digits `x` and the number of digits after the decimal point `y` when we're working with **real numbers**.
|
||||
- ```sql
|
||||
SELECT ssn, CAST(salary/12.0 AS DECIMAL(8,2))
|
||||
FROM employee;
|
||||
```
|
||||
- We can also use the keyword `AS` to rename output.
|
||||
- ```sql
|
||||
SELECT ssn, CAST(salary/12.0 AS DECIMAL(8,2))
|
||||
AS monthlySalary
|
||||
FROM employee;
|
||||
```
|
||||
-
|
||||
- ### Keyword `DISTINCT` #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-21T00:50:05.938Z
|
||||
card-last-reviewed:: 2022-11-17T09:50:05.938Z
|
||||
card-last-score:: 5
|
||||
- The keyword `DISTINCT` automatically removes duplicates from the returned result set.
|
||||
- We should be careful of using with large result sets as it can be an expensive operation to perform (not a problem for our small examples).
|
||||
- ```sql
|
||||
SELECT DISTINCT salary
|
||||
FROM employee;
|
||||
```
|
||||
- ### Selecting All Attribute Values for Selected Tuples #card
|
||||
card-last-interval:: 11.2
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-11-25T20:36:38.405Z
|
||||
card-last-reviewed:: 2022-11-14T16:36:38.405Z
|
||||
card-last-score:: 5
|
||||
- To retrieve all attribute values of selected tuples, you do not have to explicitly list all the attribute names - instead, you can use ```SELECT *```.
|
||||
- ### New Operators
|
||||
- `BETWEEN` #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T11:07:12.625Z
|
||||
card-last-reviewed:: 2022-11-14T20:07:12.625Z
|
||||
card-last-score:: 5
|
||||
- The `BETWEEN` operator selects values within a given range. The values can be numbers, texts, or dates.
|
||||
- ```sql
|
||||
SELECT <column name(s)>
|
||||
FROM <table name>
|
||||
WHERE <column name(s)> BETWEEN <value 1> AND <value 2>;
|
||||
```
|
||||
- `IN` #card
|
||||
card-last-interval:: 24.2
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-12-11T13:48:17.496Z
|
||||
card-last-reviewed:: 2022-11-17T09:48:17.496Z
|
||||
card-last-score:: 3
|
||||
- The `IN` operator tests if a data value matches one of a list of values.
|
||||
- It is a shorthand for multiple `OR` conditions.
|
||||
- ```sql
|
||||
SELECT <column name(s)>
|
||||
FROM <table_name>
|
||||
WHERE <column_name> IN (<value1>, <value2>, ...);
|
||||
|
||||
-- OR --
|
||||
|
||||
SELECT <column_name(s)>
|
||||
FROM <table_name>
|
||||
WHERE <column_name> IN (SELECT <statement>);
|
||||
```
|
||||
- `LIKE` #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T11:07:20.197Z
|
||||
card-last-reviewed:: 2022-11-14T20:07:20.198Z
|
||||
card-last-score:: 5
|
||||
- Allows string comparison, when equality is too strict.
|
||||
- There are 2 wildcards, often used in conjunction with the `LIKE` operator:
|
||||
- The percent sign `%` represents zero, one, or multiple characters.
|
||||
- The underscore sign `_` represents one, single character.
|
||||
- ```sql
|
||||
SELECT <column_name(s)>
|
||||
FROM <table_name>
|
||||
WHERE <column_name> LIKE <pattern>;
|
||||
```
|
||||
- `IS NULL` #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-21T00:49:58.730Z
|
||||
card-last-reviewed:: 2022-11-17T09:49:58.730Z
|
||||
card-last-score:: 5
|
||||
- Allows an explicit search for `NULL`.
|
||||
-
|
||||
-
|
||||
- ### Set Operators
|
||||
- `UNION`
|
||||
- `INTERSECTION`
|
||||
- `MINUS / DIFFERENCE`
|
||||
-
|
||||
-
|
||||
- ```SQL
|
||||
SELECT full_name, ssn FROM (
|
||||
SELECT ssn, CONCAT(fname, " ", minit, " ", lname)
|
||||
AS full_name from employee) AS dtable
|
||||
WHERE full_name IN ("John B Smith", "James E Borg", "Joyce A English");
|
||||
```
|
||||
@ -0,0 +1,181 @@
|
||||
title:: SQL SELECT: Working with Strings & Subqueries
|
||||
|
||||
- #[[CT230 - Database Systems I]]
|
||||
- **Previous Topic:** [[SQL DML: SELECT]]
|
||||
- **Next Topic:** [[Aggregate Clauses, Group By, & Having Clauses]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Keywords to Modify Output
|
||||
- `AS` #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:35:37.700Z
|
||||
card-last-score:: 1
|
||||
- Used to rename any output in `SELECT`.
|
||||
- Can also be used to **alias** (rename) tables in `FROM`.
|
||||
- `CONCAT` #card
|
||||
card-last-interval:: 11.2
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-11-25T20:35:14.265Z
|
||||
card-last-reviewed:: 2022-11-14T16:35:14.265Z
|
||||
card-last-score:: 5
|
||||
- Used to **concatenate** strings.
|
||||
- Similar usage to other programming languages.
|
||||
- ```sql
|
||||
SELECT
|
||||
CONCAT(fname, ' ', minit, ' ', lname) AS Name
|
||||
FROM
|
||||
employee
|
||||
WHERE
|
||||
salary BETWEEN 50000 AND 80000
|
||||
ORDER BY
|
||||
lname;
|
||||
```
|
||||
- `CAST` #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T11:21:08.757Z
|
||||
card-last-reviewed:: 2022-11-14T20:21:08.757Z
|
||||
card-last-score:: 5
|
||||
- `CAST(<expression> AS <datatype>(<length>))`
|
||||
- Used to cast to another datatype.
|
||||
- `ORDER BY` #card
|
||||
card-last-interval:: 11.2
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-11-25T20:37:08.438Z
|
||||
card-last-reviewed:: 2022-11-14T16:37:08.438Z
|
||||
card-last-score:: 5
|
||||
- `ORDER BY <attribute list> <order (ASC or DESC)> `.
|
||||
- Allows the results of a query to be ordered by values of one or more attributes.
|
||||
- Either **ascending** `ASC` or **descending** `DESC` - ascending by default.
|
||||
- Must be the *last* clause of a `SELECT` statement.
|
||||
- # `TOP` & `LIMIT` #card
|
||||
card-last-interval:: 10.97
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-25T15:38:08.480Z
|
||||
card-last-reviewed:: 2022-11-14T16:38:08.481Z
|
||||
card-last-score:: 5
|
||||
- The `SELECT TOP <N>` clause is used to specify the number of tuples (N) to return, but it is not supported by MySQL.
|
||||
- Instead, MySQL supports a `LIMIT <N>` clause which has the same functionality.
|
||||
- The `LIMIT` clause is listed at the end of the query,
|
||||
- Example: List the employees with the top 3 salaries.
|
||||
- ```sql
|
||||
SELECT
|
||||
ssn, CONCAT(fname, ' ', lname) as Name, salary
|
||||
FROM
|
||||
employee
|
||||
ORDER BY
|
||||
salary DESC
|
||||
LIMIT 4;
|
||||
```
|
||||
- # Strings
|
||||
- ## Note: 'Single' & "Double" Quotes #card
|
||||
card-last-interval:: 23.43
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-12-08T06:20:40.093Z
|
||||
card-last-reviewed:: 2022-11-14T20:20:40.094Z
|
||||
card-last-score:: 5
|
||||
- MySQL usually allows single & double quotes to be used interchangably.
|
||||
- Generally, single quotes should be used for strings (`varchar()`, `text`, etc.).
|
||||
- ### How to Deal with Apostrophes in Strings #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T11:21:10.692Z
|
||||
card-last-reviewed:: 2022-11-14T20:21:10.692Z
|
||||
card-last-score:: 5
|
||||
- You have to be careful with apostrophes in strings, as an opening quote could be accidentally closed by an apostrophe.
|
||||
- To overcome this, if there is an apostrophe in a string, it should be replaced by **two** apostrophes side-by-side `''` (this is a general rule for all special characters - have two of the character) or escape it with `\`.
|
||||
- Example: Select the salary for the employee with surname O'Grady.
|
||||
- ```SQL
|
||||
SELECT salary
|
||||
FROM employee
|
||||
WHERE lname = 'O''Grady';
|
||||
```
|
||||
- We must also take care when inserting string data using `INSERT INTO`.
|
||||
- ## Working with Strings & Pattern Matching #card
|
||||
card-last-interval:: 4.14
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-22T21:33:52.858Z
|
||||
card-last-reviewed:: 2022-11-18T18:33:52.859Z
|
||||
card-last-score:: 5
|
||||
- SQL is case insensitive (apart from table names if on a Linux server).
|
||||
- Case insensitivity generally applies to string searching.
|
||||
- However, *often* when working with strings we do not look for an exact match (i.e., an exact match using `=`).
|
||||
- To support partial matching, we often use **pattern-matching characters** and `LIKE` with wildcard characters `%` and `_`.
|
||||
- `%` represents 0 or more characters.
|
||||
- `_` Represents a single character.
|
||||
- ### Regexp
|
||||
- We can use regex for more complicated string matching.
|
||||
- ```sql
|
||||
SELECT <attribute>
|
||||
FROM <relation>
|
||||
WHERE <attribute> REGEXP <regexp>
|
||||
```
|
||||
- `^` Matches position at the **beginning** of the searched string.
|
||||
- `$` Matches position at the **end** of the searched string.
|
||||
- `[]` Matches any character inside the square brackets.
|
||||
- `[^]` Matches any character **not** inside the square brackets.
|
||||
- `*` Matches preceeding character 0 or more times.
|
||||
- `+` Matches preceeding character 1 or more times.
|
||||
- `|` OR.
|
||||
- `{n}` Matches preceeding character n number of times.
|
||||
- # Accessing Data Across Multiple Tables
|
||||
card-last-score:: 5
|
||||
card-repeats:: 2
|
||||
card-next-schedule:: 2022-10-11T03:36:21.816Z
|
||||
card-last-interval:: 3.71
|
||||
card-ease-factor:: 2.46
|
||||
card-last-reviewed:: 2022-10-07T10:36:21.817Z
|
||||
- What methods can you use for accessing data across multiple tables? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-18T20:10:10.085Z
|
||||
card-last-reviewed:: 2022-11-14T20:10:10.085Z
|
||||
card-last-score:: 5
|
||||
- There are 3 potential approaches:
|
||||
- Joins.
|
||||
- Subqueries.
|
||||
- Union queries.
|
||||
- ## Subqueries #card
|
||||
card-last-interval:: 11.2
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-11-25T20:36:08.786Z
|
||||
card-last-reviewed:: 2022-11-14T16:36:08.786Z
|
||||
card-last-score:: 5
|
||||
- A **subquery** (also called a **nested** query)is a query with another query.
|
||||
- The subquery *usually* returns data that will be used in the main query.
|
||||
- Data returned from the subquery may be a **set of values** or a **single value**.
|
||||
- Subqueries can be used with the `SELECT`, `INSERT`, `UPDATE`, and `DELETE` statements.
|
||||
- 
|
||||
- The `SELECT` statement that contains a subquery is called an **outer query**.
|
||||
- ### Connecting Inner & Outer Queries #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.08
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:19:14.578Z
|
||||
card-last-score:: 1
|
||||
- If a subquery returns only **one value** then we can use operators such as `=`, `!=`. `>`, `>=`, `<`, `<=`.
|
||||
- If a subquery *could* return **more than one value** (i.e., a list of values), then we need connectors such as `IN`, `ANY`, `ALL` to check through the values of the subquery.
|
||||
- The keyword `NOT` can also be used where appropriate.
|
||||
- These connectors are generally used with basic algebraic operators: `=`, `!=`. `>`, `>=`, `<`, `<=`.
|
||||
- `ALL` - the condition is true if the comparison is true for **every** (all) values returned by the subquery.
