13 KiB
13 KiB
- #CT230 - Database Systems I
- Previous Topic: Query Processing & Optimisation
- Next Topic:
- Relevant Slides:
- Generally, we can assume that for a non-trivial relational database that the entire database will not fit in the main memory (RAM).
- Note: Newer database system architectures, in-memory databases (such as SAP Hanna), manage their data through virtual memory, relying on the OS to manage the movement of data to & from the main memory through the OS paging mechanism.
- One of the DBMS's tasks is to manage the physical organisation (storage & retrieval) of the tuples (rows) in each table in the database.
- This is called File Organisation.
- What is File Organisation? #card
card-last-interval:: -1
card-repeats:: 1
card-ease-factor:: 2.5
card-next-schedule:: 2022-11-16T00:00:00.000Z
card-last-reviewed:: 2022-11-15T18:42:32.857Z
card-last-score:: 1
- A database file organisation is the way in which tuples from a table are physically arranged in secondary storage to facilitate the storage of data and read/write requests by users (via queries).
- A number of factors to consider, including:
- Support of fast access of data - moving to/from secondary storage.
- Cost.
- Efficient use of secondary storage space.
- Provision for table growth (when new tuples are added).
- What is a file? #card
card-last-interval:: -1
card-repeats:: 1
card-ease-factor:: 2.5
card-next-schedule:: 2022-11-16T00:00:00.000Z
card-last-reviewed:: 2022-11-15T18:42:28.412Z
card-last-score:: 1
- A file is a collection of data stored in bulk.
- In DBMS, we have referred to these files as tables or relations.
- In DBMS, we know that such tables contain a sequence of tuples, where each tuple contains a sequence of bytes and is subdivided into attributes or fields. Each attribute contains a specific piece of information. Associated with each attribute is a data type.
- In File Systems, we refer to these tuples as records containing fields.
-
Records
- Each recorder often begins with a header - a fixed-length region that stores information about the record such as:
- Pointer to the database schema.
- Length of the record.
- Timestamp indicating the time the record was last modified or read.
- Pointers to the fields of the record.
-
Size of records/tuples
- Fixed Length: All records (tuples) in a file (table) exactly the same size.
- Variable Length: Different records (tuples) in a file (table) have different size.
- Each recorder often begins with a header - a fixed-length region that stores information about the record such as:
-
File Organisation Issues
- How can these records be organised to store in a compact manner on devices of limited capacity and provide convenient & quick access by programs?
-
Blocks
- Different terminology is used but generally speaking a Block = a Frame = a Page, where records from a file are assigned to Blocks/Pages/Frames.
- Relational DBMS use the terminology of a block.
- Therefore, a table can also be defined as a collection of blocks where each block contains a collection of records.
- What is a block? #card
card-last-interval:: -1
card-repeats:: 1
card-ease-factor:: 2.5
card-next-schedule:: 2022-11-17T00:00:00.000Z
card-last-reviewed:: 2022-11-16T21:17:50.239Z
card-last-score:: 1
- A block is the unit of data transfer between secondary storage & memory.
- The block size
Bis fixed. - Records of a file must be allocated to blocks.
- Typically, the block size is larger than the record size, so each block will contain a number of records.
- Some files may have very large records that cannot fit in one block, so they span recrods over a number of blocks.
- A number of blocks is typically associated with a table.
- Blocks also have a header that holds information about the block such as:
- Links to one or more blocks associated with the table.
- Which table (in the schema) the blocks belong to.
- Timestamp of last access to block (read or write).
- What is the Blocking Factor? #card
card-last-interval:: -1
card-repeats:: 1
card-ease-factor:: 2.5
card-next-schedule:: 2022-11-18T00:00:00.000Z
card-last-reviewed:: 2022-11-17T09:46:11.528Z
card-last-score:: 1
- The Blocking Factor is the average number of records that fit per block.
- Given a block size
B(in bytes) and record sizeR(in bytes), then withB \geq R, we can fit\text{floor} \left( \frac{B}{R} \right)records per block. - We must ensure that the header information is also accounted for.