|
||||
- `ANY` - the condition is true if the comparison is true for **at least one** (any) value returned by the subquery.
|
||||
- `IN` - the condition is true if the comparison is true for **at least one** value returned by the subquery, i.e., a value IN the subquery.
|
||||
- `IN` checks for equality - it can be used for a list of values or a single value - it does not require any additional algebraic operator.
|
||||
- In addition, we can have a more general condition using:
|
||||
- `EXISTS` - True if there exists at least one value in the result from a subquery.
|
||||
- `NOT EXISTS` - True if there is nothing in the result from a subquery (i.e., it is empty).
|
||||
-
|
||||
-
|
||||
@ -0,0 +1,4 @@
|
||||
-
|
||||
- ## Office Hours
|
||||
- Tuesday 1200 - 1300
|
||||
-
|
||||
2
year2/semester1/logseq-stuff/pages/ST2001 Labs.md
Normal file
2
year2/semester1/logseq-stuff/pages/ST2001 Labs.md
Normal file
@ -0,0 +1,2 @@
|
||||
- #[[ST2001 - Statistics in Data Science I]]
|
||||
-
|
||||
@ -0,0 +1,94 @@
|
||||
- #[[ST2001 - Statistics in Data Science I]]
|
||||
- **Previous Topic:** [[The Normal Distribution]]
|
||||
- **Next Topic:** [[Hypothesis Testing]]
|
||||
- **Relevant Slides:** _1666624233800_0.pdf)
|
||||
-
|
||||
- # Probability & Statistics
|
||||
- In Probability theory, we consider some **known process** which has some randomness or uncertainty.
|
||||
- We model the outcomes by random variables, and we figure out the probabilities of what will happen.
|
||||
- There is one correct answer to any probability question.
|
||||
- In Statistical Inference, we observe something that has happened, and try to figure out what underlying process would explain those observations.
|
||||
- The basic aim behind all statistical methods is to make inferences about a population by studying a relatively small sample from it.
|
||||
- Probability is the engine that drives all statistical modelling, data analysis, & inference.
|
||||
- # Sampling Distributions
|
||||
- The probability distribution of a **statistic** is called a **sampling** distribution.
|
||||
- Sampling distributions arise because samples vary.
|
||||
- Each random sample will have a different value of the statistic.
|
||||
- # The Central Limit Theorem #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:14:02.517Z
|
||||
card-last-score:: 1
|
||||
id:: 6356abee-cb6a-48c5-8f8b-72122b6099eb
|
||||
- The sampling distribution of *any* mean becomes more nearly Normal as the sample size grows.
|
||||
- Observations must be independent.
|
||||
- The shape of the population distribution doesn't matter.
|
||||
- What is the **Central Limit Theorem**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-22T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-21T13:06:03.899Z
|
||||
card-last-score:: 1
|
||||
- The **Central Limit Theorem** states that ==a sample means follow a Normal distribution centred on the population mean== with a standard deviation divided by the square root of the sample size.
|
||||
- $$\bar X \sim N (\mu, \frac{\sigma^2}{n})$$
|
||||
- The CLT depends crucially on the **assumption of independence**.
|
||||
- ## The Standard Error
|
||||
- The **Standard Error** is a measure of the variability in the sampling distribution (i.e., how do sample statistics vary about the unknown population parameter they are trying to estimate).
|
||||
- It describes the typical "error" or "uncertainty" associated with the estimate.
|
||||
- $$SE = \frac{\sigma}{\sqrt{n}}$$
|
||||
- ### Interval Estimation for $\mu$
|
||||
- Use the CLT to provide a range of values that will capture 95% of sample means.
|
||||
- In repeated sampling, 95% of intervals calculated in this manner will contain the true mean $\mu$.
|
||||
- $$\bar{x} \pm 1.96 \times \frac{\sigma}{\sqrt{n}}$$
|
||||
- # Confidence Intervals
|
||||
- The population mean $\mu$ is **fixed**.
|
||||
- The intervals from different samples are **random**.
|
||||
- From our single sample, we only observe one of the intervals.
|
||||
- Our interval may or may not contain the true mean.
|
||||
- If we had taken many samples, and calculated the 95% CI for each, 95% of them would include the true mean.
|
||||
- We say that we are "95% confident" that the interval contains the true mean.
|
||||
- A **point estimate** (i.e., a statistic) is a single plausible value for a parameter.
|
||||
- A point estimate is rarely perfect, usually there is some error in the estimate.
|
||||
- Instead of supplying just a point estimate of a parameter, a next logical step would be to provide a plausible range of values for the parameter.
|
||||
- To do this, an estimate of the precision of the sample statistic (i.e., the estimate) is needed.
|
||||
- # The t-distribution
|
||||
- In practice, we cannot directly calculate the standard error for $\bar x$ since we do not know the population standard deviation, $\sigma$.
|
||||
- We can use the sample standard deviation $s$ in place of $\sigma$ for computing the standard error of $\bar x$:
|
||||
- $$SE = \frac{\sigma}{\sqrt{n}} \approx \frac{s}{\sqrt{n}}$$
|
||||
- This strategy tends to work well when we have a lot of data and can estimate $\sigma$ using $s$ accurately. However, this estimate is less precise with smaller samples, and this leads to problems when using the normal distribution to model $\bar x$.
|
||||
- Enter a new distribution for inference calculations called the **t-distribution**.
|
||||
- A **t-distribution** has a bell shape, but its tails are thicker than the Normal Distribution's, meaning that observations are more likely to fall beyond two standard deviations from the mean than under the Normal Distribution.
|
||||
- The extra-thick tails of the t-distribution are exactly the correction needed to resolve the problem of using $s$ in place of $\sigma$ in the $SE$ calculation.
|
||||
- 
|
||||
- The t-distribution is always centred at zero and has a single parameter: **degrees of freedom**.
|
||||
- What are **degrees of freedom**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:21:05.697Z
|
||||
card-last-score:: 1
|
||||
- The **degrees of freedom** ($df$) describes the precise form of the bell-shaped t-distribution.
|
||||
- In general, $df = n -1$ where $n$ is the sample size.
|
||||
- That is, when we have more observation, the degrees of freedom will be larger and the t-distribution will look more the standard normal distribution.
|
||||
- When $df \geq 30$, the t-distribution is nearly indistinguishable from the normal distribution.
|
||||
- # The Bootstrap
|
||||
- We can quantify the variability of sample statistics using theory, e.g. ((6356abee-cb6a-48c5-8f8b-72122b6099eb)), or by **simulation** via **bootstrapping**.
|
||||
- ## Bootstrapping Scheme #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-22T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-21T13:10:41.508Z
|
||||
card-last-score:: 1
|
||||
- 1. Take a **bootstrap sample** - a random sample taken **with replacement** from the original sample, of the same size as the original sample.
|
||||
2. Calculate the bootstrap statistic - a statistic such as mean, median, proportiion, etc., computed on the bootstrap samples.
|
||||
3. Repeat steps 1. & 2. many times to create a bootstrap distribution - a distribution of bootstrap statistics.
|
||||
4. Calculate the bounds of the XX% confidence interval as the middle of the XX% of the bootstrap distribution.
|
||||
- # Theorem 9.2
|
||||
- If $\bar x$ is used as an estimate of $\mu$, we can be $100(1 - \alpha)%$ confident that the error will not exceed a specified amount $e$ when the sample size is
|
||||
- $$n = \left(\frac{z_\alpha / 2^\sigma}{e} \right)^2$$
|
||||
-
|
||||
100
year2/semester1/logseq-stuff/pages/Sampling.md
Normal file
100
year2/semester1/logseq-stuff/pages/Sampling.md
Normal file
@ -0,0 +1,100 @@
|
||||
- #[[ST2001 - Statistics in Data Science I]]
|
||||
- **Previous Topic:** [[Exploratory Data Analysis]]
|
||||
- **Next Topic:** [[Probability]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- What is a **Parameter**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-23T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-22T13:40:14.581Z
|
||||
card-last-score:: 1
|
||||
- A **parameter** is a single value summarising some feature or variable of interest in the population.
|
||||
- It is usually unknown.
|
||||
- What is **inference**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-11-22T23:24:34.466Z
|
||||
card-last-reviewed:: 2022-10-20T08:24:34.467Z
|
||||
card-last-score:: 5
|
||||
- **Inference** is the process of making decisions about a population based on information in a sample.
|
||||
- A consequence of **natural variation** is that two samples drawn form the same population will usually give different estimates of the population parameters.
|
||||
-
|
||||
- # Sampling
|
||||
collapsed:: true
|
||||
- What is **non-probabilistic sampling**? #card
|
||||
card-last-interval:: 29.04
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-12-13T20:02:44.059Z
|
||||
card-last-reviewed:: 2022-11-14T20:02:44.059Z
|
||||
card-last-score:: 5
|
||||
- **Non-probabilistic sampling** methods are techniques of obtaining a sample that is not chosen at random and may be subject to **sampling bias**.
|
||||
- ## Simple Random Sample
|
||||
- ### Difficulties:
|
||||
- Obtaining a sampling frame (list of all experimental units).
|
||||
- Possibly time consuming / expensive.
|
||||
- Minority groups, by chance, may not be represented in the sample.
|
||||
- ## Stratified Random Sampling #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T20:19:40.391Z
|
||||
card-last-score:: 1
|
||||
- 1. Split entire population into **homogeneous groups**, called **strata**.
|
||||
2. Take a Simple Random Sample from each stratum.
|
||||
- ### Stratified VS Simple Random Sample
|
||||
- Ensure representation from minority groups.
|
||||
- Estimates of the population parameters per strata may be of interest.
|
||||
- Possible reduction in cost per observation in the survey.
|
||||
- Increased accuracy as reduced sampling error (less variation within a stratum).
|
||||
-
|
||||
- ### Difficulties
|
||||
- Can you correctly allocate each individual to one & only one stratum?
|
||||
- Should every group receive equal weight?
|
||||
- What if some strata are more varied than others?
|
||||
- Take into account mean, variance, and cost to get "optimal allocation".
|
||||
- ## Cluster Sampling #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T20:18:48.138Z
|
||||
card-last-score:: 1
|
||||
- Instead of randomly choosing individuals, a Simple Random Sample of collection or groups of individuals is taken.
|
||||
- The population is broken up into regions or groups, usually a *natural partition*, called a **cluster**.
|
||||
- Internally heterogeneous, homogeneous between the clusters.
|
||||
- Clusters are assumed representation of the entire population.
|
||||
- Small number of clusters are selected at random.
|
||||
- Every individual within a cluster is observed.
|
||||
-
|
||||
- ### Cluster Over Stratified
|
||||
- Sampling frame not necessarily needed.
|
||||
- May be more practical and / or economical than Simple or Stratified Random Sampling.
|
||||
- Will be biased if the entire cluster is not sampled.
|
||||
- Careful if homogeneity within a cluster and heterogeneity between clusters as this can increase sample error.
|
||||
- **Note:** In stratified sampling, all strata are sampled, while in cluster sampling only some clusters are sampled.
|
||||
- # Studies & Experiments
|
||||
- ## Observational Studies & Experiments #card
|
||||
card-last-interval:: 4.14
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-27T15:18:34.757Z
|
||||
card-last-reviewed:: 2022-11-23T12:18:34.758Z
|
||||
card-last-score:: 5
|
||||
- In an **Observational Study**, data is collected only be *observing* what occurs.
|
||||
- E.g., surveys, historical records.
|
||||
- When researchers want to investigate **causal relationships**, it's best to conduct an experiment.
|
||||
- Usually there will be both an explanatory variable & a response variable.
|
||||
- Be wary of confounding variables.
|
||||
- ## Designed (Comparative) Study
|
||||
- An experiment allows us to prove a cause-and-effect relationship.
|
||||
- The experimenter must identify:
|
||||
- at least one **explanatory variable**, called a **factor** to manipulate.
|
||||
- at least one **response** variable to measure.
|
||||
- The experimenter must also control any other **nuisance factors** that could influence the response.
|
||||
- e.g., weather, day of the week.
|
||||
-
|
||||
12
year2/semester1/logseq-stuff/pages/Second Year University.md
Normal file
12
year2/semester1/logseq-stuff/pages/Second Year University.md
Normal file
@ -0,0 +1,12 @@
|
||||
- ## Semester 1
|
||||
- ### Timetable
|
||||
- 
|
||||
- ### Subjects
|
||||
- ### [[CT213 - Computer Systems & Organisation]]
|
||||
- ### [[ CT230 - Database Systems I]]
|
||||
- ### [[MA284 - Discrete Mathematics]]
|
||||
- ### [[CT216 - Software Engineering I]]
|
||||
- ### [[CT2106 - Object-Oriented Programming]]
|
||||
- ### [[ST2001 - Statistics in Data Science I]]
|
||||
- ### [[CT255 - Next Generation Technologies II]]
|
||||
-
|
||||
84
year2/semester1/logseq-stuff/pages/Social Engineering.md
Normal file
84
year2/semester1/logseq-stuff/pages/Social Engineering.md
Normal file
@ -0,0 +1,84 @@
|
||||
- #[[CT255 - Next Generation Technologies II]]
|
||||
- **Previous Topic:** [[Hash Cracking Using Rainbow Tables]]
|
||||
- **Next Topic:** [[DIffie-Hellman Key Exchange]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- What is **Social Engineering**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-18T20:10:38.202Z
|
||||
card-last-reviewed:: 2022-11-14T20:10:38.202Z
|
||||
card-last-score:: 5
|
||||
- **Social Engineering** is the use of deception to manipulate individuals into divulging confidential or personal information that may be used for fraudulent purposes.
|
||||
- What is **Phishing**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-18T20:09:18.304Z
|
||||
card-last-reviewed:: 2022-11-14T20:09:18.304Z
|
||||
card-last-score:: 5
|
||||
- **Phishing** usually involves sending malicious emails from supposedly trusted sources to as many people as possible, assuming a low response rate.
|
||||
- What is **Spear Phishing**? #card
|
||||
card-last-interval:: 14.2
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-12-05T17:10:15.178Z
|
||||
card-last-reviewed:: 2022-11-21T13:10:15.178Z
|
||||
card-last-score:: 5
|
||||
- In **Spear Phishing**, the perpetrator is disguised as a trusted individual, such as a boss, friend, or spouse.
|
||||
- What is **Whaling**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:08:34.227Z
|
||||
card-last-score:: 1
|
||||
- **Whaling** uses deceptive email messages targeting high-level decision makers within an organisation, such as CEOs or other executives.
|
||||
- Such individuals have access to highly valuable information, including trade secrets & passwords to administrative company accounts.
|
||||
- What is **Smishing**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-18T20:09:23.408Z
|
||||
card-last-reviewed:: 2022-11-14T20:09:23.409Z
|
||||
card-last-score:: 5
|
||||
- **Smishing** is portmanteau for "SMS Phishing", and it works much the same as phishing.
|
||||
- Users are tricked via an SMS text rather than from an email.
|
||||
- What is **Vishing**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-11-22T18:35:22.344Z
|
||||
card-last-reviewed:: 2022-11-18T18:35:22.345Z
|
||||
card-last-score:: 5
|
||||
- **Vishing**, also called **VOIP Phishing** is the voice counterpart to phishing.
|
||||
- For example, an email asks the user to make a phone call, or victims receive an unsolicited call.
|
||||
- What is **Pretexting**? #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T15:07:29.538Z
|
||||
card-last-reviewed:: 2022-11-14T20:07:29.538Z
|
||||
card-last-score:: 5
|
||||
- **Pretexting** is the practice of presenting oneself as someone else in order to obtain private information.
|
||||
- It is more than just creating a lie, in some cases, it can involve creating an entirely new identity and then using that identity to manipulate the receipt of information.
|
||||
- Pretexting goes hand-in-hand with vishing.
|
||||
- What is a **Watering Hole** attack? #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-17T15:08:14.319Z
|
||||
card-last-reviewed:: 2022-11-14T20:08:14.320Z
|
||||
card-last-score:: 5
|
||||
- A **Watering Hole** attack consists of injecting malicious code into public web pages of a website that the target visits.
|
||||
- The attackers typically compromise websites within a specific sector that are typically visited by specific individuals of interest for the attacks.
|
||||
- What is **Pharming**? #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-20T04:49:56.535Z
|
||||
card-last-reviewed:: 2022-11-17T09:49:56.536Z
|
||||
card-last-score:: 5
|
||||
- **Pharming** scams redirect users to a copy of a popular website where personal data such as usernames, passwords, & financial information can be "farmed" & collected for fraudulent use.
|
||||
-
|
||||
85
year2/semester1/logseq-stuff/pages/Software Processes.md
Normal file
85
year2/semester1/logseq-stuff/pages/Software Processes.md
Normal file
@ -0,0 +1,85 @@
|
||||
- #[[CT216 - Software Engineering I]]
|
||||
- **Previous Topic:** [[Cloud Computing]]
|
||||
- **Next Topic:** [[Introduction to Agile Methods]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # The Software Process
|
||||
- What is the **Software Process**?
|
||||
card-last-interval:: 12.36
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.7
|
||||
card-next-schedule:: 2022-10-19T18:39:50.523Z
|
||||
card-last-reviewed:: 2022-10-07T10:39:50.524Z
|
||||
card-last-score:: 5
|
||||
- The **Software Process** is a structured set of activities required to develop a software system.
|
||||
- What are the 4 fundamental activities in the Software Process? #card
|
||||
card-last-interval:: 3.45
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-18T02:27:50.775Z
|
||||
card-last-reviewed:: 2022-11-14T16:27:50.775Z
|
||||
card-last-score:: 5
|
||||
- **Specification**
|
||||
- Talk to the customer
|
||||
- Understand the problems
|
||||
- Talk to any relevant stakeholders
|
||||
- **Development**
|
||||
- Map out the tasks
|
||||
- Design the software
|
||||
- Develop the solution
|
||||
- **Validation**
|
||||
- Does the software meet the requirements?
|
||||
- Is it what the customer wanted?
|
||||
- **Evolution** (maintenance)
|
||||
- Modified to adapt
|
||||
- Changes in requirements
|
||||
- Customer & Market conditions
|
||||
- The foundation of software engineering is the **process**.
|
||||
- The **goal** of software engineering is to efficiently & predictably deliver a product that meets the requirements.
|
||||
-
|
||||
- # Software Engineering Practice
|
||||
- ### **1) Understand the problem** (*Communication & Analysis*)
|
||||
- Who are the stakeholders?
|
||||
- What are the unknowns?
|
||||
- ### **2) Plan the solution** (*Modelling & Software Design*)
|
||||
- Have we seen this problem before?
|
||||
- Has a similar problem already been solved?
|
||||
- Can sub-problems be found?
|
||||
- ### **3) Carry out the plan** (*Write the Code*)
|
||||
- Does the solution conform to the plan?
|
||||
- Has the code been reviewed for correctness?
|
||||
- ### **4) Examine the result** (*Test It*)
|
||||
- Is each component testable?
|
||||
- Does the solution produce results as defined originally?
|
||||
-
|
||||
- # General Software Engineering Questions
|
||||
- **What** is the problem to be solved?
|
||||
- Requirements definition
|
||||
- **What** are the characteristics of the software (system) used to solve the problem?
|
||||
- Analysis
|
||||
- **How** will the system be realised / constructed?
|
||||
- Design
|
||||
- **How** will the system be supported long-term?
|
||||
- Maintenance
|
||||
-
|
||||
- # Overview of Software Engineering
|
||||
- There are 3 generic phrases, regardless of paradigm:
|
||||
- **Definition** - a focus on the *What*
|
||||
- System Analysis, Software Project Planning, Requirements Analysis
|
||||
- **Development** - a focus on the *How*
|
||||
- Software Design, Coding, Software Testing
|
||||
- **Maintenance** - a focus on *Change*
|
||||
- Correction, Adaption, Enhancement
|
||||
-
|
||||
-
|
||||
- # Software Engineering Should...
|
||||
- Provide a clear statement of the project **mandate** & objectives
|
||||
- Create effective means of **communication**
|
||||
- Increase user **involvement** & **ownership**
|
||||
- Provide an effective **management framework** to support **productivity** & pragmatism
|
||||
- Establish **quality assurance** procedures
|
||||
- Provide sound resource **estimation** & **allocation** procedures
|
||||
- Ensure the **effectiveness** and **durability** of systems produced
|
||||
- Encourage the **re-usability** of code and / or solutions
|
||||
- Reduce the organisation's **vulnerability** to the loss of software development personnel
|
||||
- Reduce & support post implementation **maintenance** of system
|
||||
24
year2/semester1/logseq-stuff/pages/Sorting & Testing.md
Normal file
24
year2/semester1/logseq-stuff/pages/Sorting & Testing.md
Normal file
@ -0,0 +1,24 @@
|
||||
- #[[CT2106 - Object-Oriented Programming]]
|
||||
- **Previous Topic:** [[Static Fields & Exceptions]]
|
||||
- **Next Topic:** No Next Topic.
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Natural Ordering
|
||||
- When deciding on whether one object is greater than or less than another, we refer to the **natural ordering** of the object's class.
|
||||
- Natural ordering is the ordering imposed on an object when its class implements the **Comparable** interface.
|
||||
- ```java
|
||||
public interface Comparable<T>
|
||||
```
|
||||
- This interface imposes a total ordering on the objects of each class that implements it.
|
||||
- The class's `compareTo()` method is referred to as its **natural comparison method**.
|
||||
- Lists (and arrays) that implement this interface can be sorted automatically by `Collections.sort`.
|
||||
- Objects that implement this interface can be used as keys in a sorted map or as elements in a sorted set, without the need to specify a comparator.
|
||||
- The `<T>` in `Comparable<T>` means that we can specify in advance the types of the object that should be compared.
|
||||
- It returns a negative integer, zero, or a positive integer depending on whether the object is less than, equal to, or greater than the specified object.
|
||||
- # `assert`
|
||||
- Use `assert` to declare that a statement **must be true**.
|
||||
- If it is not true, your program will throw an `AssertionError` Exception.
|
||||
- You can use the `assert` statement as a quick way to test for expected output.
|
||||
- ```java
|
||||
assert(2==2);
|
||||
```
|
||||
33
year2/semester1/logseq-stuff/pages/Stars & Bars.md
Normal file
33
year2/semester1/logseq-stuff/pages/Stars & Bars.md
Normal file
@ -0,0 +1,33 @@
|
||||
- #[[MA284 - Discrete Mathematics]]
|
||||
- **Previous Topic:** [[Combinatorial Proofs]]
|
||||
- **Next Topic:** [[Advanced PIE, Derangements, & Counting Functions]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- Example: How many ways can you give 7 apples to 4 lecturers?
|
||||
- How many ways can you arrange 3 bars out of 7 stars and 3 bars (10)?
|
||||
- $$* | * | * | * * *$$
|
||||
- $$\binom{10}{3} = 120$$
|
||||
- # Multisets vs Sets
|
||||
- What is a **multiset**? #card
|
||||
card-last-interval:: 11.2
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-11-26T00:11:32.886Z
|
||||
card-last-reviewed:: 2022-11-14T20:11:32.887Z
|
||||
card-last-score:: 5
|
||||
- A **multiset** is a set of objects, where each object can appear more than once.
|
||||
- As with an ordinary set, order doesn't matter.
|
||||
- **Set:** Neither order nor repetition of elements matters.
|
||||
- e.g., $\{a,b,c\} = \{c,a,b\} = \{c,c,a,b,a,b,c\}$
|
||||
- **Multiset:** Order does not matter, but we count the **multiplicity** (number of times it occurs) of each element.
|
||||
- e.g., $\{a,b,c\} \neq \{c,c,a,b,a,b,c\}$, provided they are **multisets**.