-
Example
- With unspanned memory organisation and
B = 1024 \text{ Bytes}(once header information is stored) andR = 100 \text{ Bytes (and of fixed length)}, the blocking factor is\text{floor} \left( \frac{1024}{100} \right) = 10.
- With unspanned memory organisation and
-
Spanned vs Unspanned Organisations
- In Spanned Organisation, records can span more than one block.
- In Unspanned Organisation, records are not allowed to cross block boundaries.
- So can only use when
B \geq R(i.e., when block size is greater than record size).
- So can only use when
-
Why use blocking?
- Say we need to retrieve a file with 1000 records.
- If not blocked, then we would need 1000 data transfers.
- If blocked with a blocking factor of 10, and records are stored one after another in blocks, then the same operation requires 100 data transfers.
- Say we need to retrieve a file with 1000 records.
- Different terminology is used but generally speaking a Block = a Frame = a Page, where records from a file are assigned to Blocks/Pages/Frames.
-
Operations Performed on a File
- All the operations that we have been performing with SQL code can be performed on a file:
- Scan or fetch all records.
- Search records that satisfy an equality condition (i.e., find specific records).
- Search records where a value in the record is within a certain range.
- Insert records.
- Delete records.
- All the operations that we have been performing with SQL code can be performed on a file:
-
Steps to Search for a Records on a Disk #card
card-last-interval:: -1 card-repeats:: 1 card-ease-factor:: 2.5 card-next-schedule:: 2022-11-18T00:00:00.000Z card-last-reviewed:: 2022-11-17T09:45:33.206Z card-last-score:: 1-
- Locate the relevant blocks.
- Move these blocks to main memory buffers.
- Search through block(s) looking for the required records.
- At worst (the worst case), we may have to retrieve and check through all the blocks for the record.
- Generally, when accessing records, to support record-level operations we must:
- Keep track of the blocks associated with a file.
- Keep track of the free space on the blocks.
- Keep track of the records on a block.
-
-
Options for Organising Records
- Heap file organisation (unordered).
- Sequential file organisation (ordered).
- Hashing/hashed file organisation.
- Indexed file organisation (Primary, Clustered, B-Trees, B+ Trees).
-
Heap File Organisation #card
card-last-interval:: -1 card-repeats:: 1 card-ease-factor:: 2.5 card-next-schedule:: 2022-11-18T00:00:00.000Z card-last-reviewed:: 2022-11-17T09:46:39.719Z card-last-score:: 1- Approach: Any record can be placed in any block where there is space for the record (no ordering of records).
- Insertion: The last disk block associated with the file (table) is copied into the buffer and the record is added; the block copied back to disk.
- Searching: Must search all blocks (linear search).
- Deletion: Find the block with the record (linear search); delete the link to the record.
-
Advantages
- Insertion is efficient & easy - the last disk block is copied into the buffer and the record is added; the block is copied back to the disk.
-
Disadvantages
- Searching is inefficient - must search all blocks (linear search).
- Deleting is inefficient - search first; delete and then leave unused space in the block if using the "easy" insert approach.
-
Sequential File Organisation #card
card-last-interval:: 0.98 card-repeats:: 1 card-ease-factor:: 2.36 card-next-schedule:: 2022-11-18T08:45:18.181Z card-last-reviewed:: 2022-11-17T09:45:18.183Z card-last-score:: 3- Approach: Records are stored in sequential order, based on the value of some key of each record - often the primary key.
- We usually use an index with sequential file organisation.
- Sequential File Organisation allows records to be read in sorted order.
-
Advantages
- Reading records in order is efficient.
- Searching is efficient on the key field (binary search).
- Easy to find the "next record".
-
Disadvantages
- Insertion & deletion is expensive as records must remain physically ordered.
- Pointer chains are used (part of the header information).
- Searching is inefficient on a non-key field.
- Insertion & deletion is expensive as records must remain physically ordered.