|
||||
-
|
||||
- **Example:** How many **multisets** of size 4 can you form using numbers $\{1,2,3,4,5\}$?
|
||||
- Let's answer this using stars & bars.
|
||||
- e.g.:
|
||||
- $\{1,2,3,4\} = * | ** | |*|$
|
||||
- $\{5,3,3,1\} = *||**||*$
|
||||
- Each multiset can be represented using 8 boxes & 4 stars.
|
||||
- $$5^4 = 625$$
|
||||
-
|
||||
-
|
||||
@ -0,0 +1,95 @@
|
||||
- #[[CT2106 - Object-Oriented Programming]]
|
||||
- **Previous Topic:** [[Interfaces]]
|
||||
- **Next Topic:** [[Sorting & Testing]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Static Fields
|
||||
- What is a **static field**? #card
|
||||
card-last-interval:: 0.98
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-18T08:47:13.874Z
|
||||
card-last-reviewed:: 2022-11-17T09:47:13.874Z
|
||||
card-last-score:: 3
|
||||
- Up until now, the instance variables that we have used have had scope at object level.
|
||||
- A **static field** is a variable that has scope at the **class level**.
|
||||
- Typically, static fields are used to hold constant, non-changing data.
|
||||
- Often, they may be declared public & **final**.
|
||||
- This means that they can be accessed directly by other classes & objects but cannot be changed.
|
||||
- One uses static fields when one wants to declare a value/property that is unchanging or common to all objects of a class.
|
||||
- Generally, static variables are CAPITALISED.
|
||||
- When referencing a static field, we use the form `ClassName.<STATIC_VARIABLE_NAME>`.
|
||||
- e.g., `Cards.RANKS`.
|
||||
- # Exceptions
|
||||
- What is an **Exception**? #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-20T04:45:26.574Z
|
||||
card-last-reviewed:: 2022-11-17T09:45:26.575Z
|
||||
card-last-score:: 5
|
||||
- An **exception** is an "exceptional event" - one that may lead to a serious error in your program if not handled appropriately.
|
||||
- An exception is generated only when the program runs - hence it is known as a **runtime error**.
|
||||
- Very often, the error (& the exception generated), occur when the program is asked to do something that is impossible for it to do.
|
||||
- In Java, each exception is represented by an **Exception Object**.
|
||||
- ## Programming for Exceptions - Throwing Exceptions
|
||||
- As the programmer, it is your responsibility to anticipate the situations in which your program will fail.
|
||||
- You have to write code to manage any exceptional events that may occur withing your program.
|
||||
- When a program generates an Exception object, it is said to *throw an Exception*.
|
||||
- When an Exception is thrown, the program must have code in place to **catch it** - otherwise the program will terminate.
|
||||
- ### Throwing an Exception #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T09:45:39.752Z
|
||||
card-last-score:: 1
|
||||
- 1. Detecting an error.
|
||||
2. Creating an Exception object.
|
||||
3. Passing the Exception object to the Java Runtime Environment (JRE) Exception Handling Procedures.
|
||||
- This also means that the execution of the method does not complete.
|
||||
- 4. The JRE then looks for a part of your program to take responsibility for this error.
|
||||
- In other words, your program should also have code ready to **catch** the error.
|
||||
- ### `throws` #card
|
||||
card-last-interval:: 0.98
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-18T08:46:16.012Z
|
||||
card-last-reviewed:: 2022-11-17T09:46:16.013Z
|
||||
card-last-score:: 3
|
||||
- When you want a method to throw an Exception, you add the keyword `throws` and the Exception type to the method signature.
|
||||
- `public Card (int suit, int rank) throws IllegalArgumentException`
|
||||
- This tells any code that wants to call the constructor method that it may throw an `IllegalArgumentException`, which indicates that a method has been passed an illegal or inappropriate argument.
|
||||
- To throw an exception, you use the `throw` keyword.
|
||||
- ```java
|
||||
if (rank < 1 || rank > Card.RANKS.length -1) {
|
||||
throw new IllegalArgumentException("Incorrect rank value: " + rank);
|
||||
}
|
||||
```
|
||||
- ### Graceful Recovery
|
||||
- If an exception is not caught, the JRE will terminate the program.
|
||||
- This is a drastic step.
|
||||
- In most cases, you will want your program to recover gracefully from an exception & carry on.
|
||||
- This involves **catching** the Exception that has been generated.
|
||||
- ### `try` / `catch`
|
||||
- If you want the program to recover from the Exception, you have to catch & handle it.
|
||||
- This means using a `try`/`catch` expression.
|
||||
- `try`: Try to execute this piece of code.
|
||||
- If it executes without throwing an exception, fine - there is no need for the `catch` clause to be executed.
|
||||
- `catch`: If an exception has been thrown, then execute this piece of recovery code to **handle** the Exception (very often just an error message).
|
||||
- ```java
|
||||
try {
|
||||
// call the code that may call an Exception
|
||||
} catch(/*TheExceptionClass variable*/) {
|
||||
// how you want to handle the error
|
||||
}
|
||||
```
|
||||
- ## Some Common Unchecked Excpetions
|
||||
- | **Name** | **Description** |
|
||||
| `NullPointerException` | Thrown when attempting to access an object with a reference variable whose current value is `null` |
|
||||
| `ArrayIndexOutOfBound` | Thrown when attempting to access an array with an invalid index value (either negative or beyond the length of the array). |
|
||||
| `IllegalArgumentException` | Thrown when a method receives an argument that is not formatted how the method expects. |
|
||||
| `IllegalStateException` | Thrown when the state of the environment doesn't match the operation being attempted, e.g., using a Scanner that has been closed. |
|
||||
| `NumberFormatException` | Thrown when a method that converts a String to a number receives a String that it cannot convert. |
|
||||
| `ArithmeticException` | Arithmetic error, such as divide-by-zero.|
|
||||
-
|
||||
@ -0,0 +1,404 @@
|
||||
- #[[CT213 - Computer Systems & Organisation]]
|
||||
- **Previous Topic:** [[Programming Models]]
|
||||
- **Next Topic:** [[Process Management]]
|
||||
- **Relevant Slides:** 
|
||||
id:: 6326480d-27b6-4d5f-a1d4-5c446ceef351
|
||||
-
|
||||
- # Types of Software
|
||||
- What is **Application Software**? #card
|
||||
card-last-interval:: 23.43
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-12-08T06:02:33.036Z
|
||||
card-last-reviewed:: 2022-11-14T20:02:33.036Z
|
||||
card-last-score:: 5
|
||||
- **Application Software** is a computer program designed to perform a group of coordinated functions for the benefit of the user.
|
||||
- It is designed solve a specific problem.
|
||||
- What is **System Software**? #card
|
||||
card-last-interval:: 31.05
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-12-15T21:10:52.302Z
|
||||
card-last-reviewed:: 2022-11-14T20:10:52.302Z
|
||||
card-last-score:: 3
|
||||
- **System Software** is a program dedicated to ^^managing the computer.^^
|
||||
- It provides a platform to other software & a general programming environment.
|
||||
- There are two main types of system software:
|
||||
- **Operating System**
|
||||
- **Utility Software**
|
||||
- What is the **Operating System (OS)**? #card
|
||||
card-last-interval:: 29.99
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-12-14T19:04:40.695Z
|
||||
card-last-reviewed:: 2022-11-14T20:04:40.696Z
|
||||
card-last-score:: 5
|
||||
- The **Operating System** provides functions used by the **application software**.
|
||||
- It provides the mechanisms for application software to **share** the hardware in an orderly fashion to:
|
||||
- **Increase the overall performance** by allowing different application software to use different parts of the computer at the same time.
|
||||
- **Decrease the time to execute** a collection of programs and, again, increase the overall performance
|
||||
- The OS interacts directly with the hardware to provide an interface to other system software and with application software whenever the application software wants to use the system's resources.
|
||||
- The OS is **application-domain independent**, provides **resource abstraction**, and provides **resources sharing** through strict resource management policies.
|
||||
- What is **Utility Software**? #card
|
||||
card-last-interval:: 29.99
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-12-14T19:04:31.529Z
|
||||
card-last-reviewed:: 2022-11-14T20:04:31.529Z
|
||||
card-last-score:: 5
|
||||
- **Utility Software** is system software designed to help **analyse**, **configure**, **optimise**, or **maintain** a computer.
|
||||
- Examples include data compression, disk cleaners, disk defragmentation, registry cleaners, or system monitors.
|
||||
-
|
||||
- # Resources
|
||||
collapsed:: true
|
||||
- What are **Resources**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:28:34.225Z
|
||||
card-last-score:: 1
|
||||
- Different hardware components that a program may access are referred to as **resources**.
|
||||
- Any particular resource, such as a hard disk, has a generic interface that defines how the programmer can make the resource perform a desired operation.
|
||||
- What is **Resource Abstraction**? #card
|
||||
card-last-interval:: 19.01
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.18
|
||||
card-next-schedule:: 2022-12-03T20:01:30.272Z
|
||||
card-last-reviewed:: 2022-11-14T20:01:30.272Z
|
||||
card-last-score:: 5
|
||||
- Resource Abstraction is done by providing an ^^abstract model of the operation of the hardware components.^^
|
||||
- Abstraction generalises the hardware behaviour but ^^restricts its flexibility.^^
|
||||
- With abstraction, certain operations become easy to perform, while others may become ^^impossible^^, such as specific hardware control.
|
||||
- An abstraction can be made to be much simpler than the actual resource interface.
|
||||
- Simpler resources can be abstracted to a ^^common abstract resource interface.^^
|
||||
- ## Resource Sharing
|
||||
- Abstract & physical resources can be shared among a set of concurrently executing programs.
|
||||
- What is **Space Multiplex Sharing**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-19T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-18T18:33:28.408Z
|
||||
card-last-score:: 1
|
||||
- **Space Multiplex Sharing** is when resources can be divided into two or more **distinct units** of the resource that can be used independently.
|
||||
- E.g., Memory, HDD.
|
||||
- What is **Time Multiplex Sharing**? #card
|
||||
card-last-interval:: 0.79
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T10:26:36.497Z
|
||||
card-last-reviewed:: 2022-11-14T16:26:36.497Z
|
||||
card-last-score:: 3
|
||||
- **Time Multiplex Sharing** is when a process is allocated ^^exclusive control of an entire resource for a short period of time^^ (not **spatially divisible**).
|
||||
- E.g., the Processor Resource.
|
||||
-
|
||||
- # Operating Systems
|
||||
- ## OS Organisation
|
||||
collapsed:: true
|
||||
- 
|
||||
- What is the **Process & Resource Manager**? #card
|
||||
card-last-interval:: 0.79
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-15T10:26:53.305Z
|
||||
card-last-reviewed:: 2022-11-14T16:26:53.305Z
|
||||
card-last-score:: 3
|
||||
- The **Process & Resource Manager** handles ^^resource allocation.^^
|
||||
- It uses the abstraction provided by the other managers.
|
||||
- What is the **Memory Manager**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-22T18:34:34.745Z
|
||||
card-last-reviewed:: 2022-11-18T18:34:34.745Z
|
||||
card-last-score:: 3
|
||||
- Besides other functions, the **Memory Manager** is in charge of the ^^implementation of the **virtual memory**.^^
|
||||
- It is classically a separate part of the operating system.
|
||||
- What does the **File Manager** do? #card
|
||||
card-last-score:: 1
|
||||
card-repeats:: 1
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-interval:: -1
|
||||
card-ease-factor:: 2.6
|
||||
card-last-reviewed:: 2022-11-14T20:14:20.814Z
|
||||
- The **File Manager** abstracts device I/O operations into a relatively simple operation.
|
||||
- What is the **Device Manager**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:43:01.202Z
|
||||
card-last-score:: 1
|
||||
- The **Device Manager** handles the details of ^^reading & writing to the physical devices.^^
|
||||
- The Device Manager is implemented within the **device driver**.
|
||||
- ## OS Evolution
|
||||
collapsed:: true
|
||||
- ### Computers with no OS
|
||||
collapsed:: true
|
||||
- Programming in machine language.
|
||||
- Lack of I/O devices.
|
||||
- ### Rudimentary OS
|
||||
collapsed:: true
|
||||
- Programming done in Assembly.
|
||||
:LOGBOOK:
|
||||
CLOCK: [2022-09-18 Sun 00:46:32]
|
||||
:END:
|
||||
- Some basic I/O devices.
|
||||
- Some I/O control modules - assembler, debugger, loader, linker.
|
||||
- ### Batch Processing System
|
||||
collapsed:: true
|
||||
- Service a collection of **jobs**, called a **batch**, from a **queue**.
|
||||
- What is a **Job**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T20:19:14.338Z
|
||||
card-last-score:: 1
|
||||
- A **Job** is a predefined sequence of commands, programs, and data combined into a single unit.
|
||||
- Job Control Language and monitor batch (Interpreter for JCL).
|
||||
- The user doesn't interact with programs while they operate.
|
||||
- Process Scheduling: **FIFO**.
|
||||
- Memory is divided into two parts: **system memory** and **program memory**.
|
||||
- No special jobs for I/O management, as a job has exclusive access to the I/O devices.
|
||||
- File management.
|
||||
- ### Operating Systems that use **Multiprogramming**
|
||||
collapsed:: true
|
||||
- What is **Multiprogramming**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-21T20:25:39.838Z
|
||||
card-last-reviewed:: 2022-11-17T20:25:39.838Z
|
||||
card-last-score:: 3
|
||||
- **Mulitprogramming** is the technique of loading multiple programs into **space-multiplexed memory** while **time-mulitplexing** the processor.
|
||||
- **Timesharing Systems**, **Real-Time Operating Systems**, and **Distributed Operating Systems** all use multiprogramming.
|
||||
-
|
||||
- #### Common Features of Multiprogramming Systems #card
|
||||
card-last-interval:: 15.05
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 1.94
|
||||
card-next-schedule:: 2022-11-26T12:30:04.351Z
|
||||
card-last-reviewed:: 2022-11-11T11:30:04.352Z
|
||||
card-last-score:: 3
|
||||
- **Multitasking:** multiple processes sharing machine resources.
|
||||
- **Hardware Support** for memory protection & I/O devices.
|
||||
- **Multi-user** & **multi-access** support (through time-sharing mechanisms).
|
||||
- Optional support for **real-time operations** (based on efficient usage of multitasking support).
|
||||
- Interactive user interface.
|
||||
-
|
||||
- #### Time Sharing Systems #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-18T20:14:17.489Z
|
||||
card-last-reviewed:: 2022-11-14T20:14:17.489Z
|
||||
card-last-score:: 3
|
||||
- **Time Sharing Systems** have **multiprogramming** & **multi-user** support.
|
||||
- They use **time slice** (round robin) processor scheduling.
|
||||
- They have protection & inter-process communication support for Memory Management.
|
||||
- They have support for the protection & sharing of I/O between users.
|
||||
- The File Management has protection support & sharing support between users.
|
||||
- 
|
||||
- #### Real-Time Operating Systems #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T20:16:00.838Z
|
||||
card-last-score:: 1
|
||||
- **Real-Time Operating Systems** are used whenever a large number of ^^critical external events^^ have to be treated in a short or ^^limited time interval^^ .
|
||||
- They have support for multiprogramming / multi-tasking.
|
||||
- The main goal of Real-Time Operating Systems is the **minimisation of response time** to service the external events.
|
||||
-
|
||||
- Processor Scheduling: Priority-based pre-emptive.
|
||||
- Memory Management:
|
||||
- Concurrent processes are loaded into the memory.
|
||||
- Support for protection & inter-process communication.
|
||||
- I/O Management:
|
||||
- Critical in time.
|
||||
- Processes dealing with I/O are directly connected to the **interrupt vectors** (for handling interrupt requests).
|
||||
- File Management:
|
||||
- File Management may not be present.
|
||||
- If it exists, it should comply with the requirements for **Time Sharing** & **Real-Time** systems.
|
||||
- 
|
||||
- #### Distributed Operating Systems #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.22
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:04:11.371Z
|
||||
card-last-score:: 1
|
||||
- Multiprogramming induces a ^^strong **centralisation** tendency.^^
|
||||
- **Distributed Operating Systems** aim for ***decentralisation***.
|
||||
- Distributed Operating Systems are based on computer **network** technologies, with different communication & synchronisation protocols.
|
||||
- **Client-Server** application architecture.
|
||||
- **Security** & **Protection** are the primary concerns.
|
||||
- {:height 313, :width 318}
|
||||
- ### Modern Operating Systems
|
||||
collapsed:: true
|
||||
- **Modern Operating Systems** take attributes from Batch, Timesharing, Real-Time, & Distributed Operating Systems.
|
||||
- Batch OS -> Constant load on the processor on low-priority tasks.
|
||||
- Timesharing OS -> Interactive processes are treated on a time share.
|
||||
- Real-Time OS-> Critical Processes (i.e., network drivers) are tread according to real-time constraints.
|
||||
- Distributed OS -> Client-Server model protocols.
|
||||
-
|
||||
- ## OS Implementation Considerations
|
||||
collapsed:: true
|
||||
- ### Monolithic Operating System #card
|
||||
collapsed:: true
|
||||
card-last-interval:: 0.85
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-18T15:50:22.513Z
|
||||
card-last-reviewed:: 2022-11-17T19:50:22.513Z
|
||||
card-last-score:: 3
|
||||
- **Monolithic Operating Systems** try to achieve the functional requirements by ^^executing all the code in the same address space^^ to increase the performance of the system.
|
||||
- They are often too complex to manage.
|
||||
- ### Hierarchical Operating System #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T20:18:29.505Z
|
||||
card-last-score:: 1
|
||||
- **Hierarchical Operating Systems** run most of their services in the **user space**, aiming to improve maintainability & modularity of the codebase.
|
||||
- Suitable for Object-Oriented Programming, the levels are very well-defined.
|
||||
-
|
||||
- **Multiprogramming:** The illusion that multiple programs are running simultaneously.
|
||||
- **Protection:** Access to shared system resources.
|
||||
- **Processor Modes:** Different privilege levels.
|
||||
- Restrictions on the operations that can be run.
|
||||
- **Kernels:** Complete control over everything in the system (i.e., supervisor).
|
||||
- ### Multi-Programming #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:23:25.857Z
|
||||
card-last-score:: 1
|
||||
- **Multiprogramming** is a technique that allows the system to present the illusion that multiple programs are running on the computer simultaneously.
|
||||
- It is achieved by ^^switching rapidly between programs.^^
|
||||
- Each program is allowed to execute for a fixed amount of time called a **timeslice**.
|
||||
- When a program timeslice ends, the OS stops it, removes it, and gives another program control over the processor - this is a **context switch**.
|
||||
- To do a context switch, the OS copies the contents of the current program register file into memory, restores the contents of the next program's register file into the processor, and starts executing the next program.
|
||||
- From the program POV, they can't tell that a context switch has been performed.
|
||||
- **Protection** between multi-programmed programs is very important.
|
||||
- Many multiprogrammed computers are **multi-user** - they allow multiple persons to be logged on at a time.
|
||||
- Besides Protection, data **privacy** is also important.
|
||||
- ### Protection #card
|
||||
card-last-interval:: 7.44
|
||||
card-repeats:: 3
|
||||
card-ease-factor:: 2.08
|
||||
card-next-schedule:: 2022-11-22T02:35:46.684Z
|
||||
card-last-reviewed:: 2022-11-14T16:35:46.685Z
|
||||
card-last-score:: 3
|
||||
- The result of any program running on a multiprogrammed computer ^^must be the same^^ as if the program was the only program running on the computer.
|
||||
- Programs ^^must not be able to access other program's data^^ and must be confident that their data will not be modified by other programs.
|
||||
- Programs ^^must not interfere with other program's use of I/O devices.^^
|
||||
- **Protection** is achieved by having the ^^OS have full control over the resources of the system^^ (processor, memory, & I/O devices).
|
||||
-
|
||||
- **Virtual Memory** is one of the techniques used to achieve protection between programs.
|
||||
- Each program operates as if it were the only program on the computer, occupying a full set of the address space as in its virtual space.
|
||||
- The OS is **translating** memory addresses that the program references into physical addresses used by the memory system.
|
||||
- As long two program's addresses are not translated to the same address space, programs can be written as if they were the only ones running on the machine.
|
||||
- ### Processor Modes
|
||||
collapsed:: true
|
||||
- What are **Processor Modes**? #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-11-25T13:06:30.927Z
|
||||
card-last-reviewed:: 2022-11-21T13:06:30.928Z
|
||||
card-last-score:: 5
|
||||
- **Processor Modes** are operating modes for the CPU that ^^place restrictions^^ on the operations that can be performed by the currently running process.
|
||||
- Hardware supported CPU modes help the OS to ^^enforce rules^^ that would prevent viruses, spyware, & similar malware from running.
|
||||
- Only very specific & limited "kernel" code would run unrestricted.
|
||||
- Any other software (including portions of the OS), would run restricted and would have to ask the "kernel" for permission to modify anything that could compromise the system.
|
||||
- Multiple mode levels could be designed.
|
||||
-
|
||||
- The **mode bit** is used to define the **execution capability** of a program on a processor.
|
||||
- The mode bit may be logically extended to define areas of memory to be used when the processor is in supervisor mode, versus when it is in user mode.
|
||||
- #### Supervisor Mode #card
|
||||
card-last-interval:: 31.05
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-12-15T21:10:41.635Z
|
||||
card-last-reviewed:: 2022-11-14T20:10:41.635Z
|
||||
card-last-score:: 3
|
||||
- The processor can execute ^^any instruction.^^
|
||||
- Instructions that can be executed only in supervisor mode are called *supervisor*, *privileged*, or *protected* instructions. (E.g., I/O instructions).
|
||||
- The executing process has access on both memory spaces.
|
||||
- #### User Mode #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.08
|
||||
card-next-schedule:: 2022-11-26T13:41:27.100Z
|
||||
card-last-reviewed:: 2022-11-22T13:41:27.101Z
|
||||
card-last-score:: 3
|
||||
- The processor can execute only a ^^subset of the instruction set.^^
|
||||
- The executing process has access only to the ^^user space.^^
|
||||
- Some processors do not differentiate between protected mode & user mode.
|
||||
-
|
||||
- #### Privileged Mode
|
||||
- To ensure that the OS is the only one that can control the physical resources, it executes in **Privileged Mode**.
|
||||
- The OS is also responsible for **Low-Level UI**
|
||||
- When keys are pressed, the OS is responsible to determine which program should receive the input.
|
||||
- When a program wants to display some output, the user program executes some system call that displays the data.
|
||||
- User programs execute in **User Mode**
|
||||
- When User Mode programs want to execute something that requires privileged rights, it sends a request to the OS, known as a **system call**, that asks the OS to do the operation for them.
|
||||
-
|
||||
-
|
||||
- ## Kernel
|
||||
collapsed:: true
|
||||
- What is the **Kernel**? #card
|
||||
card-last-interval:: 31.36
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-12-16T04:09:50.119Z
|
||||
card-last-reviewed:: 2022-11-14T20:09:50.120Z
|
||||
card-last-score:: 5
|
||||
- The **Kernel** (sometimes called the **nucleus**) is the part of the operating system that executes in supervisor mode.
|
||||
- The Kernel operates as **trusted** software
|
||||
- It implements protection mechanisms that cannot be changed through the actions of un-trusted software executing in user mode.
|
||||
- It provides the lowest level abstraction layer for resources (memory, processors, and IO devices).
|
||||
- A fundamental design decision: Should a given function of the OS be incorporated in the kernel or not?
|
||||
- Protection issues.
|
||||
- Performance issues.
|
||||
- ## Methods for Requesting System Services
|
||||
- 1. Through a **Command Line Interface**
|
||||
- By calling a specific command.
|
||||
- Using a command interpreter known as a **shell**.