-
Hashing / Hashed File Organisation #card
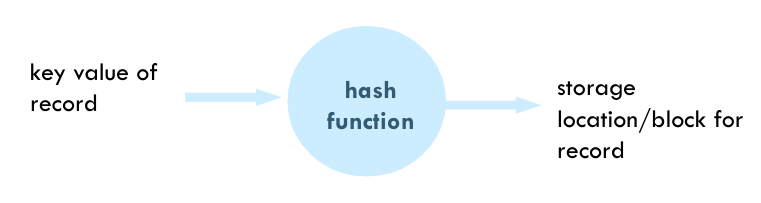
card-last-interval:: -1 card-repeats:: 1 card-ease-factor:: 2.5 card-next-schedule:: 2022-11-17T00:00:00.000Z card-last-reviewed:: 2022-11-16T21:17:57.726Z card-last-score:: 1- A hash function is computed on some attributes of each record (often a key value).
- The output of the hash function is the block address where the record should be placed.
-
Hash Functions
- A common hash function is the
MODor modulus function wherea MOD bora % breturns the remainder on dividingabyb, i.e. integer division.
- A common hash function is the
-
Criteria for Choosing the Hash Function
- Should be easy & quick to compute.
- Should uniformly distribute hash addresses across the available space.
- Picking a prime number for the mod function helps with this, but cannot guarantee it.
- Should anticipate file growth (insertions & deletions) so that only a fraction of each block is initially filled, thus leaving room to insert new records.
-
Collisions
- However, at any stage, two or more key field values can hash to the same location.
- If there is no room to place a record, this is called a collision.
- If a collision occurs, and there is no space in the block for a new record, then the record must find a new location.
- This is called collision resolution.
- One approach to collision resolution is Linear Probing.
- Hash function returns block location
ifor the record. - If there is no room in block
i, check blocki+1,i+2, etc. until a block with room is found.
- Hash function returns block location
- However, at any stage, two or more key field values can hash to the same location.
-
Indexed File Organisation #card
card-last-interval:: -1 card-repeats:: 1 card-ease-factor:: 2.5 card-next-schedule:: 2022-11-18T00:00:00.000Z card-last-reviewed:: 2022-11-17T09:46:30.122Z card-last-score:: 1- Indexing speeds up operations that are not efficiently supported by the basic file organisation.
- Consists of index entries.
- Each index entry consists of:
- Index key.
- Record or block pointer.
- The index entries are placed on the disk, either in sequential sorted order (ordered indices) or hashed order.
- A complete index may be able to reside in main memory.
-
To Access a Record Using Indexing Key
-
- Retrieve the index file.
- Search through it for the required field (based on the index key value).
- Answer the query or return to secondary storage for the block which contains the required record.
-
-
Dense vs Sparse Indices #card
card-last-interval:: -1 card-repeats:: 1 card-ease-factor:: 2.5 card-next-schedule:: 2022-11-17T00:00:00.000Z card-last-reviewed:: 2022-11-16T21:17:44.546Z card-last-score:: 1- An index is dense if it contains an entry for every record in the file.
- A dense index may be created for any index key.
- A sparse (or non-dense) index contains an entry for each block rather than an entry for every record in the file.
- Sparse indices can only be used if the records are assigned to blocks in sorted (sequential) order based on the primary index key.
- A sparse index is called a primary index.
- An index is dense if it contains an entry for every record in the file.
-
More on Primary Indices
- The total number of entries in a primary index is the same as the total number of blocks in the ordered file.
- The first record in each block is called the anchor record of the block.
-
Advantages
- Fewer index entries than records, so the index file is smaller.
-
Disadvantages
- Insertions & deletions are a problem - may have to change anchor record.
- Searching may take longer.
-
Clustered & Secondary Indices #card
card-last-interval:: -1 card-repeats:: 1 card-ease-factor:: 2.5 card-next-schedule:: 2022-11-18T00:00:00.000Z card-last-reviewed:: 2022-11-17T09:46:03.592Z card-last-score:: 1- Records that are logically related are physically stored close together on the disk (i.e., in the same blocks or consecutive blocks).
- Records are physically ordered on a non-key field that does not have a distinct value for each record.
- The clustering index consists of:
- A clustering field value.
- A block pointer to the first block that has a record with that value for the clustering field.