|
||||
- #### Command Execution Mechanism #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:27:04.739Z
|
||||
card-last-score:: 1
|
||||
- A key pressed by the user generates a hardware interrupt.
|
||||
- A specialised module of the OS reads the keyed character and stores it in a special command line buffer.
|
||||
- There are special characters (e.g., to edit the command line) that are not stored in the command line buffer.
|
||||
- Control is taken by the shell (command interpreter) when an **end of line** is detected.
|
||||
- The command is **analysed** (with error or success).
|
||||
- If successful, the shell decides if it is an **internal** or **external** command (for another module).
|
||||
- If **internal:** the shell tries the execution, which can end successfully or with an error.
|
||||
- If **external:** the shell looks for the corresponding executable file & executes it with the detected parameters from the previous phrase.
|
||||
- 2. From user processes requesting services from the OS
|
||||
- #### System Call
|
||||
- The parameters of the call are passed according to the **specific OS convention** & hardware architecture.
|
||||
- Switch to **protected (supervisor) mode** using a specific mechanism.
|
||||
- E.g., software interrupt, trap, special instruction of type "call supervisor".
|
||||
- This mechanism is different to a normal call.
|
||||
- A **special module** takes over, that will analyse the parameters & their access rights.
|
||||
- This module can reject the system call.
|
||||
- If accepted, the **corresponding routine** from the OS is executed and the **result** is returned to the user.
|
||||
- Upon return, the user mode is returned.
|
||||
- #### Message
|
||||
- The user process ^^constructs a **message** (A) that describes a desired service.^^
|
||||
- It uses the **send** function to pass the message to a trusted operating system process.
|
||||
- The send function checks the message, switches the processor to **protected mode**, & then delivers the message to the process that implements the target function.
|
||||
- Meanwhile, the user waits for a result with a **message receive** operation.
|
||||
- When the kernel finishes processing the request, it sends a message (B) back to the user process.
|
||||
-
|
||||
115
year2/semester1/logseq-stuff/pages/The Normal Distribution.md
Normal file
115
year2/semester1/logseq-stuff/pages/The Normal Distribution.md
Normal file
@ -0,0 +1,115 @@
|
||||
- #[[ST2001 - Statistics in Data Science I]]
|
||||
- **Previous Topic:** [[Discrete Probability Distributions: Binomial & Poisson]]
|
||||
- **Next Topic:** [[Sampling Distributions & Confidence Intervals]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- What is a **Normal Distribution**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:07:27.457Z
|
||||
card-last-score:: 1
|
||||
id:: 63510f7d-d646-41b8-82d7-8634c840892e
|
||||
- A random variable $X$ with probability distribution function
|
||||
- $$f(x) = \frac{1}{\sqrt{2\pi\sigma^2}}e^{\frac{(x - \mu)^2}{2 \sigma^2}} -\infty < x < \infty$$
|
||||
- is a **normal random variable** with parameters $\mu$ & $\sigma$ (where $\infty < \mu < \infty$ and $\sigma > 0$) where $\mu$ is the mean and $\sigma$ is the standard deviation.
|
||||
- Write $X \sim N(\mu, \sigma^2)$.
|
||||
- 
|
||||
- # Features of the Normal Distribution #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:09:00.438Z
|
||||
card-last-score:: 1
|
||||
- Also called the **Gaussian Distribution**.
|
||||
- The **pdf** (probability density function) is a **bell-shaped curve**.
|
||||
- The distribution of many types of observations can be approximated by a Normal Distribution.
|
||||
- Single mode.
|
||||
- Symettric.
|
||||
- Model for continuous measurements.
|
||||
- # Examples of Normal Distributions
|
||||
collapsed:: true
|
||||
- ## Normal Curves with $\mu_i = \mu_2$ and $\sigma_1 < \sigma_2$
|
||||
- 
|
||||
- ## Normal Curves with $\mu_1 < \mu_2$ and $\sigma_1 < \sigma_2$
|
||||
- 
|
||||
-
|
||||
- # Empirical Rule for a Normal Distribution #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:08:32.008Z
|
||||
card-last-score:: 1
|
||||
- For any normal random variable:
|
||||
- $$P(\mu - \sigma < X < \mu + \sigma) = 0.6827$$
|
||||
- $$P(\mu - 2\sigma < X < \mu + 2\sigma) = 0.9545$$
|
||||
- $$P(\mu - 3\sigma < X < \mu + 3\sigma) = 0.9973$$
|
||||
- {:height 251, :width 426}
|
||||
- ## The 68-95-99.7 Rule
|
||||
- Normal models give us an idea of how extreme a value is by telling us how likely it is to find one that far from the mean.
|
||||
- In a normal model:
|
||||
- About 68% of the values within **one standard deviation** from the mean.
|
||||
- About 95% of the values fall within **two standard deviations** of the mean.
|
||||
- About 99.7% of the values fall within **three standard deviations** of the mean.
|
||||
-
|
||||
- # Areas Under a Normal Curve #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:05:26.550Z
|
||||
card-last-score:: 1
|
||||
- To calculate a probability in a range under a normal distribution.
|
||||
- $$P(x_1 < X < x_2) = \int_{x_1}^{x_2} \frac{1}{\sqrt{2\pi\sigma^2}}e^{\frac{(x - \mu)^2)}{2\sigma^2}}dx$$
|
||||
- For example. $P(x_1 < X < x_2) =$ area of the shaded region.
|
||||
- {:height 225, :width 444}
|
||||
-
|
||||
- # z-scores
|
||||
- What is a **z-score**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-16T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-15T18:42:43.077Z
|
||||
card-last-score:: 1
|
||||
- A **z-score** reports the number of standard deviations from the mean.
|
||||
- For example, a z-score of 2 indicates that the observation is two standard deviations above the mean.
|
||||
- ## Converting to z-scores #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T20:08:12.257Z
|
||||
card-last-score:: 1
|
||||
- To convert a random variable $X$ which follows a $N(\mu, \sigma^2)$ to a random variable $Z$ that follows a standard normal $N(0,1)$, calculate $Z$ as:
|
||||
- $$Z = \frac{X - \mu}{\sigma}$$
|
||||
- Convert $X \sim N(100,100)$ to a random variable $Z$ such that $Z \sim N(0,1)$.
|
||||
-
|
||||
- # Cumulative Distribution Functions
|
||||
collapsed:: true
|
||||
- How is the **cumulative distribution function** of a standard normal random variable denoted? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-19T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-18T18:34:54.021Z
|
||||
card-last-score:: 1
|
||||
- The **cumulative distribution function** of a standard normal random variable is denoted as $\Phi(z) = P(Z \leq z)$
|
||||
-
|
||||
- # Normal Approximation to the Poisson
|
||||
- If $X$ is a Poisson random variable with $E(X) + \lambda$ and $V(X) = \lambda$,
|
||||
- $$Z = \frac{X-\lambda}{\sqrt{\lambda}}$$
|
||||
- The approximation is good for $\lambda \geq 5$.
|
||||
-
|
||||
- # Continuity Correction
|
||||
- Using the Normal Distribution to approximate a discrete distribution (e.g., Binomial) we need to take into account the fact that the Normal Distribution is **continuous**.
|
||||
- | $\textbf{Discrete}$ | | $\textbf{Continuous}$ |
|
||||
| $P(X > k)$ | $\rightarrow$ | $P(X > k + \frac 1 2)$ |
|
||||
| $P(X \geq k)$ | $\rightarrow$ | $P(X > k - \frac 1 2)$ |
|
||||
| $P(X < k)$ | $\rightarrow$ | $P(X < k - \frac 1 2)$ |
|
||||
| $P(X \leq k)$ | $\rightarrow$ | $P(X < k + \frac 1 2)$ |
|
||||
| $P(k_1 < X < k_2$ | $\rightarrow$ | $P(k_1 + \frac 1 2 < X < k_2 - \frac 1 2)$ |
|
||||
| $P(k_1 \leq X \leq k_2)$ | $\rightarrow$ | $k_1 - \frac 1 2 < X < k_2 + \frac 1 2$ |
|
||||
204
year2/semester1/logseq-stuff/pages/The Relational Model.md
Normal file
204
year2/semester1/logseq-stuff/pages/The Relational Model.md
Normal file
@ -0,0 +1,204 @@
|
||||
- #[[CT230 - Database Systems I]]
|
||||
- **Previous Topic:** [[Database System Introduction]]
|
||||
- **Next Topic:** [[Introduction to SQL & DDL]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- Why learn about relational DBMS?
|
||||
- 90% of industry / enterprise / business applications are still relational DBMS or relational DBMS with extensions (e.g., OO Relational).
|
||||
- The majority of industry applications require:
|
||||
- **Correctness**
|
||||
- **Completeness**
|
||||
- **Efficiency** (Complex optimisation techniques & complex indexing structures).
|
||||
- Relational DBMS provide this.
|
||||
-
|
||||
- What is the **Relational Data Model**? #card
|
||||
card-last-interval:: 21.53
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-12-06T08:01:57.584Z
|
||||
card-last-reviewed:: 2022-11-14T20:01:57.584Z
|
||||
card-last-score:: 3
|
||||
- The **Relational Data Model** consists of collections of **relations** (often called *tables*) where each relation contains **tuples** (*rows*) and **attributes** (*columns*).
|
||||
- The relational data model is closely related to the file system model.
|
||||
- Relations are named.
|
||||
- What is a **relation**? #card
|
||||
card-last-interval:: 31.36
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-11-20T16:24:50.257Z
|
||||
card-last-reviewed:: 2022-10-20T08:24:50.257Z
|
||||
card-last-score:: 5
|
||||
- A table.
|
||||
- What are **attributes**? #card
|
||||
card-last-interval:: 100.92
|
||||
card-repeats:: 5
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2023-02-23T18:22:23.155Z
|
||||
card-last-reviewed:: 2022-11-14T20:22:23.156Z
|
||||
card-last-score:: 5
|
||||
- **Attributes** are columns.
|
||||
- Columns / attributes are ^^almost always fixed^^ and do not change.
|
||||
- What are **tuples**? #card
|
||||
card-last-interval:: 29.26
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T22:48:34.835Z
|
||||
card-last-reviewed:: 2022-11-14T16:48:34.835Z
|
||||
card-last-score:: 5
|
||||
- **Tuples** are rows.
|
||||
- Rows contain the data.
|
||||
- There is a variable number of rows.
|
||||
- What is the **cardinality** of a relation? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.8
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:51:27.460Z
|
||||
card-last-score:: 1
|
||||
- The ^^number of tuples in a relation^^ is referred to as the **cardinality** of that relation.
|
||||
-
|
||||
- ## Attributes / Columns
|
||||
- Each attribute belongs to **one** *domain* and has a single:
|
||||
- Name
|
||||
- Data Type
|
||||
- Format
|
||||
- ### Naming Columns #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-11-17T15:34:15.662Z
|
||||
card-last-reviewed:: 2022-10-20T08:34:15.663Z
|
||||
card-last-score:: 5
|
||||
- Case is **not** significant in SQL.
|
||||
- No spaces allowed.
|
||||
- No reserved keywords (e.g., date) allowed.
|
||||
- Choose meaningful variable names.
|
||||
- If given the names of relations and attributes, use ^^exactly^^ what you are given.
|
||||
- ### Data Types
|
||||
- You must ^^specify the **data type**^^ of all attributes (columns) defined.
|
||||
- Common data types used include:
|
||||
- **varchar(N)**, where **N** is an integer - used for strings.
|
||||
- date
|
||||
- int
|
||||
- double
|
||||
- You often must specify the size - especially for integers and strings
|
||||
- 
|
||||
- ### NULL
|
||||
- What are **null-valued attributes**? #card
|
||||
card-last-interval:: 29.26
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T22:48:31.350Z
|
||||
card-last-reviewed:: 2022-11-14T16:48:31.350Z
|
||||
card-last-score:: 5
|
||||
- **Null-valued attributes** are what occurs when the values of some attribute within a particular tuple may be unknown or may not apply to that particular tuple. A **null value** is used for these cases.
|
||||
- **NULL** is a special marker used in SQL to denote the ^^absence of a value.^^
|
||||
- In some cases, we wish to allow the possibility of a `NULL` value although they will often require extra handling (e.g., checking `if == NULL`).
|
||||
- In other cases, we want to prevent `NULL` from being entered as a value and specify `NOT NULL` as a **constraint** on data entry.
|
||||
- ### Atomic Attributes
|
||||
- What is an **atomic attribute**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:51:31.019Z
|
||||
card-last-reviewed:: 2022-11-14T16:51:31.019Z
|
||||
card-last-score:: 5
|
||||
- An **atomic attribute** is an attribute which contains a ^^single value of the appropriate type^^, generally meaning, "no repeating values of the same type".
|
||||
- The relational model should **only** have atomic values.
|
||||
- ### Composite Attributes
|
||||
- What is a **composite attribute**? #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:52:00.872Z
|
||||
card-last-reviewed:: 2022-11-14T16:52:00.872Z
|
||||
card-last-score:: 5
|
||||
- A **composite attribute** is an attribute that is composed of several atomic attributes.
|
||||
- E.g., `Name = FirstName, Middle Initial, Surname`.
|
||||
- We often want to decompose a composite attribute into atomic attributes unless there is a very good reason not to.
|
||||
- ### Multi-Valued Attributes
|
||||
- What is a **multi-valued attribute**? #card
|
||||
card-last-interval:: 4.14
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.56
|
||||
card-next-schedule:: 2022-11-26T16:37:36.766Z
|
||||
card-last-reviewed:: 2022-11-22T13:37:36.767Z
|
||||
card-last-score:: 5
|
||||
- A **multi-valued attribute** is an attribute which has lower and upper bounds on the number of values for an individual entry.
|
||||
- The ^^opposite of an atomic attribute.^^
|
||||
- The relational model should **not** store multi-valued attributes.
|
||||
- Database design / redesign should be used to deal with this issue by creating more attributes (columns) or more tables.
|
||||
- ### Derived Attributes
|
||||
- What are **derived attributes**? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-12T23:52:22.646Z
|
||||
card-last-reviewed:: 2022-11-14T16:52:22.646Z
|
||||
card-last-score:: 3
|
||||
- A **derived attribute** is an attribute whose value can be determined from another attribute.
|
||||
- E.g., you can derive age from birthdate.
|
||||
- It is a good idea to not directly store attribute which can be derived from other attributes.
|
||||
-
|
||||
- ## Collection of Relations
|
||||
- A Relational Data Model consists of a collection of relations (tables).
|
||||
- Tables are **cross-linked**.
|
||||
-
|
||||
- A relational database usually contains many relations (tables) rather than storing all data in one single relation.
|
||||
- What is a **Relational Schema**? #card
|
||||
card-last-interval:: 19.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.32
|
||||
card-next-schedule:: 2022-12-04T03:03:56.818Z
|
||||
card-last-reviewed:: 2022-11-14T20:03:56.818Z
|
||||
card-last-score:: 3
|
||||
- A **relational schema**, $R$, is the ^^definition of a **table** in the database.^^ It can be denoted by listing the table name and the attributes:
|
||||
- $$R=\{A_1,A_2,...,A_n\}$$
|
||||
- where $A_i$ is an attribute.
|
||||
- E.g., with $n=3$, `works_on(essn, pno, hours)`.
|
||||
- ## Linking Tables
|
||||
- Two ^^extremely important concepts^^ within the relational model which allows tables to be linked & cross-referenced are:
|
||||
- **Primary Key** attributes.
|
||||
- **Foreign Key** attributes.
|
||||
-
|
||||
- ### Primary Keys
|
||||
- Fundamental concept of **Primary Keys**: #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-11-17T15:34:03.291Z
|
||||
card-last-reviewed:: 2022-10-20T08:34:03.291Z
|
||||
card-last-score:: 5
|
||||
- ^^All tuples (rows) in a relation must be **distinct**.^^
|
||||
- To ensure this, we must have one or more attributes / columns whose data values will ^^always be unique for each tuple^^ - these attributes are called **key attributes** and are used to identify a tuple in the relation.
|
||||
- There may be a few possibilities for the **primary key** - these are called **Candidate Keys**.
|
||||
- One candidate key is ultimately chosen as the primary key during the Design Stage.
|
||||
- What is a **Primary Key**? #card
|
||||
card-last-interval:: 23.43
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-12-08T02:44:46.959Z
|
||||
card-last-reviewed:: 2022-11-14T16:44:46.960Z
|
||||
card-last-score:: 5
|
||||
- A **primary key** is defined as one or more attributes per table where:
|
||||
- there can only be one such primary key per table
|
||||
- the primary key can never contain the `NULL` value
|
||||
- all values entered for the primary key must be unique (no duplicates across the rows)
|
||||
- Often, primary keys are used as indices.
|
||||
- We use the convention (in writing) that attribute which form primary keys are $\text{\underline{underlined}}$.
|
||||
-
|
||||
- ### Foreign Keys
|
||||
- What is a **Foreign Key**? #card
|
||||
card-last-interval:: 23.43
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-12-08T02:52:18.585Z
|
||||
card-last-reviewed:: 2022-11-14T16:52:18.585Z
|
||||
card-last-score:: 3
|
||||
- A **Foreign Key** is an attribute, or a set of attributes, within one table that matches or **links to** a **candidate key** of some other table (possibly the same table).
|
||||
- More formally:
|
||||
- Given relations $r_1$ and $r_2$, a **foreign key** of $r_2$ is an attribute (or set of attributes) in $r_2$ where that attribute is a **candidate key** in $r_1$. Relations $r_1$ and $r_2$ may be the same relations.
|
||||
- #### Foreign Key Terminology
|
||||
- The **parent**, **master**, or **referenced** table is the relation containing the candidate key(s).
|
||||
- The **child** or **referencing** table / relation is the relation containing the foreign key.
|
||||
-
|
||||
92
year2/semester1/logseq-stuff/pages/Trees.md
Normal file
92
year2/semester1/logseq-stuff/pages/Trees.md
Normal file
@ -0,0 +1,92 @@
|
||||
- #[[MA284 - Discrete Mathematics]]
|
||||
- **Previous Topic:** [[Colouring Graphs; Eulerian & Hamiltonian Graphs]]
|
||||
- **Next Topic:** [[Matrices]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
- # Trees
|
||||
- What is an **acyclic graph** or a **forest**? #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-19T16:18:08.222Z
|
||||
card-last-reviewed:: 2022-11-16T21:18:08.222Z
|
||||
card-last-score:: 5
|
||||
- A graph that has no circuits is called **acyclic** or a "forest".
|
||||
- It is made up of **trees**.
|
||||
- What is a **tree**? #card
|
||||
card-last-interval:: 0.98
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-17T20:21:51.032Z
|
||||
card-last-reviewed:: 2022-11-16T21:21:51.032Z
|
||||
card-last-score:: 3
|
||||
- A **tree** is a connected, acyclic graph.
|
||||
- A graph is a tree if and only if there is a **unique path** between any two vertices.
|
||||
- If a graph has a unique path between pairs of vertices then it has no cycles, but there is a path between each pair, so it is connected.
|
||||
- A tree is a forest.
|
||||
- ## If $T$ is a tree, then $e = v - 1$. #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T09:45:56.481Z
|
||||
card-last-score:: 1
|
||||
- If $T$ is a tree (i.e., a connected acyclic graph) with $v$ vertices, then it has $v-1$ edges.
|
||||
- The converse of this statement is also true. ((6374e0df-7be4-4928-bf03-c336e517bbf9))
|
||||
- It can be difficult to determine if a very large graph is a tree just by inspection.
|
||||
- If we know that it has no cycles, then we need to verify that it is connected. The following result (the converse of the previous one) can be useful:
|
||||
- ## If $e = v-1$, then $T$ is a tree. #card
|
||||
id:: 6374e0df-7be4-4928-bf03-c336e517bbf9
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T09:46:20.887Z
|
||||
card-last-score:: 1
|
||||
- If a graph with $v$ vertices has no cycles, and has $e = v-1$ edges, then it is a tree.
|
||||
- ## Applications
|
||||
- What is a **Decision Tree**? #card
|
||||
card-last-interval:: 0.98
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.36
|
||||
card-next-schedule:: 2022-11-18T08:46:46.255Z
|
||||
card-last-reviewed:: 2022-11-17T09:46:46.255Z
|
||||
card-last-score:: 3
|
||||
- A **Decision Tree** is a graph where each node represents a possibility, and each branch/edge from that node is a possible outcome.
|
||||
- # Spanning Trees
|
||||
- What is a **Spanning Tree**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.5
|
||||
card-next-schedule:: 2022-11-18T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-17T09:47:19.672Z
|
||||
card-last-score:: 1
|
||||
- Given a (simple) graph $G$, a **spanning tree** of $G$ is a subgraph of $G$ that is a tree, and contains every vertex of $G$.
|
||||
- Lots of spanning trees are possible, and there are numerous ways of finding them. Here are two:
|
||||
- ## Algorithm 1
|
||||
- (i) Identify a cycle in the graph.
|
||||
(ii) Delete an edge in that cycle, taking care not to disconnect the graph.
|
||||
(iii) Keep going until all cycles have been removed.
|
||||
- ## Algorithm 2
|
||||
- (i) Start with just the vertices of the graph (no edges).
|
||||
(ii) Add an edge from the original graph, as long as it does not form a cycle.
|
||||
(iii) Stop when the graph is connected.
|
||||
- For many applications, we need to consider a wider class of graphs: **weighted graphs**.
|
||||
- ## Minimum Spanning Trees
|
||||
- What is a **minimum spanning tree**? #card
|
||||
card-last-interval:: 2.8
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.6
|
||||
card-next-schedule:: 2022-11-21T13:33:14.273Z
|
||||
card-last-reviewed:: 2022-11-18T18:33:14.274Z
|
||||
card-last-score:: 5
|
||||
- A **minimum spanning tree** is a spanning tree with the minimum possible total edge weight.
|
||||
- ### Kruskal's Algorithm
|
||||
- (i) Start with just the vertices.
|
||||
(ii) Add the edge with the least weight that does not form a cycle.
|
||||
(iii) Keep going until the graph is connected.
|
||||
- ### Prim's Algorithm
|
||||
- (i) Choose any vertex from the original graph.
|
||||
(ii) Add the edge incident to any vertex in the connected component with least weight that has the least weight and does not create a cycle.
|
||||
(iii) Stop when you reach all the vertices of the original graph.
|
||||
-
|
||||
248
year2/semester1/logseq-stuff/pages/Using R as a Calculator.md
Normal file
248
year2/semester1/logseq-stuff/pages/Using R as a Calculator.md
Normal file
@ -0,0 +1,248 @@
|
||||
title:: Using R as a Calculator
|
||||
|
||||
- #[[ST2001 Labs]]
|
||||
- **Previous Topic:** null
|
||||
- **Next Topic:** [[Describing Data in R]]
|
||||
- No relevant slides
|
||||
-
|
||||
- ## Basic Algebra in R
|
||||
- ### Addition #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:44:00.469Z
|
||||
card-last-reviewed:: 2022-11-14T16:44:00.470Z
|
||||
card-last-score:: 5
|
||||
- ```R
|
||||
# to add numbers in R, simply use "+"
|
||||
2+2
|
||||
```
|
||||
- Output:
|
||||
- ```R
|
||||
[1] 4
|
||||
```
|
||||
- ### Subtraction #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:44:48.506Z
|
||||
card-last-reviewed:: 2022-11-14T16:44:48.506Z
|
||||
card-last-score:: 5
|
||||
- ```R
|
||||
# to subtract numbers in R, simply use "-"
|
||||
4-2
|
||||
```
|
||||
- Output:
|
||||
- ```R
|
||||
[1] 2
|
||||
```
|
||||
- ### Multiplication #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:46:18.737Z
|
||||
card-last-reviewed:: 2022-11-14T16:46:18.738Z
|
||||
card-last-score:: 5
|
||||
- ```R
|
||||
# to multiply numbers in R, simply use "*"
|
||||
5*2
|
||||
```
|
||||
- Output:
|
||||
- ```R
|
||||
[1] 10
|
||||
```
|
||||
- ### Division #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-11-22T23:24:36.469Z
|
||||
card-last-reviewed:: 2022-10-20T08:24:36.470Z
|
||||
card-last-score:: 5
|
||||
- ```R
|
||||
# to divide numbers in R, simply use "/"
|
||||
10/5
|
||||
```
|
||||
- Output:
|
||||
- ```R
|
||||
[1] 2
|
||||
```
|
||||
- ### Exponents #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:51:39.910Z
|
||||
card-last-reviewed:: 2022-11-14T16:51:39.911Z
|
||||
card-last-score:: 5
|
||||
- ```R
|
||||
# use "^" to raise a number to a power
|
||||
3^2
|
||||
3^{-1} # use curly braces
|
||||
```
|
||||
- Output:
|
||||
- ```R
|
||||
[1] 9
|
||||
[1] 0.3333333
|
||||
```
|
||||
- ### Square Roots #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:37:35.704Z
|
||||
card-last-reviewed:: 2022-11-14T16:37:35.705Z
|
||||
card-last-score:: 5
|
||||
- ```R
|
||||
# use the function "sqrt()" to get the square root of a number in R
|
||||
sqrt(16)
|
||||
```
|
||||
- Output:
|
||||
- ```R
|
||||
[1] 4
|
||||
```
|
||||
-
|
||||
- ### Modulus #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:38:53.453Z
|
||||
card-last-reviewed:: 2022-11-14T16:38:53.454Z
|
||||
card-last-score:: 5
|
||||
- ```R
|
||||
# use "%%" to get the modulus
|
||||
19%%6
|
||||
```
|
||||
- Output:
|
||||
- ```R
|
||||
[1] 1
|
||||
```
|
||||
- ## Rounding in R
|
||||
- ### Absolute Value #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:44:02.326Z
|
||||
card-last-reviewed:: 2022-11-14T16:44:02.327Z
|
||||
card-last-score:: 5
|
||||
- ```R
|
||||
# use "abs()" to get absolute value in R
|
||||
abs(-1)
|
||||
```
|
||||
- Output:
|
||||
- ```R
|
||||
[1] 1
|
||||
```
|
||||
- ### Rounding #card
|
||||
card-last-interval:: 29.26
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T22:41:14.492Z
|
||||
card-last-reviewed:: 2022-11-14T16:41:14.492Z
|
||||
card-last-score:: 5
|
||||
- The function `round()` in R goes not necessarily do what you would expect when rounding numbers ending in **.5** - ^^it rounds to the nearest **even** number.^^
|
||||
- If you always round up numbers ending in .5, then you are causing an upwards bias.
|
||||
- The rounding to even numbers will tend to average out at a zero bias, as 50% go up and 50% go down.
|
||||
- ```R
|
||||
# use "round()" to round
|
||||
round(1.5)
|
||||
round(0.5)
|
||||
round(0.7)
|
||||
```
|
||||
- Output:
|
||||
- ```R
|
||||
[1] 2
|
||||
[1] 0
|
||||
[1] 1
|
||||
```
|
||||
- ## $\pi$ in R #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:38:10.483Z
|
||||
card-last-reviewed:: 2022-11-14T16:38:10.484Z
|
||||
card-last-score:: 5
|
||||
- ```R
|
||||
# to get pi in R, simply use the in-built constant "pi"
|
||||
pi
|
||||
```
|
||||
- Output:
|
||||
- ```R
|
||||
[1] 3.141593
|
||||
```
|
||||
- ## Trigonometric Functions in R
|
||||
- ### Sine in R #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-15T02:31:07.981Z
|
||||
card-last-reviewed:: 2022-11-11T11:31:07.981Z
|
||||
card-last-score:: 5
|
||||
- ```R
|
||||
# to get the sine of a number in R, use the function "sin()"
|
||||
sin(0.5 * pi)
|
||||
sin(pi)
|
||||
```
|
||||
- Output:
|
||||
- ```R
|
||||
[1] 1
|
||||
[1] 1.224647e-16
|
||||
```
|
||||
- ^^**Note:**^^ $1.224606e-16 \approx 0$. Due to the way computers store numbers, decimals are often slightly off, so $sine(\pi) \ne 0$ even though it should, of course, be equal to zero. Be careful of this!
|
||||
- ### Cosine in R #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:45:11.108Z
|
||||
card-last-reviewed:: 2022-11-14T16:45:11.109Z
|
||||
card-last-score:: 5
|
||||
- ```R
|
||||
# use "cos()" to get cosine
|
||||
cos(0)
|
||||
```
|
||||
- Output:
|
||||
- ```R
|
||||
[1] 1
|
||||
```
|
||||
- ### Tangent in R #card
|
||||
card-last-interval:: 33.64
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.9
|
||||
card-next-schedule:: 2022-12-18T07:51:39.012Z
|
||||
card-last-reviewed:: 2022-11-14T16:51:39.012Z
|
||||
card-last-score:: 5
|
||||
- ```R
|
||||
# use "tan()" to get tangent
|
||||
tan(0)
|
||||
```
|
||||
- Output:
|
||||
- ```R
|
||||
[1] 0
|
||||
```
|
||||
- ## Logarithms in R
|
||||
- ### Natural Log #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-07T19:44:02.657Z
|
||||
card-last-reviewed:: 2022-11-09T12:44:02.657Z
|
||||
card-last-score:: 3
|
||||
- ```R
|
||||
log(1)
|
||||
```
|
||||
- Output:
|
||||
- ```R`
|
||||
[1] 0
|
||||
```
|
||||
- ### Logs to a Given Base #card
|
||||
card-last-interval:: 4
|
||||
card-repeats:: 2
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-11-22T18:34:16.626Z
|
||||
card-last-reviewed:: 2022-11-18T18:34:16.626Z
|
||||
card-last-score:: 5
|
||||
- ```R
|
||||
# log<base>()
|
||||
log10(100)
|
||||
```
|
||||
- Output:
|
||||
- ```R
|
||||
[1] 2
|
||||
```
|
||||
102
year2/semester1/logseq-stuff/pages/Variables & Types.md
Normal file
102
year2/semester1/logseq-stuff/pages/Variables & Types.md
Normal file
@ -0,0 +1,102 @@
|
||||
- #[[CT2106 - Object-Oriented Programming]]
|
||||
- **Previous Topic:** [[More Java Code]]
|
||||
- **Next Topic:** [[OOP Modelling]]
|
||||
- **Relevant Slides:** 
|
||||
-
|
||||
-
|
||||
- A **variable** is a symbol used to store a value.
|
||||
- What is a **strongly typed** language? #card
|
||||
card-last-interval:: 28.3
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.66
|
||||
card-next-schedule:: 2022-12-13T03:06:20.887Z
|
||||
card-last-reviewed:: 2022-11-14T20:06:20.887Z
|
||||
card-last-score:: 5
|
||||
- In a **strongly typed** language, you have to tell the compiler / interpreter what **type** the variable is.
|
||||
- The compiler / interpreter knows how much space to allocate a variable of a certain type in memory.
|
||||
-
|
||||
- # Java Primitive Variables
|
||||
- 
|
||||
- ## Default Values
|
||||
- Each primitive variable has a **default value**.
|
||||
- The default value is used ^^only when the variable is used as a **field** (instance variable).^^
|
||||
- If the field is not explicitly assigned a value, the default value is used.
|
||||
- For example, the default value for an `int` variable is `0`.
|
||||
-
|
||||
- The "Code Pad" in BlueJ automatically initialises variables as if they were instance variables.
|
||||
- This will not happen in a true Java program, but it is useful for learning the default values.
|
||||
-
|
||||
- # Reference / Object Types
|
||||
- What is a **reference type**? #card
|
||||
card-last-interval:: -1
|
||||
card-repeats:: 1
|
||||
card-ease-factor:: 2.46
|
||||
card-next-schedule:: 2022-11-15T00:00:00.000Z
|
||||
card-last-reviewed:: 2022-11-14T16:46:32.338Z
|
||||
card-last-score:: 1
|
||||
- A **reference type** is a data type that's based on a class rather than on one of the primitive types that are built into the Java language.
|
||||
- There are 4 categories of reference type:
|
||||
- Object Types
|
||||
- Interface Types
|
||||
- Enum Types
|
||||
- Array Types
|
||||
- ## Null Default Value
|
||||
- The default value of all reference variables is `null`.
|
||||
- `null` is a special value in Java meaning "no object".
|
||||
- When you first declare a reference variable, its value is `null`.
|
||||
-
|
||||
- ### `NullPointerException`
|
||||
- One of the most common errors generated when running a Java program is `NullPointerException`.
|
||||
- This error is thrown when your program encounters a reference variable that has not been initialised.
|
||||
- This means that the variable points to its default value = `null`.
|
||||
- Your program then tries to get the object that the variable is pointing to do something, but the object doesn't exist, causing Java to generate a `NullPointerException`.
|
||||
-
|
||||
- ### Memory Leak
|
||||
- ```java
|
||||
Bicycle bike1; // bike1 points to null
|
||||
Bicycle bike2; // bike2 points to null
|
||||
|
||||
// bike1 & bile2 are assigned to point to the Bicycle objects just initialised
|
||||
bike1 = new Bicycle();
|
||||
bike2 = new Bicycle();
|
||||
|
||||
// bike1 & bike2 now both point to null again.
|
||||
bike1 = null;
|
||||
bike2 = null;
|
||||
```
|
||||
- What happens to the bicycle objects that were created but can no longer be referenced?
|
||||
- This is what's called a **memory leak**.
|
||||
- In this case, you have 2 objects occupying from memory, and you have not deallocated them from memory.
|
||||
- In fact, there is no way to deallocate them.
|
||||
-
|
||||
- #### Garbage Collector
|
||||
- The **Garbage Collector** is part of the JRE's memory management process.
|
||||
- It runs in the background keeping track of the live objects in a program, and marking the rest as garbage.
|
||||
- The data in these marked areas are subsequently deleted, freeing up memory.
|
||||
-
|
||||
- ## Object Reference Type
|
||||
- What is an **Object Reference Type**? #card
|
||||
card-last-interval:: 24.2
|
||||
card-repeats:: 4
|
||||
card-ease-factor:: 2.42
|
||||
card-next-schedule:: 2022-12-11T13:48:30.477Z
|
||||
card-last-reviewed:: 2022-11-17T09:48:30.477Z
|
||||
card-last-score:: 3
|
||||
- An **Object Reference Type** is a variable that ^^points to an object.^^
|
||||
- It is a **pointer**.
|
||||
- A primitive variable contains the value of that primitive type.
|
||||
- A variable can never contain an object, but it *can* contain a **pointer** to that object.
|
||||
- A reference variable ^^contains the value of the memory location of an object.^^
|
||||
- For example:
|
||||
- ```java
|
||||
Wheel wheel = new Wheel();
|
||||
```
|
||||
- The `wheel` variable contains the value of the memory location of the new Wheel object.
|
||||
- A reference variable does **not** contain the value of the object.
|
||||
-
|
||||
- # Test-Driven Development
|
||||
- **TTD** is an *incremental approach* to solving a problem.
|
||||
- Incrementally create Stub classes & Stub methods so that your code compiles & runs at all times.
|
||||
- To start with, it may run - but it might not do anything interesting.
|
||||
- Gradually, we add functionality - making sure that it compiles & runs.
|
||||
- We keep doing this until we achieve our minimum criteria for success.
|
||||
@ -0,0 +1,2 @@
|
||||
file:: [MA284-Week08_1666785726176_0.pdf](../assets/MA284-Week08_1666785726176_0.pdf)
|
||||
file-path:: ../assets/MA284-Week08_1666785726176_0.pdf
|
||||
Reference in New Issue
Block a user